はじめに
HTML内のあるElementの子要素を列挙する必要があり関数を作成してみました。
直ぐに書けたのは、再帰を使った深さ優先探索の関数でした。
これで問題はないのですが、ついつい再帰で作ってしまうので勉強のためにとループ版も考えてみることにしました。
更に、どうせならばと幅優先探索のものも作成してみました。
ここまでやったのならば探索アルゴリズムが学習材料として定番なので簡単な記事にしてみることにしました。
なお、この記事の全てのプログラムは、babelなどトランスコンパイラを使用することを前提としたJavaScriptで実装しています。
簡単な説明
深さ優先探索
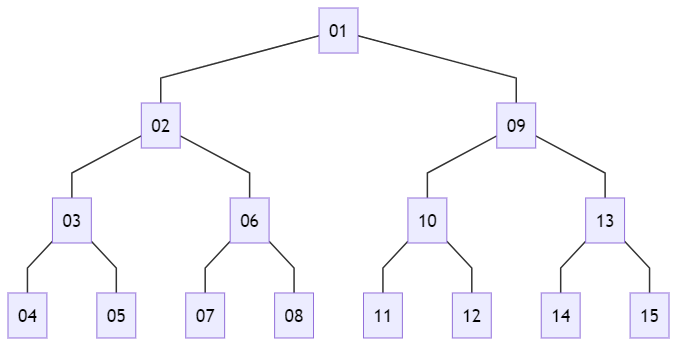
上のようなグラフがあった場合、図に表される数字の順番で探索する方法です。
正確に言えば、前順(pre-order)の深さ優先探索の場合です。
この図からはわかりづらい上に適切な表現ではないかもしれませんが、データの出現順で探索されます。
出現順と思うのは、世に出ている階層構造の表現方法が深さ優先探索を用いているからかもしれません。
親子関係がわかりやすい利点があります。
特に直近の親子関係が分かりやすいです。
簡単にアルゴリズムを説明すると、子がなくなるまで探索していき、子がなくなったら以前の探索した節点に戻るといった処理を繰り返して探索をしてきます。
探索済みの節点や、次に探索すべき節点の制御に、スタックを用いて実装される事が多いです。
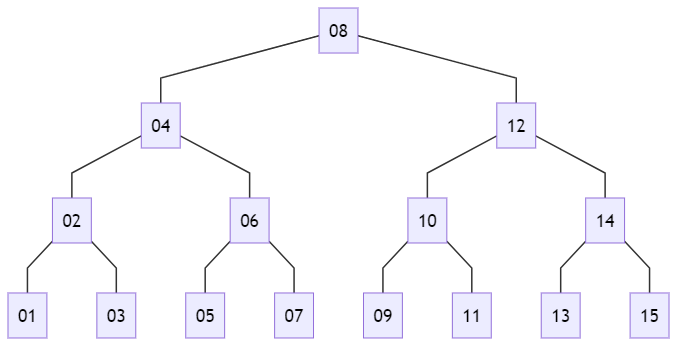
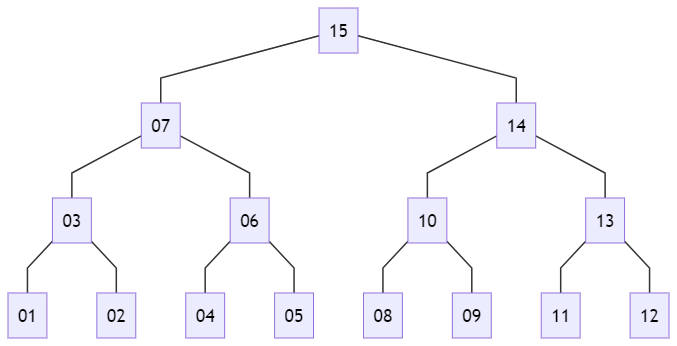
そのほか深さ優先探索には、以下のように間順(in-order)と後順(post-order)があります。
前順、間順、後順の結果が異なるのは、探索する順番が異なるのではなくて探索済みとするタイミングが異なるからです。
前順の場合は、探索節点になった(子の有無を調べている)段階で探索済みになります。
間順の場合は、左側(右側)の子要素がすべて探索済みになった場合に、その接点が探索済みになります。
後順の場合は、子要素がすべて探索済みになった場合に、その接点が探索済みになります。
なお、この記事では、前順のものしか扱いません。
幅優先探索
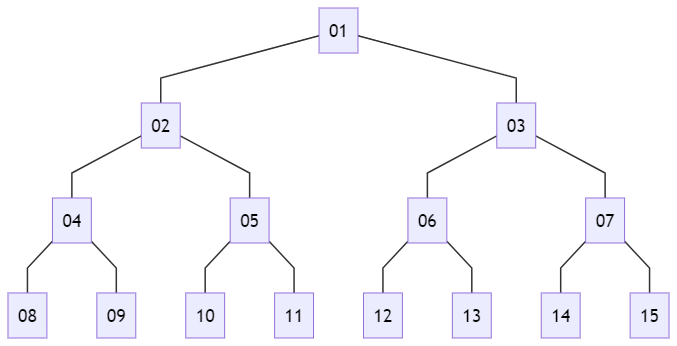
上のようなグラフがあった場合、図に表される数字の順番で探索する方法です。
階層ごとに探索されるので、同じ階層のデータがまとまって探索されます。
その一方で、親子関係が分かりづらくなるという面もあります。
こちらも簡単にアルゴリズムの説明をすると、ある節点の子をすべて探索し、次に探索済みの接点の子をすべて探索するといった処理を繰り返して探索していきます。
こちらは、探索済みの節点や、次に探索すべき節点の制御に、キューを用いて実装される事が多いです。
実装
HTMLのElementの子要素を列挙する形で実装しました。
テストデータとして以下のようなElementを作成しておきます。
分かりやすくするために、タグ名に変な名前を使っています。
<div0>
<span01></span01>
<div1>
<span11></span11>
<div2>
<span21></span21>
<span22></span22>
</div2>
<span12></span12>
</div1>
<div3>
<span31></span31>
<div4>
<span41></span41>
<span42></span42>
</div4>
<span32></span32>
</div3>
<span02></span02>
</div0>
let result = [];
const div0 = document.createElement("div0");
div0.insertAdjacentHTML("beforeend", '<span01></span01><div1><span11></span11><div2><span21></span21><span22></span22></div2><span12></span12></div1><div3><span31></span31><div4><span41></span41><span42></span42></div4><span32></span32></div3><span02></span02>');
再帰版
初めに再帰で実装してみました。
深さ優先探索
深さ優先探索は、以下のように実装しました。
再帰呼び出しの挙動は、スタックの挙動そのままです。
そのため、関数の呼び出し制御自体が、探索節点の制御につながっています。
見つかった子要素を探索済みの配列resultに入れて、その要素を引数にして自分自身を呼び出す形で探索を続けます。
/**
* 深さ優先探索でelementの全ての子要素をresultに格納する
* @param {Element} element : 要素を列挙したいElement
* @param {Array} result : 結果を格納する空配列
*/
function getAllChildNodesDepth(element, result) {
if (element.childNodes.length !== 0) {
element.childNodes.forEach((child) => {
result.push(child);
getAllChildNodesDepth(child, result);
});
}
}
result = [];
getAllChildNodesDepth(div0, result);
console.log(result);
実行結果
[span01, div1, span11, div2, span21, span22, span12, div3, span31, div4, span41, span42, span32, span02, ]
幅優先探索
幅優先探索は、以下のように実装しました。
こちらは、キューとは無関係な実装になっています。
探索節点の子要素をすべて探索済み配列resultに格納しつつ、その呼び出しで見つかった子要素を使って次の関数を呼び出す形になっています。
引数elementsは、配列です。
呼び出す場合は、根の要素を1つだけ渡すのですが、それを1つだけ配列に入れて渡す必要があります。
/**
* 幅優先探索でelementの全ての子要素をresultに格納する
* @param {Element[]} elements : 要素を列挙したいElementの入った配列
* @param {Array} result : 結果を格納する空配列
*/
function getAllChildNodesBreath(elements, result) {
const work = [];
elements.forEach((element) => {
result.push(...element.childNodes);
work.push(...element.childNodes);
});
if (work.length !== 0) {
getAllChildNodesBreath(work, result);
}
}
result = [];
getAllChildNodesBreath([div0], result);
console.log(result);
実行結果
[span01, div1, div3, span02, span11, div2, span12, span31, div4, span32, span21, span22, span41, span42, ]
ループ版
始めは、それぞれ別の関数として実装していました。
比べてみると探索すべき要素の順番以外は、全く同じ構造で良いと分かったので1つに統合することにしました。
結果から受ける印象と違い、プログラム的には、探索節点の保存方法つまりスタックを使うかキューを使うかの違いしかないようです。
簡単に説明すると以下のようになります。
- 始めに、根の全ての子要素を次に探索すべき要素としてキューに保存します。
ここでそれぞれスタックとキューに分けても良いのですが結果は変わらないのでキューに統一しました。 - スタックの頭もしくはキューの先頭から取り出した要素を探索済みとしてresultに保存します。
- 探索済みの要素の全ての子要素を次に探索すべき要素として1つずつスタックまたはキューに保存します。
- 全ての要素が探索済みになる(スタックまたはキューが空になる)まで2~3を繰り返す。
探索済みの要素が格納されている配列resultを返します。
スタックとキューを実現するためにそれぞれ関数を作成して使用しています。
/**
* 配列をスタックと見立ててdataの要素を格納する
* @param {array-like|iterable} data : スタックに格納したいデータ
* @param {Array} stack : 要素を格納する配列
*/
function push(data, stack) {
const array = Array.from(data).reverse();
if (array.length !== 0) {
array.forEach((node) => {
stack.push(node);
});
}
}
/**
* 配列をキューと見立ててdataの要素を格納する
* @param {array-like|iterable} data : キューに格納したいデータ
* @param {Array} queue : 要素を格納する配列
*/
function enqueue(data, queue) {
const array = Array.from(data);
if (array.length !== 0) {
array.forEach((node) => {
queue.unshift(node);
});
}
}
/**
* elementの全ての子要素を返す
* @param {Element} element : 要素を列挙したいElement
* @param {Array} result : 結果を格納する空配列
* @param {boolean} [depth = ture] : 深さ優先探索の場合は、ture。幅優先探索の場合は、false
* @return {Element[]} : 全ての子要素
*/
function getAllChildNodesLoop(element, depth = true) {
const result = [];
const target = [];
let child = null;
enqueue(element.childNodes, target);
while (target.length !== 0) {
child = target.pop();
result.push(child);
if (depth) {
push(child.childNodes, target);
} else {
enqueue(child.childNodes, target);
}
}
return result;
}
result = getAllChildNodesLoop(div0, true);
console.log(result);
result = getAllChildNodesLoop(div0, false);
console.log(result);
[span01, div1, span11, div2, span21, span22, span12, div3, span31, div4, span41, span42, span32, span02, ]
[span01, div1, div3, span02, span11, div2, span12, span31, div4, span32, span21, span22, span41, span42, ]
最後に
余談になりますが、初めて勉強したときに見せられたものが間順の深さ優先探索だったと思います。
この探索順には、感覚的に違和感を感じてしまいました。
そのため、探索には、全て幅優先探索を使おうと短絡的に思ってしまいました。
もっとも直ぐに幅優先探索では、親子関係が分かりづらいと気が付かされることになります。
結局、適切な方法を選ぶのが大切なんだなと思った次第です。
そして今回作ったものの中で実際に使うのは、深さ優先探索になると思います。
データの定義順に探索してくれる点が扱いやすいという理由です。
若いころの直感などまるで役に立たないのかもしれません。(´・ω・`)
プログラムを載せてしまうと言葉で説明するよりコードを見てもらった方がよほど分かりやすいのではと思ってしまいます。
そのため言葉での説明が大雑把になりがちです。
こういうところは直した方が良いとは思うのですがなかなか治らないものです。
と毎回のように書くような気がします。(´・ω・`)
mermaid
深さ優先探索前順
深さ優先探索間順
深さ優先探索後順
幅優先探索