疑問
NumPy のテンソル ndarray はconcatenateやstackを用いて結合することができます。 ここで、テンソルを随時生成してそれらを結合した新しいテンソルを求めたいと思ったとき、
- 一度リストに放り込んでから最後にまとめて結合するのか、
- 生成したテンソルを順次結合していくのか、
どちらが早いでしょうか。普通に考えれば一気に結合したほうが早そうな気はしますが、リストはなんか遅いというイメージもあります。 どっから生まれたイメージなんだコレ。
では、実験してみましょう。
大量生成のコード
以下のコードをnumを 5000 ずつ増加させてその実行時間を比較してみます。
from typing import List
import datetime
import random
import time
import numpy as np
num = 5000
def listing(num: int) -> np.ndarray:
random.seed(0)
arr_list: List[np.ndarray] = []
for i in range(num):
rand1: List[List[float]] = []
for i in range(3):
rand1.append([random.random(), random.random(), random.random(),])
now_arr = np.asarray(rand1)
arr_list.append(now_arr[np.newaxis, ...])
return np.vstack(arr_list)
def stacking(num: int) -> np.ndarray:
random.seed(0)
rand2: List[List[float]] = []
for i in range(3):
rand2.append([random.random(), random.random(), random.random(),])
ret_arr = np.asarray(rand2)[np.newaxis, ...]
for i in range(num - 1):
rand3: List[List[float]] = []
for i in range(3):
rand3.append([random.random(), random.random(), random.random(),])
now_arr = np.asarray(rand3)
ret_arr = np.vstack((ret_arr,now_arr[np.newaxis, ...],))
return ret_arr
list_start_time = time.time()
list_arr = listing(num)
list_end_time = time.time()
list_elapsed_time = list_end_time - list_start_time
stack_start_time = time.time()
stack_arr = stacking(num)
stack_end_time = time.time()
stack_elapsed_time = stack_end_time - stack_start_time
print('list time: ' + str(datetime.timedelta(seconds=list_elapsed_time)))
print('stack time: ' + str(datetime.timedelta(seconds=stack_elapsed_time)))
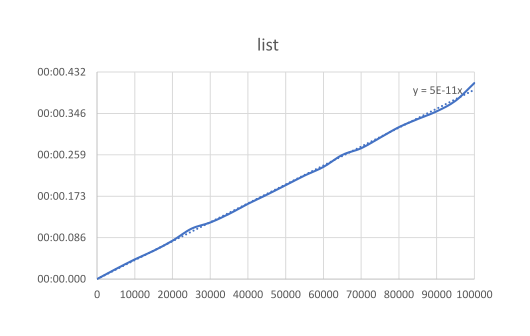
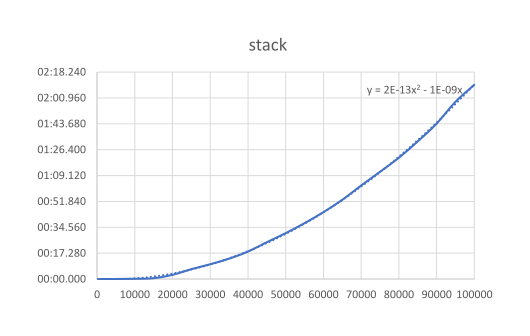
結果は以下のようになります。 やはり一度に結合したほうが早いようですね。 みてのとうりよね。
| list | stack | |
|---|---|---|
| 5000 | 00:00.021 | 00:00.068 |
| 10000 | 00:00.041 | 00:00.186 |
| 15000 | 00:00.059 | 00:00.618 |
| 20000 | 00:00.080 | 00:02.843 |
| 25000 | 00:00.105 | 00:06.640 |
| 30000 | 00:00.118 | 00:09.918 |
| 35000 | 00:00.136 | 00:13.639 |
| 40000 | 00:00.157 | 00:18.389 |
| 45000 | 00:00.176 | 00:24.626 |
| 50000 | 00:00.196 | 00:30.691 |
| 55000 | 00:00.216 | 00:37.342 |
| 60000 | 00:00.234 | 00:44.673 |
| 65000 | 00:00.259 | 00:52.917 |
| 70000 | 00:00.273 | 01:02.477 |
| 75000 | 00:00.295 | 01:11.633 |
| 80000 | 00:00.317 | 01:21.016 |
| 85000 | 00:00.334 | 01:31.909 |
| 90000 | 00:00.350 | 01:43.772 |
| 95000 | 00:00.372 | 01:58.346 |
| 100000 | 00:00.409 | 02:09.706 |
一度に結合する方は処理時間が線形に増加するのに対し、都度結合では 2 乗に比例しているように見えます。 オーダの観点からは、生成数が多くなればなるほど、都度結合が不利になっていきます。
少量生成のコード
では、生成数が少ない場合はどうでしょう。 numは 3 回に抑え、それを 100000 回繰り返して時間を計測してみます。
# 前略
times = 100000
list_start_time = time.time()
for i in range(times):
list_arr = listing(num)
list_end_time = time.time()
list_elapsed_time = list_end_time - list_start_time
stack_start_time = time.time()
for i in range(times):
stack_arr = stacking(num)
stack_end_time = time.time()
stack_elapsed_time = stack_end_time - stack_start_time
print('list time: ' + str(datetime.timedelta(seconds=list_elapsed_time)))
print('stack time: ' + str(datetime.timedelta(seconds=stack_elapsed_time)))
# list time: 0:00:02.036575
# stack time: 0:00:02.294834
この場合では、先程ほど差は露骨ではありませんが、やはり一度に結合したほうが若干早いですね。
まとめ
いかがでしたか???????????????? というお決まりのフレーズは置いておいて、リストが遅いっぽいイメージとは関係なくリストに放り込んでから一度に結合したほうがやっぱり早いです。
考えてみれば、リストが遅そうなのは途中に挿入されたりとかしたときにインデックスたどるのが云々みたいな話が大本な気がするので速攻で消費するなら別に問題ない気もしますね。
とはいえ、私は Python や NumPy に関しては初心者もいいところなので、こういう場合のより良いプラクティスがありそうな気はします。