はじめに
ChatGPTが昨今注目を集めており、関連ニュースを数多く見かけるようになりました。
筆者自身はGPT-2のころから、手元PC環境で試していたのですが、、、言語モデルのサイズが大きいと大変。
でも、どうしても話題のGPT言語モデル12を試してみたく、複数回に分けてその過程を紹介してゆきます。
本稿は、1本目です。
- 1本目:汎用GPT言語モデル ★本稿
- 2本目:対話GPT言語モデル
- 3本目:強化学習済み対話GPT言語モデル
本稿で紹介すること
以下、手元PC環境(Windows11)に施してゆきます。
- PyTorch入りのコンテナイメージの起動
- Pythonライブラリのインストール
- GPT言語モデルでの文章生成
筆者は、Windows 11のホスト上でWSL2/Ubuntuを起動しています。
更に、UbuntuでDockerコンテナを起動しています。
一応、GPUカード(NVIDIA GeForce GTX 1660 SUPER)が搭載されています。
- Windows 11 Ver.22H2 (Build. 23424.1000)
- WSL 1.2.5.0
- Ubuntu 20.04.5 LTS
- NVIDIA グラフィックスドライバー v532.03
参考記事
以下の記事を見て、手元PCで進めてゆきます。
PyTorch入りのコンテナイメージの起動
過去の記事でも利用しましたが、NGC CATALOGのコンテナイメージを利用します。
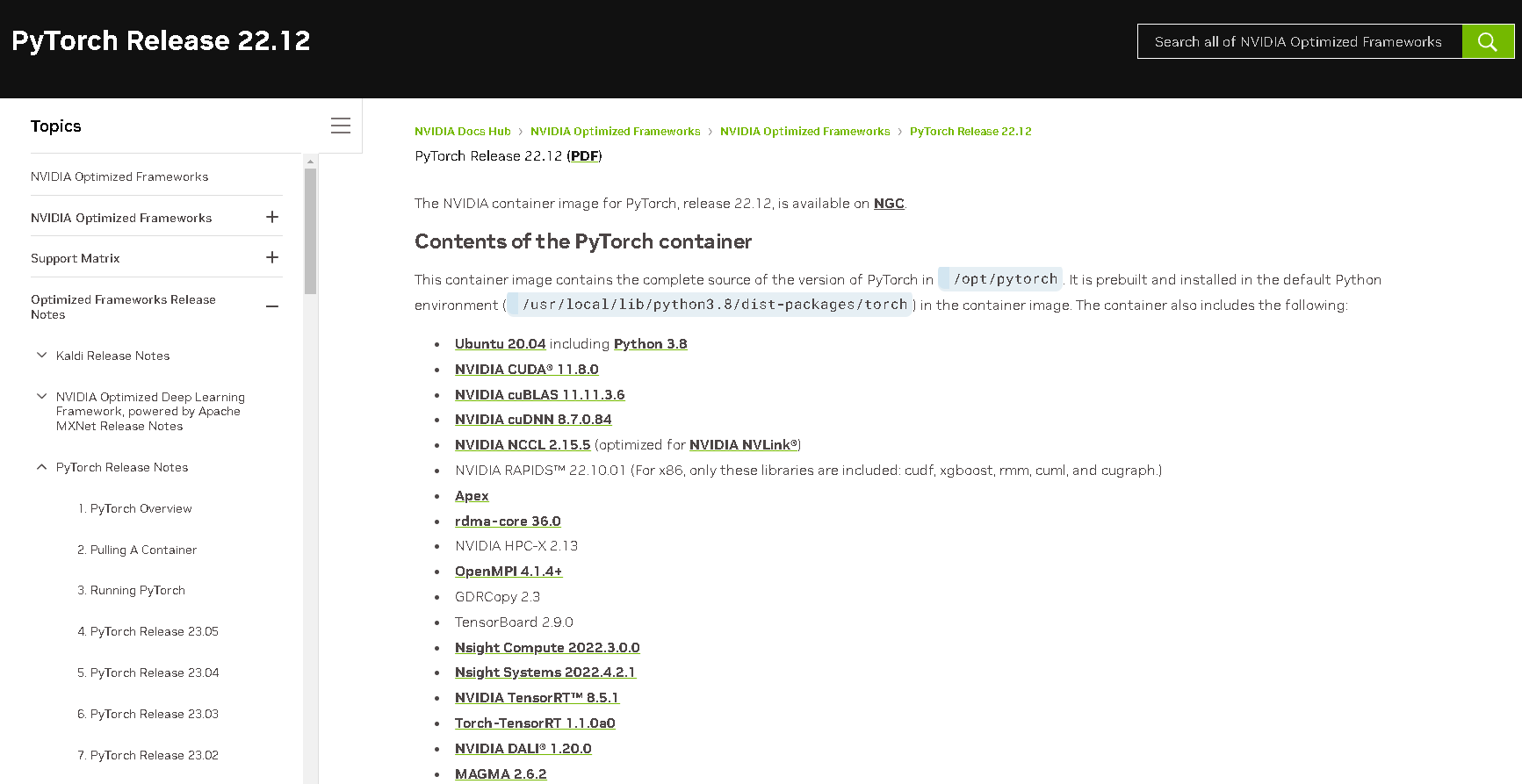
コンテナイメージのソフトウェアスタック詳細説明は、本家34に委ねるとして、ざっくり以下が含まれます。
- Ubuntu 20.04.5 LTS
- Python 3.8.10
- CUDA Toolkit v11.8.89
- torch 1.14.0a0+410ce96
まずは、以下コマンドを実行して、コンテナイメージをDownload(取得)します。
$ docker pull nvcr.io/nvidia/pytorch:22.12-py3
そして、Downloadを終えたら、以下コマンドでコンテナを起動します。
$ docker run -d -it --name gpt -e GRAND_SUDO=yes -v /home/ubuntu/workspace:/workspace/local nvcr.io/nvidia/pytorch:22.12-py3
更に、コンテナが起動したら、以下コマンドでコンテナに接続します。
$ docker exec -it gpt /bin/bash
Pythonライブラリのインストール
では、PythonのVer.とPIPのVer.を確認します。
# python -V
Python 3.8.10
# python -m pip --version
pip 21.2.4 from /usr/local/lib/python3.8/dist-packages/pip (python 3.8)
GPT言語モデルの実行に必要な、Pythonライブラリをインストールします。
# python -m pip install transformers sentencepiece accelerate
GPT言語モデルでの文章生成
rinna社が公開中の汎用GPT言語モデル5の動作サンプル(以下)をベースにしています。

import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b")
if torch.cuda.is_available():
model = model.to("cuda")
text = "西田幾多郎は、"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=100,
min_new_tokens=100,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
動作サンプルを筆者の手元PC環境でそのまま実行すると、以下のErrorが発生します。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 122.00 MiB (GPU 0; 6.00 GiB total capacity; 5.26 GiB already allocated; 0 bytes free; 5.31 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
・・・GPUメモリ量が潤沢ではないので、メモリ不足に陥っているようです。
そのため、以下のようなCodeで予定通り(?)にCPU指定で実行します。
import logging
# インスタンスの作成
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
# "example.log"を出力先とするファイルハンドラ作成
ch = logging.FileHandler(filename="debug.log")
#DEBUGレベルまで見る
ch.setLevel(logging.DEBUG)
# ログの記述フォーマット
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# ファイルハンドラにフォーマット情報を与える
ch.setFormatter(formatter)
# logger(インスタンス)にファイルハンドラの情報を与える
logger.addHandler(ch)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
try:
tokenizer = AutoTokenizer.from_pretrained("japanese-gpt-neox-3.6b", use_fast=False)
logger.debug('tokenizer')
model = AutoModelForCausalLM.from_pretrained("japanese-gpt-neox-3.6b").to("cpu") # CPU指定
logger.debug('model')
text = "となりのトトロは、スタジオジブリ制作の長編アニメーション映画。"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=500,
min_new_tokens=500,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
logger.debug(output)
except Exception as e:
logger.debug(e)
お待ちかね、プログラムを実行してみます。
※見やすいように、筆者が改行を挿入しています。
# python rinna.py
となりのトトロは、スタジオジブリ制作の長編アニメーション映画。宮崎駿監督が原作・脚本・監督を務める。
昭和30年代前半の田舎の田園風景、昭和30年代の日本の社会を丁寧に描いた作品。都会から田舎の宮崎の山間の
村に引っ越してきたサツキとメイの父が、庭の草刈りをするシーンは、懐かしくなり、子供の頃を思い出す。
トトロが住んでいる不思議な森の世界は、小さな子どもたちが、心地よい不思議の世界で、楽しい冒険や、
友情・勇気・努力・感動の物語を体験できる。また、メイのママは、トトロにメイを守ってほしいと頼む。
トトロは優しい心を持った不思議な存在で、メイのママは、トトロに守られたのかもしれない。大人になっても
ジブリ映画は、懐かしく、楽しく、また見たいと思わせてくれる。
映画「となりのトトロ」は、昭和30年代後半の埼玉県所沢市が舞台。田舎の山間には、不思議な、古い自然の
緑豊かな森があり、その中に一軒の古びた屋敷がある。その屋敷の裏の斜面には、木の根元に、木陰で休む
不思議な生き物が住んでいて、メイが庭で遊んでいると、いつも目の前を横切る。隣の家には、サツキとメイ
のお母さんが住む。そのサツキとメイの二人は、トトロを目撃する。 トトロは、空を飛ぶ不思議な生き物だが、
メイと、その近所の人たちとの出会いと、その不思議な森での暮らしが、とても温かく、懐かしく、ほのぼの
とした。トトロと一緒に暮らしたいが、トトロがお腹を空かしていると困るので、遠慮しておく。映画の後半、
山へ遊びに行って、サツキとメイの父が草刈りを忘れて、山の中で迷ってしまい、メイは、メイおばあちゃんに、
トトロに助けてとお願いする。トトロは、サツキとメイを助けにいく。その時のサツキとメイの後ろ姿の可愛さ
に、トトロに助けられた二人は、トトロが可愛くて仕方がない。そして、メイがサツキに、トトロをお母さんの
ように、おじいちゃんのように、妹のように、お姉さんのように、お母さんのように、お父さんのように、
トトロを頼
ざっくり前半は、映画の紹介文としてあまり違和感のない仕上がりの印象。
一方、後半は、そんなストーリーだったか?とちょっと首をかしげる仕上がりの印象。
一応、Wikipediaでのストーリー概要6は以下の記載でした。
ストーリー
昭和30年代前半の初夏 (5月[8][注 4]) 。小学生のサツキと、幼い妹のメイ、父の三人が、入院中の母の病院の近くであり、空気のきれいな所で暮らすため、農村へ引っ越してくる。引越し先の古い家を探検していたサツキとメイは、ピンポン球程の真っ黒なかたまりがたくさん住み着いているのを見つける。驚いた二人に対し、引っ越しの手伝いに来ていた隣のおばあちゃんが、それはススワタリというもので、子供にしか見えず、害もなく、人が住み始めるといつの間にかいなくなるのだと教えてくれる。おばあちゃんの孫のカンタが差し入れをもってくるが、カンタは「お化け屋敷」とさつきをからかう。この家で三人は新しい生活を始める
補足
筆者は、データ永続化のため、コンテナ起動時に永続ボリュームを割り当てています。
コンテナ内で「/workspace/local/」のパスは、コンテナ実行HostのUbuntu(on WSL)を参照した状態です。
root@6632133b5e52:/workspace/local/gpt# pwd
/workspace/local/gpt
root@6632133b5e52:/workspace/local/gpt# ll
total 44
drwxrwxr-x 4 1000 1000 4096 Jun 11 05:45 ./
drwxr-xr-x 5 1000 1000 4096 Jun 8 14:49 ../
drwxr-xr-x 2 root root 4096 Jun 11 01:42 japanese-gpt-neox-3.6b/
-rwxrwxr-x 1 root root 2330 Jun 11 02:39 rinna.py*
まとめ
本稿ではrinna社が公開中の汎用GPT言語モデルを使って、文章を生成しました。
Inputの与え方でOutputの出来は変わってくる印象ですが、事実か否かはともあれ流暢な日本語文章が生成されており、素直に驚きです。
とりあえずは、もっと高性能なGPUカードが欲しい。。。
-
rinna、日本語に特化した36億パラメータのGPT言語モデルを公開 | https://rinna.co.jp/news/2023/05/20230507.html ↩
-
rinna、人間の評価を利用したGPT言語モデルの強化学習に成功 | https://rinna.co.jp/news/2023/05/20220531.html ↩
-
PyTorch | NVIDIA NGC | https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch ↩
-
PyTorch Release 22.12 - NVIDIA Docs | https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html ↩
-
rinna/japanese-gpt-neox-3.6b | https://huggingface.co/rinna/japanese-gpt-neox-3.6b ↩
-
となりのトトロ | https://ja.wikipedia.org/wiki/%E3%81%A8%E3%81%AA%E3%82%8A%E3%81%AE%E3%83%88%E3%83%88%E3%83%AD ↩