TL;DR
生徒(318人)を制約条件を設けながら組(A~H)へアサインするモデルにおいて
各コードがどんな事をしているかをイメージで解説するもの。
対象:営業で機械学習(ML)をそこそこ理解して、数理最適化(MO)を勉強し始めた人
参考
数理最適化の本は多いが、Pythonと結び付けたものは希少。
GitHubでコード公開されていて助かる。
今回は第3章「学校のクラス編成」をやってみた。←割当・マッチング問題
Pythonではじめる数理最適化 ―ケーススタディでモデリングのスキルを身につけよう― [プリント・レプリカ] Kindle版
岩永二郎 (著), 石原響太 (著), 西村直樹 (著), 田中一樹 (著)

Qiitaでは@SaitoTsutomu
(Tsutomu Saito)氏の投稿が大変勉強になる
組合せ最適化 - 典型問題と実行方法
↑
すごい人だから、私がリンク貼ると相手に分かるので貼らない
ご本人から許可いただいたので恐縮ながらリンクさせていただきました!
【GitHub】基本の使い方!初心者がPushするまで
git pull したときに出たエラーの対処法
コード
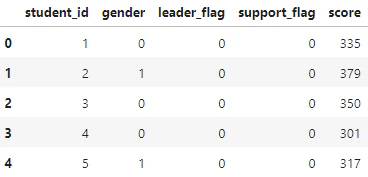
データセット
s_df = pd.read_csv('students.csv')
s_df.head()
生徒(318人)において以下の特徴量が与えられてる
'student_id' 生徒番号
'gender' 性別
'leader_flag' リーダー気質の生徒は「1」
'support_flag' サポート必要な生徒は「1」
''score' テスト点数
数理モデル
pulpではここでモデルを定義する。
・'prob'は何でも良い
・'pulp.LpProblem'は変えちゃだめ
・第1引数"ClassAssingnmentProblem'は何でも良い(目的で命名してるのが多い)
↑
生徒を組にアサインするから'ClassAssignmentProblem'
・第2引数'pulp.LpMaximize'は最大化問題をしますよの宣言(とりあえず最大化でいいらしい)
prob = pulp.LpProblem('ClassAssignmentProblem', pulp.LpMaximize)
生徒のリスト
S = s_df['student_id'].tolist()
生徒(1~318)をリスト化してる。中身は以下の通り単なるリスト。
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318]
組のリスト
A~Hの組を定義する
C = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
生徒、組のペアリスト
forが2つ入っていたり不自然な見た目だが、これでいいらしい。
SC = [(s,c) for s in S for c in C]
中身は以下の通り。
(1, 'A')は生徒番号「1」と組「A」をペアにしたもの。
それが全生徒(1~318)と全組(A~H)のペア分だけある。← (1 , 'A') ~ (318 , 'H')のペア
print(SC[:30])
[(1, 'A'), (1, 'B'), (1, 'C'), (1, 'D'), (1, 'E'), (1, 'F'), (1, 'G'), (1, 'H'), (2, 'A'), (2, 'B'), (2, 'C'), (2, 'D'), (2, 'E'), (2, 'F'), (2, 'G'), (2, 'H'), (3, 'A'), (3, 'B'), (3, 'C'), (3, 'D'), (3, 'E'), (3, 'F'), (3, 'G'), (3, 'H'), (4, 'A'), (4, 'B'), (4, 'C'), (4, 'D'), (4, 'E'), (4, 'F')]
変数の定義
さっき作ったSC(←生徒、組のペア)を変数(←'x'と命名)として定義する。
なぜわざわざSCを変数としてもう一回定義するのか?については、
pulpで扱いやすい型にするだけなので深く考えなくてOK。
・左辺'x'は何でも良い
・'pulp.LpVariable'は変えちゃだめ
・第1引数'x'は何でも良い(左辺の'x'と合わせなくてOK)
・第2引数'SC'は変数の対象←SCは生徒と組のペア
x = pulp.LpVariable.dicts('x', SC)
ここで'x'の中身を見てみると'SC'とは大きく違う
LpVariableで変数設定することでpulpで扱いやすい型?に変形されるのだと理解してる。
print(x[:8])
(1, 'A'): x_(1,_'A'), (1, 'B'): x_(1,_'B'), (1, 'C'): x_(1,_'C'), (1, 'D'): x_(1,_'D'), (1, 'E'): x_(1,_'E'), (1, 'F'): x_(1,_'F'), (1, 'G'): x_(1,_'G'), (1, 'H'): x_(1,_'H')
もともとはこんなだった
print(SC[:8])
(0, ‘A’), (0, ‘B’), (0, ‘C’), (0, ‘D’), (0, ‘E’), (0, ‘F’), (0, ‘G’), (0, ‘H’)
制約条件①
'+='が付いてるコードは制約条件として認識される。
for s in S:
prob += pulp.lpSum([x[s,c] for c in C]) == 1
この制約条件では、1人の生徒がどこか1つの組にアサインされることになる。
(どの組にもアサインされないや、2つ以上の組にアサインされるのを禁止している)
イメージは以下の通り
上段(〇)では、生徒「0」は組Dにアサイン←1つの組にアサインされてるのでOK
中段(×)では、生徒「0」は組DとFにアサイン←2つの組にアサインされてるのでNG
下段(×)では、生徒「0」はどの組にもアサインされてない←0(ゼロ)の組にアサインされてるのでNG

制約条件②
for c in C:
prob += pulp.lpSum([x[s,c] for s in S]) >= 39
prob += pulp.lpSum([x[s,c] for s in S]) <= 40
この制約条件では、1つの組に39~40人の生徒がアサインされることになる。
(1つの組に38人以下や、41人以上アサインされるのを禁止している)
イメージは以下の通り
左(〇)では、A組に生徒40人がアサイン←39~40人なのでOK
中(×)では、A組に生徒30人がアサイン←39~40人じゃないのでNG
右(×)では、A組に生徒50人がアサイン←39~40人じゃないのでNG

感覚的に制約条件①は横に見て、制約条件②は縦に見ている感じ。
↑
この感覚を掴むまで結構苦労した。。。
感想
同じPythonでもMLで使うライブラリー(LightGBM等)と、
MOで使うライブラリー(pulp等)の使い勝手がかなり違うので苦戦。
MLは一度モデル作ったら、そこからパラメーターいじってRMSE向上させてく感じですが
MOはパラメーターいじったりはなく、ひたすら制約条件で切り口を変えていく感じです。
参考にするコードは、MLは多く公開されてる(kaggle等)が、MOはほとんどない。
また、目的にあった制約条件がひらめくのにMLとは違った筋肉が必要な感じです。
まだ勉強中ですが、エクセルを色々な切り口でソートしてる感覚に近いのですが
より複雑なことができますし、それらをコード管理できるのが便利なのかな?と感じます。