統計検定2級の出題範囲をMarkdownに生成してみた件

出力したMarkdownファイルの様子の詳細は下記のURLで確認可能です。
https://hackmd.io/@JYsOCZxWTBOo6gwgv93-jA/BJz5AxuUS
背景
統計スキルを身につけたい
世の中に流れているデータの量がどんどん増加している中、自分がそれを扱う能力と解読能力が必要となってきます。
そこでの解読能力が統計スキルにあたると思い、統計スキルー>統計検定ー>(大学レベルの)統計検定2級までたどり着いたわけです。
それで統計検定2級を勉強しようとし、困ったことは今回の件になります。
統計検定とは
「統計検定」とは、統計に関する知識や活用力を評価する全国統一試験です。
データに基づいて客観的に判断し、科学的に問題を解決する能力は、仕事や研究をするための21世紀型スキルとして国際社会で広く認められています。
日本統計学会は、中高生・大学生・職業人を対象に、各レベルに応じて体系的に国際通用性のある統計活用能力評価システムを研究開発し、統計検定として実施します。
公式サイトより
統計検定の出題範囲
公式サイトに、統計検定の各級の紹介ページには出題範囲が書かれたPDFファイルはあるが、
PDF化されたため、再利用・閲覧にはやや不便な点があります。
出題範囲例↓
PDF:統計検定2級出題範囲表
出典:公式サイト_統計検定2級
解決案
そこで、今回のことを思いついた。
PDFのファイルにあるテーブル情報を自動的に抽出し、処理できる形式に変換する。
さらにそれをMarkdown形式に変更し、ノートとして使えるようにする。
やってみる
これから流れや遭遇した問題を記録していくが、
実際の挙動は、下記のColabにて確認できます。
統計検定の出題範囲をMarkdownに生成してみた件
PDFから内容抽出
PDFの内容をテキストに抽出するにあたり、以下のライブラリが一般的に使われているという
今回はPDFにあるテーブルを検出し扱うため、PDF内のテーブルをPandasのDataFrameに変更できるライブラリ3.Tabula-pyを使うことにした。
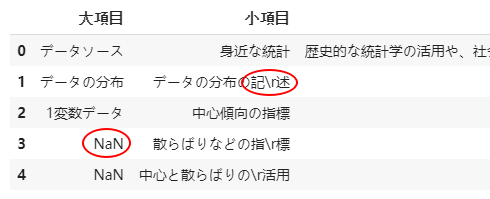
結果で統計検定2級の出題範囲のPDFから、下記の図のようにrawの情報を得ることができた。
pdf_path = "http://www.toukei-kentei.jp/wp-content/uploads/grade2_hani_181214.pdf"
df = tabula.read_pdf(pdf_path, lattice=True)
df.head()
df.isnull().sum()
# output:
大項目 17
小項目 0
ねらい 0
項目(学習しておくべき用語) 6
dtype: int64
問題確認
ここで取得したDFを確認してみると、以下の問題があると気づいた。
- Missing Dataがある
-
\rが所々に入っている
そこで元のPDFファイルを参照して確認したところ、
-
大項目にある欠損値は元々マージされたセルでした。 -
項目にある欠損値は小項目の欠損値により、後ろのセルの値が一つ左に移動した。 -
\rがところは元々の表示に改行があった。
ではまず、3である改行を修正していきます。
DataFrameの整形
Backupをとる
df_old = df.copy()
改行文字をなくす
df = df.replace('\r','', regex=True)
df.head()
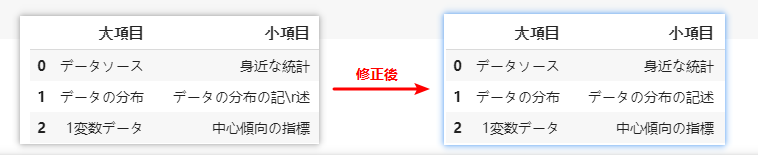
小項目のずれを移動
# 項目における、NULLのセルのindex情報をまとめる
small_nan_index = df[df['項目(学習しておくべき用語)'].isnull() == True].index
small_nan_index
# 指定の範囲の右へ1つ移動
df.loc[small_nan_index, '小項目':] = df.loc[small_nan_index, '小項目':].shift(1, axis=1)
df.loc[small_nan_index, '小項目':]

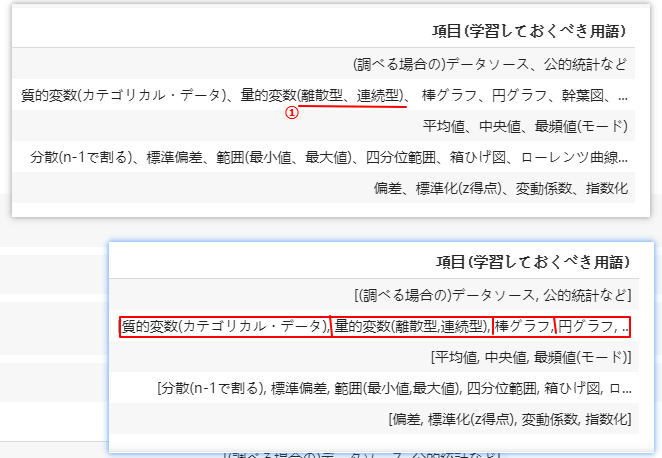
項目の中身をList型へ変更
# replaceのためにsepを変更
df['項目(学習しておくべき用語)'] = df['項目(学習しておくべき用語)'].replace('、',',', regex=True)
# Replace
split_right = lambda x: re.split(''',\s*(?![^()]*\))''', x)
df['項目(学習しておくべき用語)'] = df['項目(学習しておくべき用語)'].apply(split_right)
ここで特に注意するのは、括弧内の「、」(①参照)によりsplitしてはいけないことです。
Markdownに変更
今回のDataFrameとみて、生成するMarkdown風のtextは以下のようにした。
# タイトル
## 大項目
### 小項目1
{ねらい}の説明文
#### 項目a
ユーザーが勉強したノートや、記録内容など、個人個人・・・
#### 項目b
難しかったとか、疑問点とか・・・
### 小項目2
以下省略・・・
結果
下記のHackMDに確認できます。
https://hackmd.io/@JYsOCZxWTBOo6gwgv93-jA/BJz5AxuUS
感想 & 苦労したこと
- 今回はPDF内にほとんどテーブルしかないため、tabula-pyのSettingをあんまりやらなくても進めたが、PDFが複雑ほど、テーブルの位置を指定するなども必要となってくる。
- Regexの除外のSettingをひたすら調べる時に発見した有用なサービスがあります。regex expression 101説明もあるので、Regexの勉強に良いかも。
- 最初はIndexなど付けていなかったが、醜いし、戸惑いそうなので、Index付けるのもやや苦労した。