この手法は、過度に似ていない複数の優れたモデルがある場合に最も効果的です。
- トレーニングセットを2つの互いに素なセットに分割する。
- 最初の部分にいくつかの基礎学習者を訓練する
- 第2部の基礎学習者をテストします。
- 予測を入力として使用し、正しい応答を出力として使用して、より高いレベルの学習者を養成します。
基本的に、レベル1の分類器は、同じ目標関数を近似するために分類器(レベル0分類器)から出てくることを(レベル1分類器)把握させます。 結合機構。
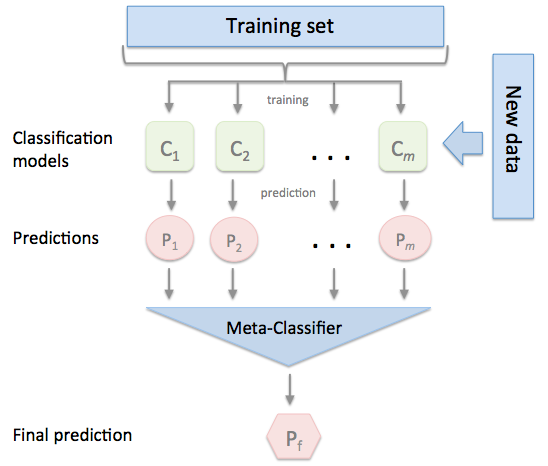
Source: https://rasbt.github.io/mlxtend/user_guide/classifier/StackingClassifier/
ワインデータを読み込む
from sklearn.datasets import load_wine
x, y = load_wine(return_X_y=True)
3つの基本分類子と1つのメタ分類子を定義する
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
extra = ExtraTreesClassifier()
log = LogisticRegression()
knn = KNeighborsClassifier()
rf_metaclassifier = RandomForestClassifier()
スタッキングモデルをトレーニング/テストするためにmlxtendライブラリを使用する
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score
sclf = StackingClassifier(classifiers=[extra, log, knn], meta_classifier= rf)
classifiersList = [mlp, log, knn, sclf]
labelsList = ['Extra Trees', 'Logistic', 'KNN', 'StackingClassifier']
for clf, label in zip(classifiersList, labelsList):
scores = cross_val_score(clf, x, y, cv=10, scoring='accuracy')
print("Accuracy: {} [{}]".format(scores.mean(),label))
Accuracy: 0.967543859649 [Extra Trees]
Accuracy: 0.956432748538 [Logistic]
Accuracy: 0.675773993808 [KNN]
Accuracy: 0.977777777778 [StackingClassifier]