はじめに
ネスト構造の辞書を取得するとき再帰関数で書いたのですが、思っていた以上にPythonの基礎や性質を併せ持っているなと思い、共有と初心者を抜け出す一歩になればと思い記事にしました。
参考になれば幸いです。
再帰関数とは??
再帰関数とは、簡潔に簡単に言うと宣言した関数内部で宣言した関数を用いて繰り返し利用することと思ってもらえれば十分です。
以下のように関数Aの中で関数Aを呼び出すような形が再帰関数です。
def A(x):
if x:
return A(x)
return x
ネスト構造の辞書から任意の値を取得してください
このような時、どのように書きますか?
最初のころの私ならこうのように書いていました。
十分であり、普通に読みやすいかと思います。
ですが、for文など書かずにスマートに書きたいという欲求がいたり再帰関数を書いてみました。
def get_deep_dict(d, keys, default=None):
try:
for key in keys:
d = d.get(key, default)
return d
except AttributeError:
return default
では、本題ですが、以下のような制約を設けます。
- 再利用な状態で作成する ⇒ 関数化
- for文のような繰り返し処理を書かない ⇒ 再帰関数
-
検索するKEYは柔軟性を持つ ⇒ 可変長引数
そうすると以下のように書けます。
from typing import Any
def get_deep_dict(d: dict, *args:tuple, default:Any|None=None) -> Any:
""" 深い辞書型に再帰的パラメータを取得する
"""
try:
if args:
return get_deep_dict(args[0]], *args[1:], default=default)
return d
except AttributeError:
return default
上記の関数を実行する場合、以下のような方法で実行することができ、様々な方法で引数を羅列したり、リストとして呼んだりと実行することができます。
d = {
"A": {
"B": {
"D": 1,
"E": 2
},
"C": 3
}
}
get_deep_dict(d, "A", "B", "D")
# 実行結果 -> 1
get_deep_dict(d, "A", "C")
# 実行結果 -> 3
l = ["A", "B", "D"]
get_deep_dict(d, *l)
# 実行結果 -> 1
get_deep_dict(d, "A", "B", "C", "D")
# 実行結果 -> None
get_deep_dict(d, "A", "B", "C", "D", default=1)
# 実行結果 -> 1
上記のように再帰関数でした。と終わらせるのもつまらないので上記の関数にPythonのどのような特性を持っているかリスト化しています。
- 関数化
- 特定の例外のみをキャッチ
- ミュータブルなオブジェクトの引数
- 可変長引数
- 再帰関数
- 型ヒント
- Docstring
1つの関数から上記の内容が勉強できます。
関数化
説明などは不要と思いますが、同様の処理をしないため関数という一つの処理の塊を作り、再利用可能な形に変換します。
特定の例外のみをキャッチ
ここで想定される例外は辞書を検索するKEYが過分になり、KEYのパラメータがNoneになり発生するAttributeErrorです。
基本、このように予想外な出来事や例外を意図的起こす場合はexceptの後にエラーを指定します。
ちなみに、例外処理をキャッチするのに見るのは外部から実行しているPythonの処理に対してKiilコマンドでKeyboardInterruptで終了後の処理なんて書き方もあります。
今回の式でif文を使えばいいんじゃないと思うかもしれませんが私の構想では以下のようになります。条件式がネスト構造になっていまい、ぱっとしない感じです
from typing import Any
def get_deep_dict(d: dict, *args:tuple, default:Any|None=None) -> Any:
""" 深い辞書型に再帰的パラメータを取得する
"""
if args:
if type(d) is dict and args[0] in d:
return get_deep_dict(d[args[0]], *args[1:], default=default)
else:
return default
return d
上記で簡単に書きましたが、type(d) is dictの is を==とかく人がいるかと思いますが、typeは同一のオブジェクトなので is がベストです!!
ミュータブルなオブジェクトの引数
関数の引数は呼び出し元のオブジェクトを共有する性質を持つため、呼び出し元がリスト・辞書といったミュータブルなオブジェクトであった場合、関数内でオブジェクト内容を変更すると呼び出し元のオブジェクト内容が変化します。
可変長引数
割と使えるようになるkと便利なので学んで後悔はないです。
今回使用したアスタリスク一つの可変長引数には辞書型のdが他移入された後、後で説明しますが 今回のdefault=Noneのように引数のキーワードを指定されるまで、tupleとしてパラメータが追加されていきます。
例を挙げると以下のようになります。すべて結果は(1, 2, 3, 4, 5)になります。
リストの前のアスタリスク(*)を忘れると([1, 2, 3, 4, 5],)のようなリストをそのまま得てしまうので気を付けてください。
def A(*args):
print(args)
A(1,2,3,4,5)
# 実行結果 -> (1, 2, 3, 4, 5)
A(*[1,2,3,4,5])
# 実行結果 -> (1, 2, 3, 4, 5)
l = [1,2,3,4,5]
# 実行結果 -> (1, 2, 3, 4, 5)
A(*l)
# 実行結果 -> (1, 2, 3, 4, 5)
A(l)
# 実行結果 -> ([1, 2, 3, 4, 5],)
可変長引数には、辞書型の可変長キーワード引数もあるので興味が詳しく知りたい人はそれぞれ調べてみてください。
一つ良さを伝えると辞書型を可変長キーワード引数で指定できることが魅力です。
型ヒント と Docstring
3.10 のアップデートでよりしやすくなった型ヒントです。私は割と型ヒントは入れておくとよいと思っている勢です。
更に言うと型ヒントと最低限のDocstringを合わせて書くべきだと思っています。
Docstringに書いていた引数や戻り値は型ヒントからDocstringには関数の説明をするだけで最低限の情報が詰められると思います。
引数の名前に意味をDocstringに関数の意味を型ヒントにどのような値が入ってくるかを示せば、後は読み手の技量次第です。
後は、関数自体の流れを追えることもメリットです。なので、モックを作れば早いですが目視で見つけるのに関数を書いて、情報を書き足した時、違和感を感じる可能性が生まれます。
再帰関数
最後に本題の再帰関数です。ざっくりと述べてはいますが、再帰関数を書いたのは分かったけど、言われても書けねーよ!という方はいると思います。
再帰関数を使う場合は、名前の通り再帰的に行う処理、ループ処理と条件分岐が重なるときに本領を発揮します。
例えば、データ探索で使う根付き木の木構上が一番使いやすいです。
今回、使用した辞書型の例を挙げます。
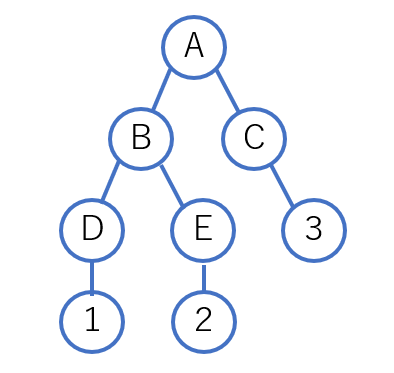
上記のような辞書の階層構造があるとします。辞書型で表すと以下の通りです。
{
"A": {
"B": {
"D": 1,
"E": 2
},
"C": 3
}
}
A ⇒ B ⇒ Dの順で取得して1の値を取得できますが、オレンジの枠線でかかっている
処理をすべてやるのがfor文の処理です。
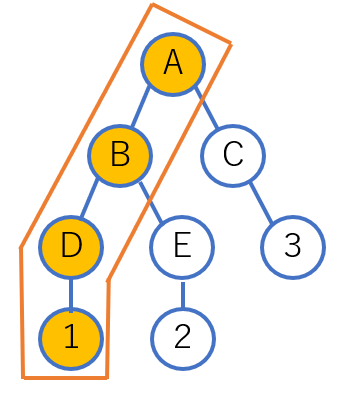
それに対して、再帰的関数はこのように個別に分けて処理をすることでソースコードの書く量と単純な処理に変えることができることが利点です。
この①②③の処理がすべて同一であるときに再帰的関数を書くことができます。
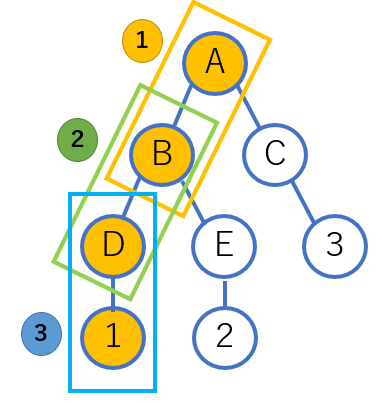
再帰関数の別事例
探索での事例を今回紹介しました。
ですが、再帰的関数は使い方としては、まだまだ沢山ありその中の一角でしかありません。
例えば、パラメータ群を加減乗除・再帰的なアルゴリズム・検索・部分和などなど用途は様々あり、私的に探索が単純で導入しやすい分野になることもあり紹介でした。
最後に
このように図にすると再帰関数は思ったより単純で書けるような気がしてきませんか?
案外、再帰関数を調べてもソースコードや式、詳しく説明された図はあっても簡易化された図示がないものなので作成してみました。詳しく説明するのもよいですが、部分的に簡易化して説明すると理解のしやすさは大きいかと思います。
今回は再帰関数のほかに基本的な要素も複数含めて紹介してみました。知らなかった人は、ぜひ一緒に参考にして頂ければと思います。
理解が深まると楽しさも膨れ上がります。難しそうで取っつきにくいと感じていた人も是非挑戦してみてください。