データベース用テーブルを作成する際には、EXCELなどの表計算ソフトを活用することが多いと思いますが、主キーなどに用いるコードは一定の法則性があるため、自動作成しにくいことが多いです。そんなときに覚えておくと非常に便利なテクニックを紹介していきます。
1:種別コードごとのユニークなシーケンスコードを作成する
要はこういうことをしたい場合です。下の表はこれから種別コードに即したシーケンス(連番)コードを生成していく予定です。
入力規則: 種別コード2桁+シーケンス3桁
表 1-1:シーケンスコード

オートフィルを使えばシーケンスは作れますが、逐一種別コードごとにソートして、それに対しオートフィルを繰り返して、というのは非常に面倒ですので、これを関数一行で制御できるようにします。
使用する関数
- COUNTIF関数
COUNTIF(範囲,対象) - CONCATENATE関数
CONCATENATE(結合対象のセル,…) - TEXT関数 …ゼロパディングに用います
TEXT(対象のセル,表示形式)
手順
①シーケンスを取得
まずは種別のコードごとの件数を数えたいのでCOUNTIF関数を使用します。COUNTIF関数で範囲を記述する場合、主に2通りの記述方法があります。一つは件数を数える場合、もう一つはシーケンスを作る場合です(重複データ削除にも使えます)
たとえば、以下の表には調べたいデータが混在しています。
表1-2:COUNTIF関数を用いた件数とシーケンス取得

=COUNTIF($A$2:$A$20,$A2) …(1)件数
=COUNTIF($A$2:$A2,$A2) …(2)連番
ここではシーケンスを作りたいので、(2)の方法を採用します。これは、範囲の下限が絶対参照、範囲の上限が相対参照になっているのがポイントで、ペーストが行われるごとに範囲が1セルずつ増えていき、調査対象が何回目に出現しているか表示されることになるので、これを利用してシーケンスを作ることができます(表1-2における黄色く塗りつぶしたセル《コード番号13》を参照してください。連番になっているのがわかります)
②ゼロパディング
このシーケンスに対し、コード入力規則に従い、3桁のゼロパディング(ゼロ埋め)を行います。TEXT関数を使用すれば、指定の形式で表示できます。
=TEXT($B2,"000")
表1-3 シーケンスのゼロパディング

③値の結合
後は種別コードとシーケンス部分を結合するだけです。ここで使用するCONCATENATE関数は結合する全てのセルに対し、自動で文字列として認識してくれます。また、後で値を増やしたい場合にも引数を増やすだけなので、非常に処理が楽です。なお、種別コードに対しても桁数が一致するようにTEXT関数を埋め込んで種別コードを2桁に制御しておきます。あとは、この関数をコピーアンドペーストしていくだけです。
=CONCATENATE(TEXT($A1,"00"),$C1)
表1-4 シーケンスコードの生成

これを一度に記述するとこうなり、この関数をコピーアンドペーストしていくことで、種別コードごとのシーケンスを作成することができます。
=CONCATENATE(TEXT($A2,"00"),TEXT(COUNTIF($A$2:$A2,$A2),"000"))
2:同一グループの空白セルに対し、グループ番号をフィルする
要はこういうことをしたい場合です。リスト表などでは、見出しだけグループ番号が振られ、あとのセルは空白のまま…ということがよくあります。これが数件程度なら普通にオートフィル機能を使ってもいいですが、これが何十、何百となってくるといちいちオートフィルをかけるのは非常に手間がかかります。ですので、これを極力少ない計算行を用いて、一行の関数で記述します。
表2-1:値のフィル

使用する関数
- COUNTA関数 …値の入っている件数を取得
COUNTA(範囲,対象) - COUNTIF関数
COUNTIF(範囲,対象) - OFFSET関数
OFFSET(セル,移動行,移動列) - * …
*-1で負数を作ります
OFFSET関数とは?
では、作業前にOFFSET関数のおさらいです。OFFSET関数は任意のセルから明示的に相対位置のセルを取得する関数で、今回の作業の要となります。まずは、以下の表を御覧ください。
表2-2:OFFSET関数の基本

B3に入力された関数は**OFFSET(A3,-1,0)**となっているので、A3から-1行、つまり1行上のセル、A2を見ています。そこでB3にはA2と同じ値が代入されるのです。要はこの応用で、移動行の値を流動的に変更すればいいのです。
そうすると、移動行数は表2-3のようになっているのが理想でしょう。
表2-3:各データの求めたい移動行数

ところが、これは普通に作ろうとしてもかなり作業が困難です。なぜなら、随時フィルしたい行数が変わっていくからです。そこで、どうやってこのグループごとに流動する行数を作っていくかが本題となります。
手順
①COUNTA関数でグループ化する
COUNTA関数は、本来、空白でない値の個数を取得するために使用するものですが、COUNTIF関数でシーケンスを作る方法と同じ要領で下限を絶対参照、上限を相対参照にして範囲を指定すると、対象行に対し次の値が出現するまで同じ値を返していくので、グループ化することができます。
COUNTA($A$2:$A2,A2)
表2-4:各データに対するグループ番号の付与

ここまでくればしめたものです。なお、このグループの計算行も集約して関数1行だけで処理できないか試行錯誤してみましたが、無理でした。
②COUNTIF関数でグループごとの移動行数を求める。
先程のシーケンスコード作成に用いたようにCOUNTIF関数を使って、各グループごとのシーケンスを作っていくと、順番に1,2,3,4…と並びます。そして、この値をOFFSET関数における移動行数にすればいいのです。ここで大事なポイントは、先頭行の移動行数がゼロになるように、各シーケンスから1ずつ差し引いておくことです。
表2-5:COUNTIF関数を用いた移動行数取得(絶対値)
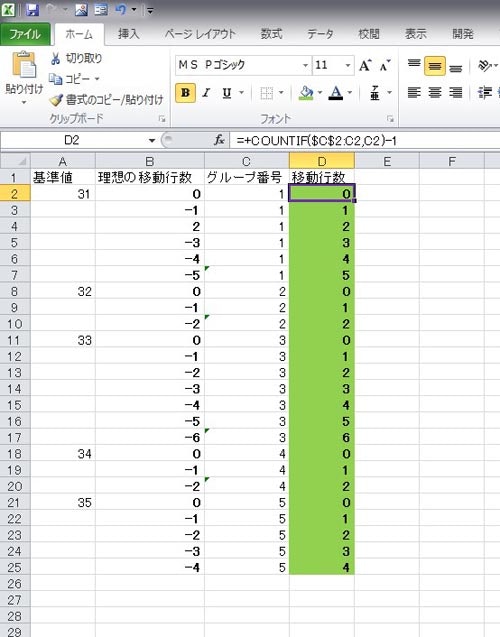
③負数に変換する
今回は、基準セルから上へ、つまり負数の分移動していくので、現在の値を負数に変換する必要があります。負数にするには、いろいろな方法がありますが、一番手っ取り早いのが-1を掛けるという方法です。これを用いることで、移動行に対し、負の数だけ移動する(上に移動する)ことができます。
表2-6:負数への変換

④数式の作成
あとは、OFFSET関数を用いて数式を作成するだけです。D2には先程作成した移動行数が入っているので、基準値行の各参照セルに向かって相対的に行数が変動することになります。そして、この関数をコピーアンドペーストで繰り返していけば、グループ番号が自動生成されていきます。
OFFSET(A2,D2,0)
表2-7:OFFSET関数を用いた値のフィル
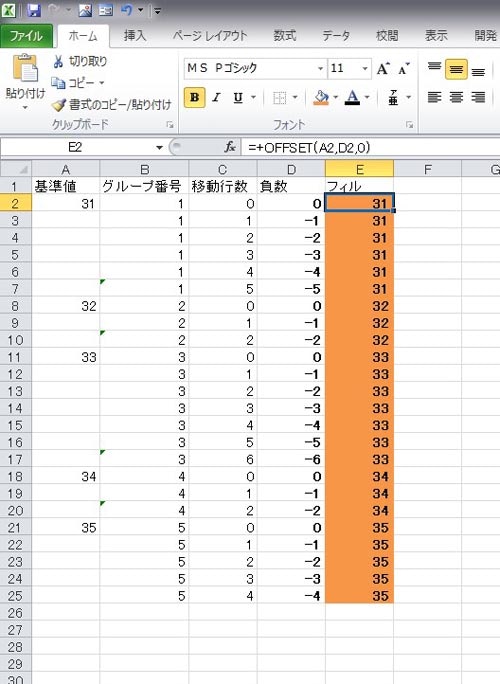
これを一行で処理するのはまず不可能だと思いますが、計算行を1つだけ足して合計2行あれば、このような記述ができます(先ほどとの違いは先に移動行を負数にしているので、調整数は正の数になります)。
OFFSET(A2,COUNTIF($B$2:B2,B2)*-1+1,0)
裏技
この関数を埋め込んだ状態にしておけば、基準値にどんな値を入力しても、次の基準値まで自動的にグループ化され値をフィルしてくれるので、グループ番号だけでなく、グループ名作成にも役立ちます(シーケンスにする必要はなく、また値の重複も関係ありません)。
表2-8:任意の参照値を入力した場合

3 任意の乱数データを作る
テーブルでは顧客情報を管理することも多いですが、テスト段階で顧客の口座番号、マイナンバー番号などを使うわけにはいかないので、だいたいは乱数を発生させて作成することが多いですが、この乱数を逐一考えるのが面倒なので、これも関数でさくっと作りましょう。
①数字のみの乱数
乱数の範囲を指定するRANDBETWEEN関数と文字列を作成できるtext関数を使えば任意の番号を自動生成できます。
RANDBETWEEN(下限値,上限値)
TEXT(対象のアドレス,フォーマットの設定)
では、これを踏まえて仮想顧客の金融機関番号(0先頭を含む任意の7桁の数字)を作成してみましょう。
TEXT(RANDBETWEEN(1,9999999),"0000000") //乱数で仮想顧客の金融機関番号を作る場合
RANDBETWEENの下限値を1にすることと、TEXT関数で桁数を合わせていることで、'0000001'から'9999999'までの乱数を簡単に作成することができます。
ここまではほんの肩慣らしです。では、今度は半角英数字混じりの乱数コードを自動生成してみます。
②英半角の乱数
では、A-zの26文字を使用して6桁の乱数を作成してみます。ですが、今度はRANDBETWEEN関数をそのまま使用しようとしても文字列には対応していません。
ですが、各文字は任意のコードを持っています。そしてCODE関数を使えばJISの値を取得することができます。たとえばAの場合は値は65となります。そしてZは90となります。逆にCHAR関数を使えば、JISの値を各種文字に変換することができます。したがって、JISの値を乱数で取得すれば、A-Zの任意の値を取得できることになります。
CHAR(RANDBETWEEN(65,90))
これでまず、一文字目は取得できました。では、これを6文字分抽出しようとしてみるのですが、パッと思いつくのは繰り返し関数のREPTでしょうが、これは乱数で取得した値の繰り返しになるので、たとえば初期値にAを取得した場合、同じ値の繰り返しにしかなりません。
REPT(CHAR(RANDBETWEEN(65,90)),6) //AAAAAAと初期値の繰り返しになる(逐一乱数発生処理を行わない)
そこで、最新のExcelならCONCAT関数やTEXTJOIN関数などが使えるのですが、自分が使っているのはExcel2010なので、やはりCONCATENATE関数に頼るしかなさそうです。
CONCATENATE(CHAR(RANDBETWEEN(65,90),…,n)
見栄えは悪いですが、これでいちおうA-Zまでの乱数を回数分取得することはできます。ただし、これはあくまでコードが連続している場合に限られるので、たとえばA-zまで取得したい場合、JISコードの範囲は65~90及び97~122となるので、そのまま65~122で範囲取得すると想定外の文字が出てきてしまいます。
③任意の値を乱数とする
では、任意の値を乱数にする場合はどうでしょうか?この乱数取得のRANDBETWEEN関数を見てたらピンとくるはずです。もし、任意の文字列があって、その文字列の順番を無作為に取得したらいけます。
そこでMID関数を使い、任意の文字列から任意の値を取得します。
MID("任意の文字列",抽出する最初の値、抽出する個数)
これを踏まえて、たとえば赤青黄緑白黒で無作為に分類したい場合はこうなります。また、上記のパターンでも任意の文字列を作っておけばいけるでしょう(繰り返したい場合はCONCATENATE関数や&で連結してください)。
MID("赤青黄緑白黒",RANDBETWEEN(1,LEN("赤青黄緑白黒"),1)
任意の文字列から固定長の値をランダムに取得する。
文字列の長さが同じ(固定長)ならば、2文字ずつでもランダムに値を取得することができます。
MID("東京大阪横浜神戸京都札幌福岡仙台広島",RANDBETWEEN(0,LEN("東京大阪横浜神戸京都札幌福岡仙台広島")/2-1)*2+1,2)
解説を入れるとこうなります。RANDBETWEENに代入する乱数は、文字数/固定長になるのはわかると思いますが、最終列を取得したところで値がありません。なので、取得範囲はRANDBETWEEN(1,9)ではなくRANDBETWEEN(0,8)となります。ですが、実際取得するのは2の倍数だけなので、任意の乱数を固定長の倍数にしておきます。そして、値を抽出する範囲が1から数えてXn+1(Xは任意の固定長)個目なので、最後に1を足しておきます。これを繰り返すと何度でも任意の乱数を作成することができます。
値の長さが一致していない場合
では、無作為に取得したい値が以下の場合だとどうでしょうか。
任意の値の候補(千代田、中央、港、新宿)
見事に全部文字数がバラバラなので、任意の文字列を取得するという手が使えません。その場合は無理に固定長にしてしまい、後で埋めた値を消去するという手が使えます。
SUBSTITUTE(MID("千代田中央*港**新宿*",RANDBETWEEN(0,LEN("千代田中央*港**新宿*")/3-1)*3+1,3),"*","")
SUBSUTITUTE関数は任意の値を置換できるので、余分な穴埋め用の文字列を空白に変えてしまうわけです。その際、最終文字列の値(ここでは新宿)の後にも*を忘れないようにしてください。また、固定長は今回3文字となったので、倍数を取得するのも3の倍数となります。
テーブルから乱数を取得する
もし、候補の行があればそれをINDIRECT関数で取得するという手が使えます。例ではA1~A4に任意の値を入れています。
INDIRECT("A"&RANDBETWEEN(1,4))
また、選択範囲の中から任意の値を選択したいならINDEX関数でも無作為の値を取得することができます。範囲はいずれも絶対参照で記述してください。
INDEX(値の範囲,RANDBETWEEN(1,ROW(行の範囲)+1),RANDBETWEEN(1,COLUMN(列の範囲)+1))
4:必要なデータだけを抽出して順番に並べる
EXCEL2016からはfilterという任意の行から空白を除去してくれる便利な関数がありますが、昔のEXCELにはそれがありません。なので、ありあわせの関数でフィルタリングをやってみます。
使用する関数
- COUNTA関数(空白以外の個数を取得します)
- INDIRECT関数(任意のアドレスの参照値を取得します)
- MATCH関数(任意の値を示す行を取得します)
- IFERROR関数(エラー制御します)
- ROW関数(行アドレスを取得します)
欲しいデータをマーキングし、グループ番号を作成する。
欲しいデータをマーキングするまずは全データ(今回はD行)に対し、隣の行(今回はC行)に抽出したいデータをマーキングしておきます(文字は何でも良い)。それに対し、前述したように末尾を相対参照にしてCOUNTA関数でグループ番号を取得します。

=COUNTA($C$2:$C2)
そうすれば、欲しいデータを先頭に、グループ番号が付与されていきます。このグループ番号の末尾が、今回データ化する全データ数となります。
MATCH関数でアドレスを取得する
MATCH関数で、参照アドレスの行をデータの行と一致させ、その行番号を先程のグループ番号と紐づけます。存在するデータならば、各グループ番号の先頭アドレスが示されます(第三引数に必ずFALSEを入れておくこと)。これに対しROW関数を使うことで、インクリメント制御ができます。

=MATCH(ROW()-1,E:E,0),FALSE) #グループ番号に存在する値ならば対象の行が示される
INDIRECT関数でデータ行を参照させる
あとはINDIRECT関数を用いれば、データ行から対象の行アドレスだけを取得できます。ただ、それだけだとデータが存在しない場合は「0」と表示されてしまうので、IFERROR関数で制御しておきましょう。これで欲しいデータだけを抽出することができます。
=IFERROR(INDIRECT("D"&MATCH(ROW()-1,E:E,FALSE)),"")
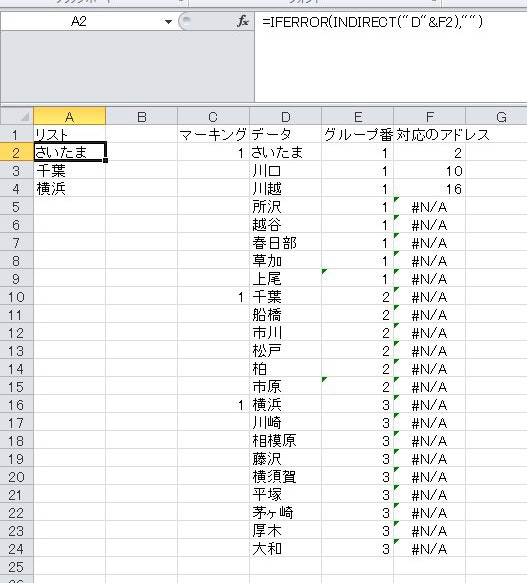
また、任意のタイミングでマーキング行に値を追加するだけでデータの挿入も行われます。
※Jリーグのホームタウンが存在する都市をリストに抽出

また、この制御を応用すれば、主キーだけで紐づいた体裁や個数の異なる複数のデータに対し、マッチングができるようになります。