PHPでWEBシステム制作の案件を処理していると、まれにwordのドキュメントファイルを読み込まないといけないという案件があったりします。ですが、Wordのドキュメントファイルに書き込むことを前提としたPHP-wordの使用方法はちらほら出てくるのですが、あくまでPHP上のデータをWord上に書き込むだけであり、逆にWordのドキュメントファイルを読み込むという方法がなかなか出てきません。
そこで、色々と検索ワードを考えて海外サイトも含め巡回した成果を記録していきたいと思います。
Wordのdocxファイルを読み込む
docxファイルはWord2007から主流となっている、XMLを使用したファイルです。なので、PHPでXMLを読み込めるように対処すれば普通に読み込めてしまったりします。
これは、自分が公開しているPhpspreadsheetに関する記事から抜粋したものですが、こちらもxlsxファイルを読み込むためにphp-zipとlibzip5ライブラリをインストールしているので、docxファイルの場合も同じライブラリをインストールしておきます。
/*PHP7.1以前はこちら*/
hogehoge$ yum --enablerepo=remi-phpxx -y install php-zip libzip5
/*PHP7.2以降はこちら*/
hogehoge$ yum --enablerepo=remi-phpxx -y install php-pecl-zip libzip5
hogehoge$ systemctl restart httpd //Apacheの場合、Nginxならhttpdをnginxに書き替える
hogehoge$ php --ri zip//zip関連のアーカイブがインストールされているか確認
/*このように表示されていれば確実*/
zip
Zip => enabled
Zip version => x.x.x
Libzip headers version => x.x.x
Libzip library version => x.x.x
docxファイルを読み込む
あとはZipArchiveクラスを用いるだけです。
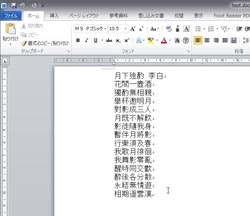
$filename = "test.docx"; //対象となるdocxファイル
$zip = zip_open($filename);
$content = "";
if ($zip && !is_numeric($zip)){
while ($zip_entry = zip_read($zip)) {
if (zip_entry_open($zip, $zip_entry) == FALSE) continue;
if (zip_entry_name($zip_entry) != "word/document.xml") continue;
$content .= zip_entry_read($zip_entry, zip_entry_filesize($zip_entry));
zip_entry_close($zip_entry);
}
}
zip_close($zip);
$content = preg_replace("/\<\/w:t\>/","<br>",$content); //改行にあたる部分だけを置き換える
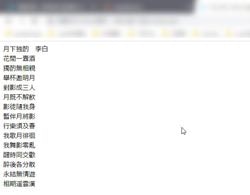
echo $content;
これで後はブラウザに表示するだけです。ただ、元のソースのままだと改行が行われなかったので、改行が行われるように修正を加えています。また、ソースを見るとまだまだ無駄なタグがあるので、それを必要に応じて置換するといいでしょう。
参考にしたページ
How to extract text from word file .doc,docx,.xlsx,.pptx php
Wordのdocファイルを読み込む
docファイルはマイクロソフト社が独自で開発した規格のため、かなりの人が処理に悪戦苦闘しているようですが、実はfile関数を使って開くことができるようです。ですが、そこからのエンコードに苦戦しているようで、いろいろなサイトで方法を公開していますが、的確に処理できていた記述は上記のリンクにあった方法だけでした。

$filename = "test.doc"; //テスト用のドキュメントファイル
if(file_exists($filename)){
if(($fh = fopen($filename, 'r')) !== false ){
$headers = fread($fh, 0xA00);
// 1 = (ord(n)*1) ; Document has from 0 to 255 characters
$n1 = ( ord($headers[0x21C]) - 1 );
// 1 = ((ord(n)-8)*256) ; Document has from 256 to 63743 characters
$n2 = ( ( ord($headers[0x21D]) - 8 ) * 256 );
// 1 = ((ord(n)*256)*256) ; Document has from 63744 to 16775423 characters
$n3 = ( ( ord($headers[0x21E]) * 256 ) * 256 );
// 1 = (((ord(n)*256)*256)*256) ; Document has from 16775424 to 4294965504 characters
$n4 = ( ( ( ord($headers[0x21F]) * 256 ) * 256 ) * 256 );
// Total length of text in the document
$textLength = ($n1 + $n2 + $n3 + $n4);
$text = fread($fh, $textLength);
nl2br($text);
$text = preg_replace('/[\x00-\x09\x0B\x0C\x0E-\x1F\x7F]/',"",$text); //制御記号を置換
echo $text;
}
}
ただ、それだけだと制御文字まで表示されてしまっていたので、置換処理を施しています。
※あくまでStack Overflowでの記事なので、日本語までは対応していません。いちおう文字化けした状態では出力されるのですが、エンコードができずに苦戦しています。もし、解決方法をご存知の方はアンサーをいただけると大変助かります。
Antiwordを使用
もう一つ、半角英数字を読み込む方法としてAntiwordというライブラリを使用するという手があります。forensicsリポジトリを使用すれば、yumからインストール可能です。
# yum install https://forensics.cert.org/cert-forensics-tools-release-el7.rpm
# yum install --enablerepo=forensics antiword
あとはバイナリの場所を探してプログラムを記述するだけです。注意点はshellexecコマンドの変数に、antiwordの後、半角を空ける必要があります(shell_execはPHPからシェルコマンドを叩く関数なので、バイナリを操作していることと同じです)。
<?php
$filename = "test.doc"; //テスト用のドキュメントファイル
if(file_exists($filename)){
$content = shell_exec('/usr/bin/antiword '.$filename);
$content = preg_replace("/\n/","<br />",$content);
echo $content;
}
…ですが、やはり日本語には対応していませんので、対応させる方法を探索中です。