はじめに
これはあくまで、個人で利用するために作成したものであり、これを用いて作成したファイルの二次配布などによる損害や損失に対して、責任を負うことはできません。
追記(24/8/17)
ESPで遊んでいる間に皆さん結構ご覧いただけたようでうれしいです。かなり適当な感じで書いた記事なので、もう少しコンテンツを充実させました。
使用サービス
以下の二つを利用してソフトウェアを作成する。使用言語はpython。
青空文庫
青空文庫は、著作権の消失した様々な作家の本を無料で読むことのできるサイトである。
VoiceVox
VoiceVoxは、ずんだもんや四国めたんをはじめとする文章読み上げソフトである。
VoiceVoxには起動した際にローカルホスト(http://localhost:50021/docs#/) にHTTPサーバーを立ち上げローカルホストでのAPIの利用が可能になっている。
問題
これを行うにあたって3つの問題が発生した。
英語読めない問題
voicevoxでは英語を読み込んで発音することができない。そのため、英語をカタカナに変換する必要がある。
対策
英語をカタカナにするためにはいくつかの方法がある。しかし、手軽さとデータが手に入ったことから辞書を用いた探索方式にすることにした。
辞書は以下を利用している
辞書式も欠点があり、辞書に登録されていない英単語のカタカナは変換できないという点である。そのため、Mecab?を使った方法でもよいと思う。
ルビの問題
青空文庫にはルビがふってあり、読みやすくなっている。しかし、その反面読み上げる際にルビが邪魔になってしまう。
対策
対策は簡単で、ルビは《》で囲まれているため、その部分を探索して削除することで対策になる。
長い文章読み込めない問題
VoiceVoxでは、長すぎる文章をAPIに送信するとエラーが発生するようになっているようだった。
対策
文章をいくつかのチャンクに分割して、それらをVoiceVoxAPIに送信することによって音声データを得ることにした。
フローチャート
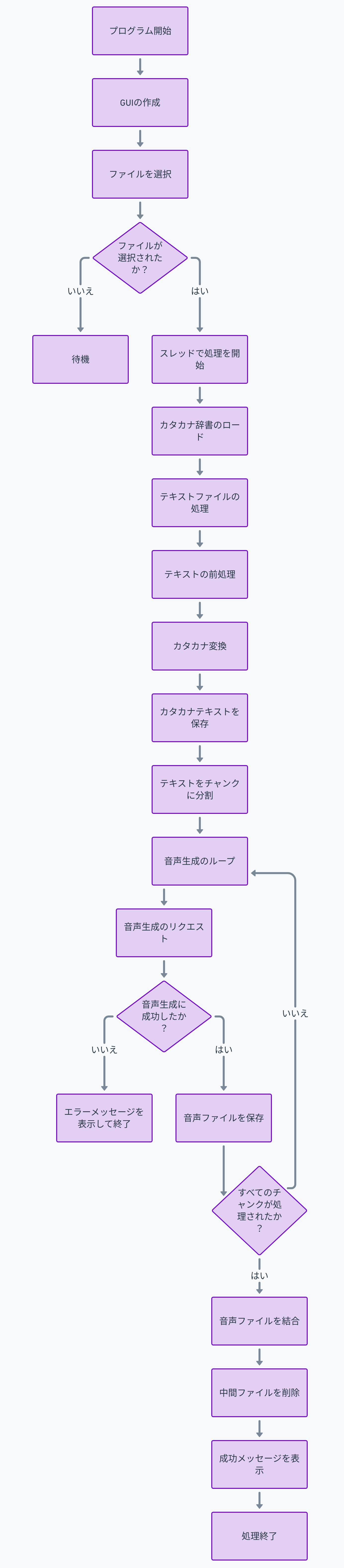
実際の利用
今回は、いろはにほへとを入力することとする。また、英語の入力がうまくいっていることを確認するために以下の文章を入力として用いる。
Hello World
いろはにほへと ちりぬるを
わかよたれそ つねならむ
うゐのおくやま けふこえて
あさきゆめみし えひもせす
上記のyoutubeの動画のような音声が出力される。
また、夢野久作のドグラマグラの冒頭詩を出力してみる。
胎児よ
胎児よ
何故躍る
母親の心がわかって
おそろしいのか
こういった具合に音声ファイルを作成することができる。
実装(追加分)
ライブラリ
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import requests
import re
import chardet
import time
from pydub import AudioSegment # 音声ファイルの連結に使用
import threading # スレッド処理に使用
import os # ファイル削除に使用
thinterは皆さんご存じの通り、GUIのためのライブラリです。
requestは、VoiceVoxのローカルAPIにHTTPリクエストを送信するためのライブラリです。
reは、正規表現操作を行うための標準ライブラリです。英単語を見つけてカタカナに変換するのでそういったときに利用しています。
chardetは、文字のエンコーディングを自動的に検出するためのライブラリです。青空文庫のtxtはshift-JISかなんかなのですが、一応念のため実装しています。
timeは、時間系のライブラリですが処理の進捗を待機させたり時間計測を行うために使っています。
pydubは、音声ファイルの操作するためのライブラリです。無音部分の追加やファイル連結に使用しています。
threadingは、並列処理を行うためのライブラリです。かなり実行に時間を要するため、並列処理を導入しています。
osは、一時ファイルを削除するために使用しています。
カタカナ変換用の辞書をロードする関数 load_katakana_dictionary
load_katakana_dictionary関数は、カタカナ変換用の辞書をロードしています。
def load_katakana_dictionary(dic_file):
# 空の辞書を初期化
katakana_dict = {}
try:
# 指定された辞書ファイルを読み込みモードで開く
# ファイルのエンコーディングはUTF-8と指定
with open(dic_file, 'r', encoding='utf-8') as file:
# ファイルの各行を順番に処理
for line in file:
# 行末の改行や余分な空白を削除し、スペースで分割
parts = line.strip().split()
# 分割後のリストが2つの要素を持つ場合のみ処理
# 一つ目の要素は英単語、二つ目の要素はカタカナ表記
if len(parts) == 2:
# 英単語を大文字に変換
english_word = parts[0].upper()
# カタカナ表記を取得
katakana = parts[1]
# 辞書に英単語をキー、カタカナを値として追加
katakana_dict[english_word] = katakana
except FileNotFoundError:
# 指定された辞書ファイルが存在しない場合の例外処理
print(f"辞書ファイル '{dic_file}' が見つかりません。")
# 辞書を返す(英単語がキー、カタカナが値)
return katakana_dict
カタカナに変換する関数 english_to_katakana
english_to_katakana関数は、テキスト内の英単語を辞書に基づいて変換します。
def english_to_katakana(text, katakana_dict):
def replace_word(match):
word = match.group(0).upper() # 大文字に変換
return katakana_dict.get(word, word)
# 正規表現で英単語を検索し、カタカナに変換
katakana_text = re.sub(r'\b[a-zA-Z]+\b', replace_word, text)
return katakana_text
テキストをきれいに整形する関数 clean_text remove_intro
def clean_text(text):
# ルビ(ふりがな)表記を削除する
# 例: 「彼女《かのじょ》は美しい」 -> 「彼女は美しい」
text = re.sub(r'《.*?》', '', text)
# 特定の注釈を削除する
# 例: 「[#ページの左に図]この本は古い」 -> 「この本は古い」
text = re.sub(r'[#.*?]', '', text)
# 全角スペースを半角スペースに置換する
# 例: 「彼女は 美しい」 -> 「彼女は 美しい」
text = text.replace(' ', ' ')
# テキストの前後にある余分な空白文字を削除する
# 例: 「 彼女は美しい 」 -> 「彼女は美しい」
text = text.strip()
# クリーンなテキストを返す
return text
def remove_intro(text):
# テキスト内の特定のパターンに一致する序文を削除する
# パターンは「10個以上のハイフンで始まり、10個以上のハイフンで終わる」部分
# DOTALLフラグは、ドットが改行文字にもマッチするように設定
text = re.sub(r'-{10,}.*?-{10,}', '', text, flags=re.DOTALL)
# 加工されたテキストを返す
return text
文を分割する関数 splite_text
def split_text(text, max_length=100):
# テキストを文ごとに分割
# 正規表現パターン r'(?<=[。!?])' は、句点「。」「!」「?」の後ろで文を分割する
sentences = re.split(r'(?<=[。!?])', text)
# 結果を格納するためのリストを初期化
chunks = []
# 現在処理中の文のチャンク(塊)を保持する変数を初期化
current_chunk = ""
# 分割された各文を順に処理
for sentence in sentences:
# 現在のチャンクにこの文を加えるとmax_lengthを超えるかどうかをチェック
if len(current_chunk) + len(sentence) > max_length:
# 超える場合は、現在のチャンクをリストに追加し、新しいチャンクを開始
chunks.append(current_chunk)
current_chunk = sentence
else:
# 超えない場合は、現在のチャンクにこの文を追加
current_chunk += sentence
# 最後のチャンクが空でない場合、それをリストに追加
if current_chunk:
chunks.append(current_chunk)
# 分割されたチャンクのリストを返す
return chunks
チャンクに分割しないと、APIへ送信したときにエラーが返ってきます。
カタカナに変換した後のtxtファイルを生成するprocess_text_file
これは、ほぼデバッグ用の関数ですがそのまま実装しています。
def process_text_file(file_path, katakana_dict, progress, status_label):
# テキストファイルをバイナリモードで開き、エンコーディングを自動検出
with open(file_path, 'rb') as f:
result = chardet.detect(f.read()) # ファイル全体を読み込み、文字エンコーディングを推測
# 検出されたエンコーディングを使用してファイルをテキストモードで開く
with open(file_path, 'r', encoding=result['encoding']) as file:
original_text = file.read() # ファイル全体を読み込み、テキストとして保持
# プログレスバーを10ステップ進める(全体の10%完了)
progress.step(10)
# 序文や不必要な部分を削除
text_without_intro = remove_intro(original_text)
# プログレスバーを10ステップ進める(全体の20%完了)
progress.step(10)
# テキストをクリーンアップ(注釈や全角スペースを削除)
cleaned_text = clean_text(text_without_intro)
# プログレスバーを10ステップ進める(全体の30%完了)
progress.step(10)
# クリーンなテキスト内の英単語をカタカナに変換
katakana_text = english_to_katakana(cleaned_text, katakana_dict)
# プログレスバーを10ステップ進める(全体の40%完了)
progress.step(10)
# カタカナに変換したテキストを新しいファイルに保存
base_name = os.path.basename(file_path) # 元のファイル名を取得
katakana_file_name = f"変換_{os.path.splitext(base_name)[0]}.txt" # 新しいファイル名を作成
katakana_file_path = os.path.join(os.path.dirname(file_path), katakana_file_name) # 保存パスを生成
# 生成したファイルパスに、変換後のテキストをUTF-8エンコードで書き込み
with open(katakana_file_path, 'w', encoding='utf-8') as katakana_file:
katakana_file.write(katakana_text)
# 変換後のファイルのパスを返す
return katakana_file_path
音声を生成する関数 generate_voice
def generate_voice(text, speaker, file_path='output.wav', progress=None):
# 音声合成クエリのためのペイロードを作成
# 'text' は合成するテキスト、'speaker' は使用する声のID
query_payload = {'text': text, 'speaker': speaker}
# VOICEVOXのAPIサーバーに音声合成クエリをリクエスト
query_response = requests.post('http://localhost:50021/audio_query', params=query_payload)
# リクエストが失敗した場合のエラーチェック
if query_response.status_code != 200:
# エラーメッセージを表示し、関数を終了
messagebox.showerror("エラー", f"音声合成クエリの作成に失敗しました: {query_response.status_code}")
return False
# クエリのレスポンスデータをJSON形式で取得
query_data = query_response.json()
# プログレスバーを5ステップ進める(全体の5%完了)
if progress:
progress.step(5)
# 音声合成のためのペイロードを作成
# 'speaker' は使用する声のID、'json=query_data' でクエリデータを送信
synthesis_payload = {'speaker': speaker}
synthesis_response = requests.post('http://localhost:50021/synthesis', params=synthesis_payload, json=query_data)
# リクエストが失敗した場合のエラーチェック
if synthesis_response.status_code != 200:
# エラーメッセージを表示し、関数を終了
messagebox.showerror("エラー", f"音声合成に失敗しました: {synthesis_response.status_code}")
return False
# 成功した場合、生成された音声データを指定されたファイルパスに保存
with open(file_path, 'wb') as audio_file:
audio_file.write(synthesis_response.content) # バイナリ形式で音声データを書き込み
# プログレスバーを5ステップ進める(全体の10%完了)
if progress:
progress.step(5)
# 処理が成功したことを示すためにTrueを返す
return True
メイン関数process_and_generate
def process_and_generate(file_path, speaker, progress, status_label):
# カタカナ辞書を読み込む
katakana_dict = load_katakana_dictionary('dictionary.dic')
# テキストファイルを処理して、カタカナに変換されたテキストファイルを作成
katakana_file_path = process_text_file(file_path, katakana_dict, progress, status_label)
# カタカナに変換されたテキストを読み込む
with open(katakana_file_path, 'r', encoding='utf-8') as file:
katakana_text = file.read()
# テキストを指定した長さ(max_length=100)ごとに分割
text_chunks = split_text(katakana_text, max_length=100)
# 生成された音声ファイルのリストを格納するためのリスト
output_files = []
# プログレスバーの最大値を設定
# 前処理に40ステップ、各音声生成ごとに10ステップを設定
total_steps = 40 + 10 * len(text_chunks)
progress["maximum"] = total_steps
# 各チャンクごとに音声を生成
for i, chunk in enumerate(text_chunks):
# 分割されたテキストチャンクごとに音声ファイルを作成
output_file = f'output_part_{i + 1}.wav'
success = generate_voice(chunk, speaker, file_path=output_file, progress=progress)
# 音声生成が失敗した場合、処理を中断
if not success:
break
# 成功した場合、生成されたファイルをリストに追加
output_files.append(output_file)
# ステータスラベルを更新して、処理の進行状況を表示
status_label.config(text=f"{i + 1}分の{len(text_chunks)}が終了しました")
# 生成された音声ファイルがある場合
if output_files:
# 全ての音声ファイルを結合して1つの音声ファイルにまとめる
combined = AudioSegment.empty() # 空のAudioSegmentを作成
silence = AudioSegment.silent(duration=500) # 0.5秒の無音を作成
for file in output_files:
# 各音声ファイルを読み込み、結合
audio_segment = AudioSegment.from_wav(file)
combined += audio_segment + silence
# 結合された音声を新しいファイルとして保存
combined.export("output_combined.wav", format="wav")
# プログレスバーを10ステップ進める
progress.step(10)
# 処理完了のメッセージを表示
messagebox.showinfo("成功", f"音声ファイルが生成されました: output_combined.wav")
# 中間生成ファイルを削除してクリーンアップ
for file in output_files:
try:
os.remove(file)
except OSError as e:
# ファイル削除に失敗した場合のエラーメッセージ
print(f"Error: {file} : {e.strerror}")
そのほか
そのほか関数はGUIの実装で特筆すべきことはないです。
コード
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import requests
import re
import chardet
import time
from pydub import AudioSegment # 音声ファイルの連結に使用
import threading # スレッド処理に使用
import os # ファイル削除に使用
def load_katakana_dictionary(dic_file):
katakana_dict = {}
try:
with open(dic_file, 'r', encoding='utf-8') as file:
for line in file:
parts = line.strip().split()
if len(parts) == 2:
english_word = parts[0].upper()
katakana = parts[1]
katakana_dict[english_word] = katakana
except FileNotFoundError:
print(f"辞書ファイル '{dic_file}' が見つかりません。")
return katakana_dict
def english_to_katakana(text, katakana_dict):
def replace_word(match):
word = match.group(0).upper() # 大文字に変換
return katakana_dict.get(word, word)
# 正規表現で英単語を検索し、カタカナに変換
katakana_text = re.sub(r'\b[a-zA-Z]+\b', replace_word, text)
return katakana_text
def clean_text(text):
text = re.sub(r'《.*?》', '', text)
text = re.sub(r'[#.*?]', '', text)
text = text.replace(' ', ' ')
text = text.strip()
return text
def remove_intro(text):
text = re.sub(r'-{10,}.*?-{10,}', '', text, flags=re.DOTALL)
return text
def split_text(text, max_length=100):
sentences = re.split(r'(?<=[。!?])', text)
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk) + len(sentence) > max_length:
chunks.append(current_chunk)
current_chunk = sentence
else:
current_chunk += sentence
if current_chunk:
chunks.append(current_chunk)
return chunks
def process_text_file(file_path, katakana_dict, progress, status_label):
with open(file_path, 'rb') as f:
result = chardet.detect(f.read())
with open(file_path, 'r', encoding=result['encoding']) as file:
original_text = file.read()
progress.step(10)
text_without_intro = remove_intro(original_text)
progress.step(10)
cleaned_text = clean_text(text_without_intro)
progress.step(10)
katakana_text = english_to_katakana(cleaned_text, katakana_dict)
progress.step(10)
# カタカナに変換したテキストを保存
base_name = os.path.basename(file_path)
katakana_file_name = f"変換_{os.path.splitext(base_name)[0]}.txt"
katakana_file_path = os.path.join(os.path.dirname(file_path), katakana_file_name)
with open(katakana_file_path, 'w', encoding='utf-8') as katakana_file:
katakana_file.write(katakana_text)
return katakana_file_path
def generate_voice(text, speaker, file_path='output.wav', progress=None):
query_payload = {'text': text, 'speaker': speaker}
query_response = requests.post('http://localhost:50021/audio_query', params=query_payload)
if query_response.status_code != 200:
messagebox.showerror("エラー", f"音声合成クエリの作成に失敗しました: {query_response.status_code}")
return False
query_data = query_response.json()
progress.step(5)
synthesis_payload = {'speaker': speaker}
synthesis_response = requests.post('http://localhost:50021/synthesis', params=synthesis_payload, json=query_data)
if synthesis_response.status_code != 200:
messagebox.showerror("エラー", f"音声合成に失敗しました: {synthesis_response.status_code}")
return False
with open(file_path, 'wb') as audio_file:
audio_file.write(synthesis_response.content)
progress.step(5)
return True
def process_and_generate(file_path, speaker, progress, status_label):
katakana_dict = load_katakana_dictionary('dictionary.dic')
katakana_file_path = process_text_file(file_path, katakana_dict, progress, status_label)
with open(katakana_file_path, 'r', encoding='utf-8') as file:
katakana_text = file.read()
text_chunks = split_text(katakana_text, max_length=100)
output_files = []
total_steps = 40 + 10 * len(text_chunks) # 40は前処理のステップ数、各音声生成ごとに10ステップ追加
progress["maximum"] = total_steps
for i, chunk in enumerate(text_chunks):
output_file = f'output_part_{i + 1}.wav'
success = generate_voice(chunk, speaker, file_path=output_file, progress=progress)
if not success:
break
output_files.append(output_file)
status_label.config(text=f"{i + 1}分の{len(text_chunks)}が終了しました")
if output_files:
combined = AudioSegment.empty()
silence = AudioSegment.silent(duration=500) # 0.5秒の無音を作成
for file in output_files:
audio_segment = AudioSegment.from_wav(file)
combined += audio_segment + silence
combined.export("output_combined.wav", format="wav")
progress.step(10)
messagebox.showinfo("成功", f"音声ファイルが生成されました: output_combined.wav")
# 中間ファイルを削除
for file in output_files:
try:
os.remove(file)
except OSError as e:
print(f"Error: {file} : {e.strerror}")
def open_file(progress, speaker, status_label):
file_path = filedialog.askopenfilename(filetypes=[("Text Files", "*.txt")])
if file_path:
progress.start()
threading.Thread(target=process_and_generate, args=(file_path, speaker, progress, status_label)).start()
def create_gui():
root = tk.Tk()
root.title("VoiceVox 音声生成アプリ")
root.geometry("300x300")
label = tk.Label(root, text="テキストファイルを選択して音声を生成")
label.pack(pady=10)
# スピーカー選択用のコンボボックス
speaker_label = tk.Label(root, text="朗読する声を選択してください")
speaker_label.pack(pady=5)
speakers = {
"四国めたん": 2,
"ずんだもん": 3,
"春日部つむぎ": 8,
"雨晴はう": 10,
"冥冥ひまり": 14,
"SAYO": 46,
"ナースロボタイプT": 47
# 必要に応じて他の声も追加できます
}
speaker_var = tk.StringVar(value="四国めたん")
speaker_combobox = ttk.Combobox(root, textvariable=speaker_var, values=list(speakers.keys()))
speaker_combobox.pack(pady=5)
progress = ttk.Progressbar(root, orient='horizontal', length=250, mode='determinate')
progress.pack(pady=10)
status_label = tk.Label(root, text="処理が開始されていません")
status_label.pack(pady=10)
open_button = tk.Button(root, text="ファイルを開く", command=lambda: open_file(progress, speakers[speaker_var.get()], status_label))
open_button.pack(pady=10)
root.mainloop()
if __name__ == "__main__":
create_gui()