久しぶりにQiitaに記事を書きます。最近はライトノベルを書いていました。直近では、エロ同人音声をテーマにしたミステリ小説を書き企画賞に応募していたのですが、作中にフォルマント解析のプログラムを登場させたので、リアリティを出すために実際にコーディングしてみます。あ、作品はこちらです。
Pythonコード
さて、まずは「先輩、やめてください」という音声ファイルを用意します。で、parselmouthというライブラリを使い、そのフォルマントを解析してmatplotlibで図示してみます。
import parselmouth
import numpy as np
import matplotlib.pyplot as plt
sound = parselmouth.Sound("SenpaiNoPlease.wav")
formant = sound.to_formant_burg()
plt.figure()
plt.plot(formant.xs(), [formant.get_value_at_time(1, t) for t in formant.xs()], 'r') # F1
plt.plot(formant.xs(), [formant.get_value_at_time(2, t) for t in formant.xs()], 'g') # F2
plt.plot(formant.xs(), [formant.get_value_at_time(3, t) for t in formant.xs()], 'b') # F3
plt.plot(formant.xs(), [formant.get_value_at_time(4, t) for t in formant.xs()], 'y') # F4
plt.plot(formant.xs(), [formant.get_value_at_time(5, t) for t in formant.xs()], 'm') # F5
plt.title("Formants over time")
plt.xlabel("Time [s]")
plt.ylabel("Frequency [Hz]")
plt.show()
実行結果はこちら。
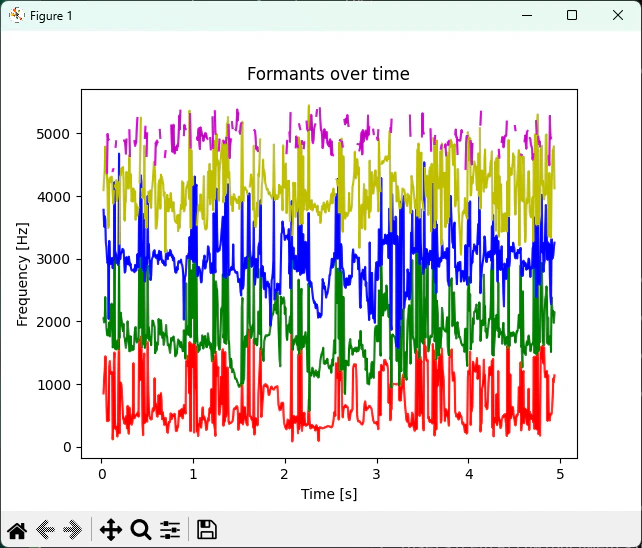
説明
to_formant_burg()は音声信号から共振周波数を抽出するための関数です。線形予測分析(LPC)の一種、バーグ法と呼ばれるアルゴリズムを用いており、John Burgによって1960年代に確立された手法だそうです。上記のソースで示されている通り、parselmouthでは、F1からF5までのフォルマントの検出が可能になっています。
DTMソフト等を使っていると、フォルマントというものは、ピッチやベロシティと同じ1つのパラメータなのだと思ってしまいがちです。しかし実際には周波数帯域によってF1, F2, F3と別れており、それぞれが口の開き方や舌の位置によって規定される母音の音色に対応しています。
いや、例えば、ボイスチェンジャーでピッチとフォルマントを上げる操作を行い、男声を女声に変えたりすることがありますよね。でも、一般的なボイスチェンジャーでは上記の全帯域を一括で操作しているため、根本的な声質は変わりません。近い口の構造を持った人の声になるだけで、誰か他の人になることはできないのです。
つまり、俺がボイスチェンジャーを使っても美少女になれないのは、パラメータが足りないからです。フォルマントだけでもF1, F2, F3などを個別に調整する必要があるはずですし、それ以外にも、アクセントや発話スタイルなどの様々な声質の要素があり、計算操作で人の声を変えることは極めて難しい。そのため最近では、機械学習を用いて声質を変換する手法が主流になっているようです。
とにかく、声というものは闇が深い。冒頭のラノベでもその辺りの限界を前提にして物語を作っています。もしその筋の専門家の方が見ていたら、アクセスして間違いを指摘していただけますと幸甚です。
おまけ
実音声を聞きたいという酔狂な方はこちらからぞうぞ。QiitaでAudioタグ使えないみたいなのでYouTubeでUnlisted公開してリンクしました。元音声と、Rubber Band( https://breakfastquay.com/rubberband/ )のwindowsコマンドツールでピッチシフトしたバージョンの2つで試しています。
参考:
https://ja.wikipedia.org/wiki/%E7%B7%9A%E5%BD%A2%E4%BA%88%E6%B8%AC%E7%AC%A6%E5%8F%B7