概要
いくつかスクレイピングに関する記事を紹介したのですが,いずれもrequestsとBeautifulSoupで完結するものでした.今回は,JavaScriptなどでページの内容が変化していくような動的なWebページのスクレイピングをSeleniumを利用して行ってみたいと思います.Chrome+Seleniumを使うパターンが多いと思います.紹介が少ないので,この記事では,Firefoxをブラウザーとして利用します.
暑い時期にはカレーということで,無印良品のレトルトカレーのページを題材にして動的なページからの情報の抽出を行います.
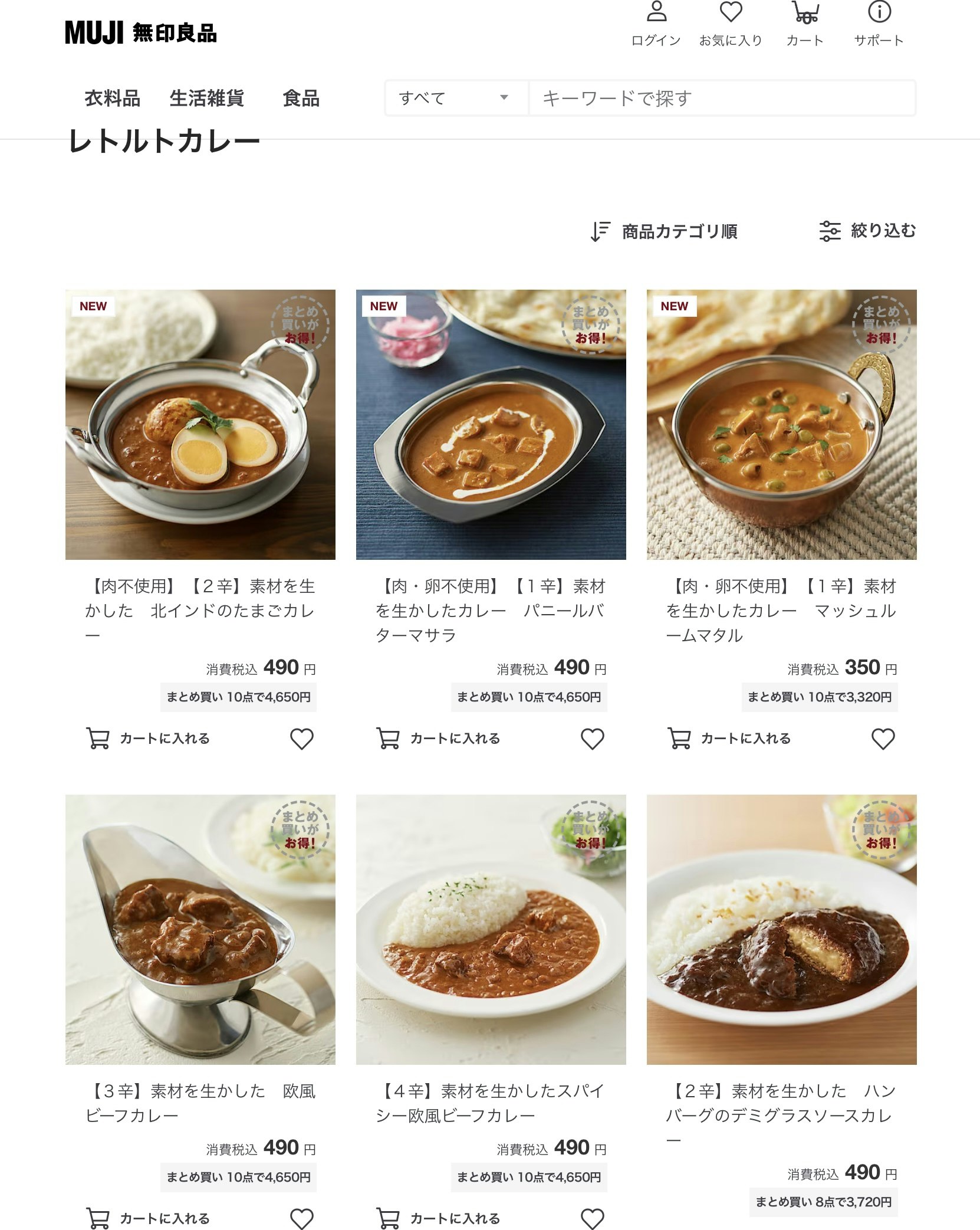
最終的に,商品名,辛さ,価格をデータフレームにまとめていきます1.

無印良品のレトルトカレーのページ
右クリックのメニューやrequestsを利用して,レトルトカレーのページのソースコードを確認してみました.
<html lang="ja" >
<head>
<!-- CR-1289_GA4のパラメータ埋め込み Add Start -->
<script async src="https://www.googletagmanager.com/gtag/js?id=G-N4VFRRWDJH"></script>
<!-- CR-1289_GA4のパラメータ埋め込み Add End -->
<meta charset="utf-8" />
<title data-rh="true">カレー|レトルトカレー 通販 | 無印良品</title>
<meta data-rh="true" name="version" content="1.5.2805"/><meta data-rh="true" name="google-site-verification" content="criVNebOwB1UD6hqG8U7Zz085qW_LxuAc_be6YuFVbA"/>
<meta data-rh="true" name="description" content="レトルトカレーの通販なら無印良品 公式ネットストア。本場の味に学んだ具材感たっぷりのカレーが、インド・タイ・日本のラインナップで登場。温めるだけで、手軽に家庭で楽しめます。バターチキンやグリーンカレーをはじめとした、素材を生かしたカレーシリーズをご用意しています。"/>
~~~ 中略 ~~~
<script async data-chunk="customApp-components-shared-footer-footer" src="/jp/ja/store/static/1.5.2805/js/1843.25e35af8.chunk.js"></script>
<script async data-chunk="customApp-components-shared-footer-footer" src="/jp/ja/store/static/1.5.2805/js/customApp-components-shared-footer-footer.bffd0c76.chunk.js"></script>
</body>
</html>
実際に見ているページの情報と何かが異なります.商品名や画像などの情報が見当たりません.requestsとBeautifulSoupではスクレイピングが難しい状況になることが推測されます.
動的なwebページのスクレイピングをするのに便利なライブラリがSeleniumです.以降では,Seleniumの基本的な使い方(htmlの取得,スクロールの制御)とともに,実践的なスクレイピング方法を紹介していきます.
利用するライブラリ
pip install selenium
pip install beautifulsoup4
pip install lxml
1. Selenium
Seleniumはライブラリをインストールするだけでは動作しないのが難点です.ブラウザーをPythonで起動するまでの詳細については,次の記事が参考になります.先人の記事を利用しましょう.
Firefoxのドライバーは,下記サイトから対応するOSのものをダウンロードしてください.
無印良品のレトルトカレーに関するURLをFirefoxで表示するさせてみます.レトルトカレーのページ内容と同一のものを表示するコードは次のようになります.
from selenium import webdriver
driver = webdriver.Firefox()
url = "https://www.muji.com/jp/ja/store/cmdty/section/S3000901"
driver.get(url)
driver.quit()
実行後,ブラウザーが起動してレトルトカレーのページ
が表示されたあと,しばらくすると,ブラウザーが閉じるはずです.
2. ウインドウの非表示とHTML取得
2.1 ウインドウ非表示で起動
本質的には, の情報だけが必要なので,Firefoxのウインドウを起動させる必要はありません.ウインドウを非表示とHTMLの取得作業に移ります.ウインドウ非表示とHTML取得のポイントは次の2つです.
の情報だけが必要なので,Firefoxのウインドウを起動させる必要はありません.ウインドウを非表示とHTMLの取得作業に移ります.ウインドウ非表示とHTML取得のポイントは次の2つです.
ウインドウ非表示:--headlessオプション
HTML取得: driver.page_source
具体的には,次のようなコードになります.
from selenium import webdriver
# オプションを指定する
from selenium.webdriver.firefox.options import Options
# Firefox オプションを設定 ウインドウ非表示モード(--headless)
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
# driver = webdriver.Firefox() # ウインドウを表示させる時
url = "https://www.muji.com/jp/ja/store/cmdty/section/S3000901"
driver.get(url)
# ページソースを取得
html = driver.page_source
print(html)
driver.quit()
ウインドウの表示・非常時は,webdriverのオプションの引数に,--headlessを指定するのが基本となります.
ウインドウ非表示の基本形
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
その他のオプションについては,
公式のページが参考になります.(実際に,リンク先に進むとわかるのですが,firefox特有のオプションについては,更に,Mozillaのページを見よとなっています![]() )
)
2.2 HTMLの取得
該当のURLのHTMLは,page_sourceで取得できます.
HTMLの取得の基本形
url = "https://xxx.xxx.xxx"
driver.get(url)
html = driver.page_source
htmlを内容を表示させると,該当URLの中身が表示されます.冒頭とは異なり,webページに表示されている内容が取得できています.北インドのたまごカレー,消費税込490円の情報も見つけられます.
~~~ 略 ~~~
<picture>
<source media="(max-width:750px)" srcset="https://www.muji.com/public/media/img/item/4550584336003_400.jpg?im=Resize,width=400">
<img src="https://www.muji.com/public/media/img/item/4550584336003_400.jpg" width="400" height="400" loading="lazy"
alt="【肉不使用】【2辛】素材を生かした 北インドのたまごカレー" class="co-productsList__itemImg">
</picture>
</div>
.... ....
<span class="">消費税込 </span>
<span class="price">490</span> 円</span>
~~~ 略 ~~~
3. スクロール
レトルトカレーのwebページは,スクロールして徐々に情報を表示していく形になっています.そのため,html = driver.page_sourceだけでは,すべての情報を取得することができません.
少しだけ工夫が必要になります.今回はスクロールする仕掛けを仕込んですべての情報を取得するように調整してみます.
1画面分をスクロールするには,
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
というJavaScriptとPythonの合わせ技のようなものを利用します.
- driver: SeleniumのWebDriverオブジェクト
- execute_script(): JavaScriptを実行するためのメソッド
- "window.scrollTo(0, document.body.scrollHeight);" : JavaScriptのコード.ブラウザウインドウが現在のページの最下部までスクロール(1画面分スクロール)するという意味2
このコードを繰り返し実行して,スクレイピング対象のページの最下部までスクロールして,ページの内容を取得していきます.
私の環境では,5回ほどで最下部までスクロールできました.5回繰り返す形でコードを記述してみます.具体的には,
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
import time
url = "https://www.muji.com/jp/ja/store/cmdty/section/S3000901"
# ウインドウ非表示
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
# urlをブラウザーでウインドウ非表示モードで開く
driver.get(url)
#-------------------------------------------------------------------------------
# 新しく追加された部分
# JavaScriptを使用して画面全体をスクロールする
# スクロール回数を増やして,最後までページをロードさせることがポイント
for _ in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1) # スクロールの間隔を調整するために適切な待ち時間を設定
#-------------------------------------------------------------------------------
# ページソースを取得
html = driver.page_source
driver.quit()
ちなみに,driver.maximize_window()によってウインドウを最大化できるみたいです.このようにすればもう少し,スクロール回数を減らせるかもしれません.
4. HTMLの解析と情報取得
四角で囲んだ部分の商品の名称,辛さ指標,税込価格を取得して,データフレームに収めたいと思います.
HTMLまで取得できているので,基本的にBeautifulSoupを利用して必要な部分を抽出する作業となります.
<div class="itemView__ItemWrap-sc-1wbgu9x-2 hpinPe">
<div class="itemView__DivHover-sc-1wbgu9x-4 ehLdsT">
<a href="/jp/ja/store/cmdty/detail/4550584336003" draggable="false">
<div style="margin-bottom: 10px;">
<div class="itemView__Title-sc-1wbgu9x-3 WZTWQ titleHover">【肉不使用】【2辛】素材を生かした 北インドのたまごカレー</div>
</div>
<div class="price__StyledPrice-sc-hs11zb-0 eVHzTp"><span class="">消費税込 </span>
<div class="price__PriceWrap-sc-hs11zb-4 elfQoA">
<span class="price__OldPriceValue-sc-hs11zb-2 itMAtv">
<ins class="price__PriceValue-sc-hs11zb-1 hLA-DJK"><span class="">
<span class="price">490</span> 円</span>
</ins>
</span>
</div>
</div>......
【基本方針】
- 画像ごとにカレーデータがまとまっていることに注目します.find_allでまとまり部分をリストとして抽出します.
- 各データごとに,商品の名称,辛さ指標,税込価格を抽出します.
- 数量限定や肉不使用などの追加情報がある場合は,特記事項として抽出します.
取得したHTMLを眺めて3,カレーデータのまとまりは,
<div class="itemView__ItemWrap-sc-1wbgu9x-2 hpinPe">
商品名
辛さ指標
税込価格
</div>
となっていることがわかります.(ブラウザの右クリックメニューから関係する部分を調べる方法でも良さそうです.)
BeautifulSoupのfind_allを利用して,カレーごとにリストを作成します.divタグで,class属性がitemView__ItemWrap-sc-1wbgu9x-2という情報を利用します.
soup = BeautifulSoup(html, "html.parser")
tag_list = soup.find_all("div", class_="itemView__ItemWrap-sc-1wbgu9x-2")
print(tag_list[0])
# <div class="itemView__ItemWrap-sc-1wbgu9x-2 hpinPe">
# <div class="itemView__DivHover-sc-1wbgu9x-4 ehLdsT">
# <a draggable="false" href="/jp/ja/store/cmdty/detail/4550584336003">
# <div style="margin-bottom: 10px;">
# <div class="itemView__Title-sc-1wbgu9x-3 WZTWQ titleHover">【肉不使用】【2辛】素材を生かした 北インドのたまごカレー</div>
# </div>
# <div class="price__StyledPrice-sc-hs11zb-0 eVHzTp"><span class="">消費税込 </span>
# <div class="price__PriceWrap-sc-hs11zb-4 elfQoA"><span class="price__OldPriceValue-sc-hs11zb-2 itMAtv"><ins class="price__PriceValue-sc-hs11zb-1 hLA-DJK"><span class=""><span class="price">490</span> 円</span>
# </ins>
# </span>
# ...
該当箇所から,次の要素を順番に抽出していきます.
| 列名 | 内容 |
|---|---|
| 商品名 | 素材を生かした 北インドのたまごカレー |
| 辛さ | 2辛 |
| 価格 | 490円 |
| 特記事項 | 肉不使用 |
正規表現とBeautifulSoupのテキスト抽出機能を利用して,データフレームへ変換します.【特記事項】【辛さ】の部分から特記事項や辛さを探すなどの細かい内容は割愛します.4最終的なコードは次のような形になります.
# Selenuim+Firefox
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
import time
# htmlの解析とデータフレームへ
from bs4 import BeautifulSoup
import re
import pandas as pd
# 無印良品レトルトカレー紹介ページ
url = "https://www.muji.com/jp/ja/store/cmdty/section/S3000901"
# Firefox オプションを設定
# ウインドウ非表示
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get(url)
# JavaScriptを使用して画面全体をスクロールする
# 最後までページをロードさせることがポイント
for _ in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1) # スクロールの間隔を調整するために適切な待ち時間を設定
# ページソースを取得
html = driver.page_source
driver.quit()
#------------------------------------------------------------------------
# 取得したhtmlから情報を抽出
soup = BeautifulSoup(html, "lxml")
# カレーデータごとのまとまり
item_tags = soup.find_all("div", class_="itemView__ItemWrap-sc-1wbgu9x-2")
name_list = [] # 商品名
note_list = [] # 特記事項
spiciness_list = [] # 辛さ
price_list = [] # 税込価格
for item in item_tags:
# 商品名を取得
item_name = item.find('div', class_='itemView__Title-sc-1wbgu9x-3').text.strip()
# 特記事項を正規表現で抽出
special_note_pattern = r'\【(.*?)\】【'
special_note_match = re.search(special_note_pattern, item_name)
special_note = special_note_match.group(1) if special_note_match else None
# 辛さを正規表現で抽出
spiciness_pattern = r'\【([0-9]+)辛.*\】'
spiciness_match = re.search(spiciness_pattern, item_name)
print(spiciness_match)
spiciness = spiciness_match.group(0).strip("【").strip("】") if spiciness_match else None
print(spiciness)
# 商品名から特記事項と辛さを削除
cleaned_pattern = r'\【(.*?)\】'
cleaned_item_name = re.sub(cleaned_pattern, '', item_name).strip()
# 価格を取得
price = item.find('span', class_='price').text.strip()
price = f"{price}円"
# 抽出したデータをリストへ追加
name_list.append(cleaned_item_name)
note_list.append(special_note)
spiciness_list.append(spiciness)
price_list.append(price)
df = pd.DataFrame(
{"商品名": name_list,
"辛さ": spiciness_list,
"価格": price_list,
"特記事項":note_list})
df.to_csv("curry_data.csv", index=False)
保存したcurry_data.csvを表示すると,冒頭の表が完成します.
スクレイピングに関する他の紹介記事
BeautifulSoupの実践的な利用方法については,次の2つを参考にしてもらえると幸いです.
注
-
画像表示を追加すればwebページそのものという本末転倒ぶりは横においておきましょう. ↩
-
JavaScriptは久しぶりなので,自分用に書いておく.
・window.scrollTo():ブラウザウィンドウのスクロール位置を指定
・0: 水平方向のスクロール位置を0に設定
・document.body.scrollHeight: 垂直方向のスクロール位置をページの高さ(document.bodyの高さ)に設定.これでページの最下部までスクロール. ↩ -
取得したHTMLで関連する部分は,1行になっています.書式を整えてくれるHTML formatterを利用して見やすく整理すると構造が見えてきます. ↩
-
他のスクレイピングの記事を参照してもらえると嬉しい限りです. ↩