こんにちは。今回はSelectコンポーネント以外の変換機能の使い方を紹介します。


1. Sort
並べ替え行う機能です。
2. Rank
ランクを設定する機能です。
RankかDense Rankを指定でき、それぞれで以下のように結果が異なります。
| sorted field | rank | dense rank |
|---|---|---|
| 'a' | 1 | 1 |
| 'a' | 1 | 1 |
| 'b' | 3 | 2 |
3. Limit
取得するデータ件数を制限をする機能です。SQLのTopとかLimitの機能になります。
Limitにはパーティションの設定が可能で、これを使うことで注文データについて、顧客ごとに最も新しい注文日の注文データを1件ずつ取得することが可能です、

4. Window
Window関数を利用した集計などに使うことができます。
変わった使い方としては、顧客ごとに注文伝票を注文日順に古いものから順に並べて番号を降る時などに使います。
ここでセットされた番号(Row Number)により、顧客ごとの初回注文や2回目の注文などのデータを判別することができます。

5. Sample
データからテキストボックスに設定したパーセンテージにしたがってランダムでレコードを返します。
6. Join
SQLのJOINと同じ機能です。
7. Cross Join
SQLのCross Joinと同じ機能です。
8. Clone
データを2つ以上の処理に分岐する際に使用します。

9. Filter
SQLのWhere句です。
10. Assert
データの品質管理のために利用します。
データが指定した条件に合致した場合、ジョブをエラー終了します。レコードが指定された条件に合致する場合、ジョブはエラーとなり、「Error message:」テキストボックスに設定されたエラーメッセージがログに出力されます。

Conditionsの設定オプション:
- Match all of the following conditions (AND) - 指定されたすべての条件に一致する値を持つレコードを選択(論理的な「AND」)
- Match any of the following conditions (OR) - 指定された条件(論理的な「OR」)の少なくとも1つを満たす値を持つレコードを選択
- Match none of the following conditions (NOT) - 指定された条件のいずれにも一致しない値を持つレコードを選択します(NOT(OR))
11. Aggregate
SQLの集計関数とほぼ同じ機能です。
1つ以上のフィールド名を指定し、それに応じてグループ化された集計結果が返されます。

Aggregateで利用できる集計関数について:
集計関数としては以下が利用可能です。
| 集計関数 | 説明 |
|---|---|
| Count | Grouping Fieldに応じて、フィールド列で指定したフィールドの非Null値の数を返します。戻り値のデータ型はlong型です。 |
| Count Distinct | Grouping Fieldに応じて、フィールド列で指定したフィールドの一意の値の数を返します。戻り値のデータ型はlong型です。 |
| Count All | Grouping Fieldに応じてレコードの数を返します。戻り値のデータ型はlong型です。 |
| HyperLogLog | HyperLogLog ++アルゴリズムを使用して、Grouping Fieldに応じて、指定されたフィールドのカーディナリティー推定値または個別の値のおおよその数を返します。戻り値のデータ型はlong型です。 |
| Average | Grouping Fieldに応じて、Field Argumentで指定した数値フィールドの平均を返します。戻り値のデータ型については、次の表を参照してください。 |
| Sum | Grouping Fieldに応じて、Field Argumentで指定した数値フィールドの合計を返します。戻り値のデータ型については、次の表を参照してください。 |
| VAR | Field Argumentで指定したフィールドのすべての値について、Grouping Fieldに応じて統計的分散を返します。戻り値のデータ型はdouble型です。 |
| Collect | Collect関数はGroup化項目にしたがって、値を集計するのではなく、各値をBag型で1行に集約する機能です。 |
| Max | Grouping Fieldに応じて、Fieldで指定したフィールドの最大値を計算します。戻り値のデータ型は、入力引数のデータ型と同じです。 |
| Max By | Field Argumentで指定したフィールドが最大値の場合、Grouping Fieldに応じて、Projected Fieldで定義された値を返します。戻り値のデータ型は、Projected Fieldのデータ型と同じです。 |
| Min | Grouping Fieldに応じて、Field Argumentで指定したフィールドの最小値を返します。戻り値のデータ型は、入力引数のデータ型と同じです。 |
| Min By | Field Argumentで指定したフィールドが最小値の場合、Grouping Fieldに応じて、Projected Fieldで設定された値を返します。戻り値のデータ型は、Projected Fieldのデータ型と同じです。 |
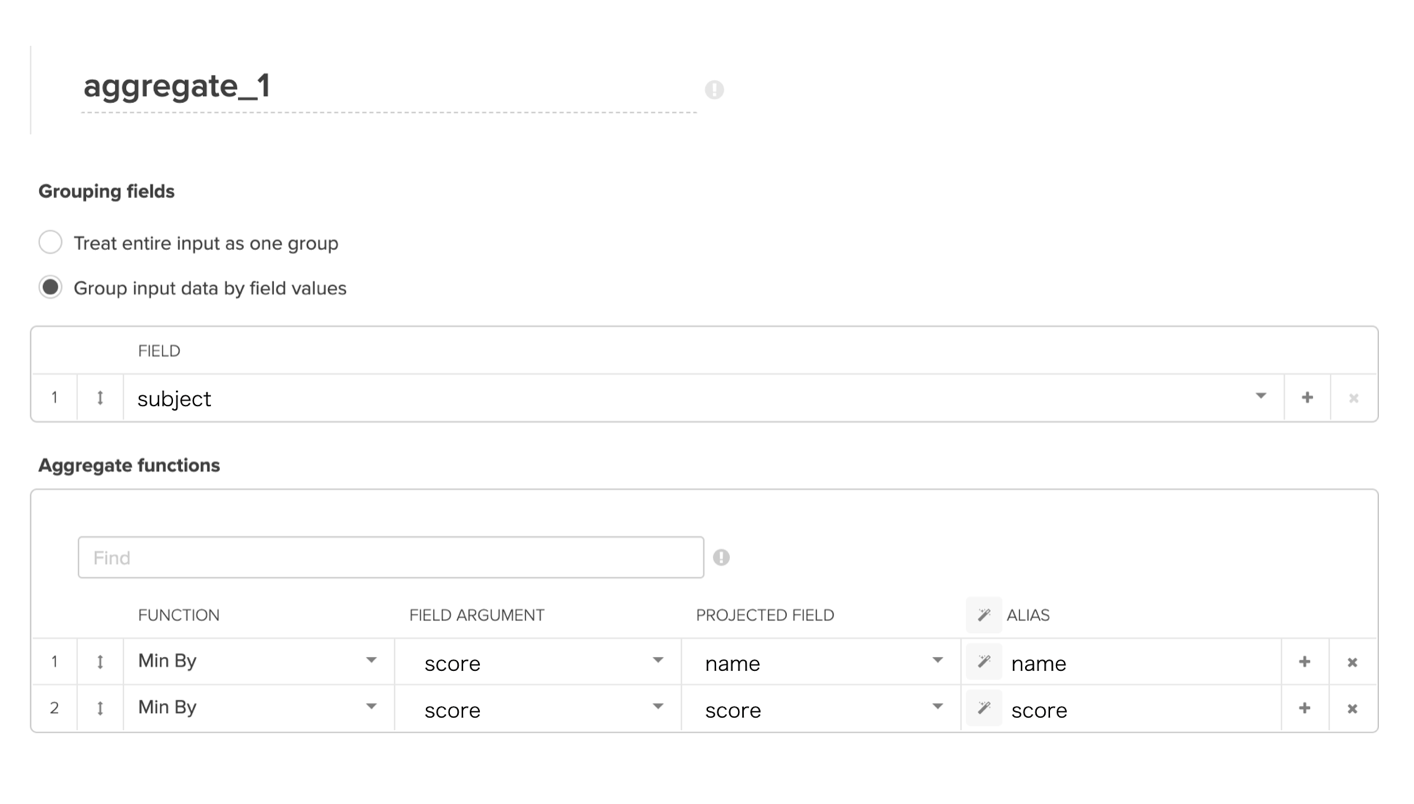
Min Byの使い方
例えば、各科目で一番点数の低い生徒の氏名を求めたい場合、Fieldには、科目名、Field Argumentには点数、Projected Fieldには生徒の氏名をセットします。この場合の出力結果に含まれるフィールドは、科目名と生徒の氏名となります。*以下のようにMin Byで複数項目を出力することも可能です。
Collectの使い方
-
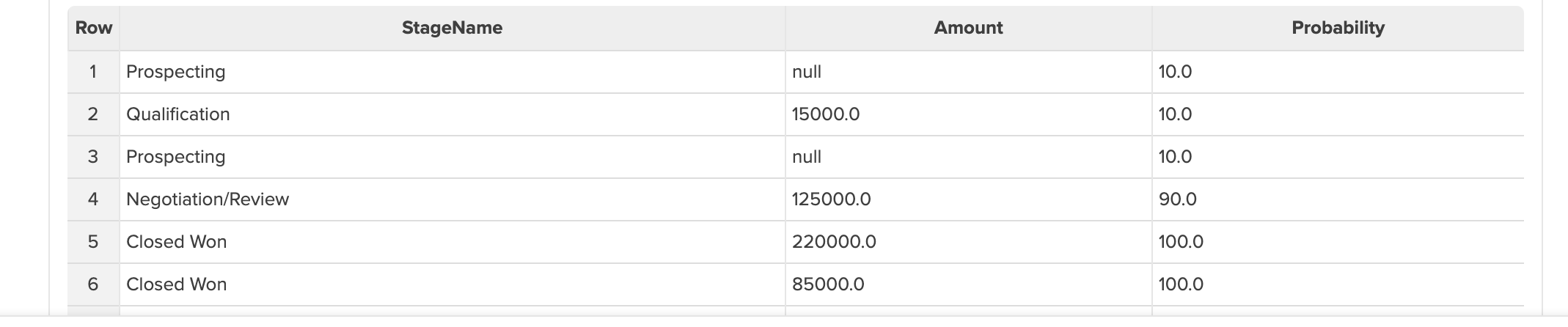
使用データ
例えば、以下のようなデータがあるとします。
-
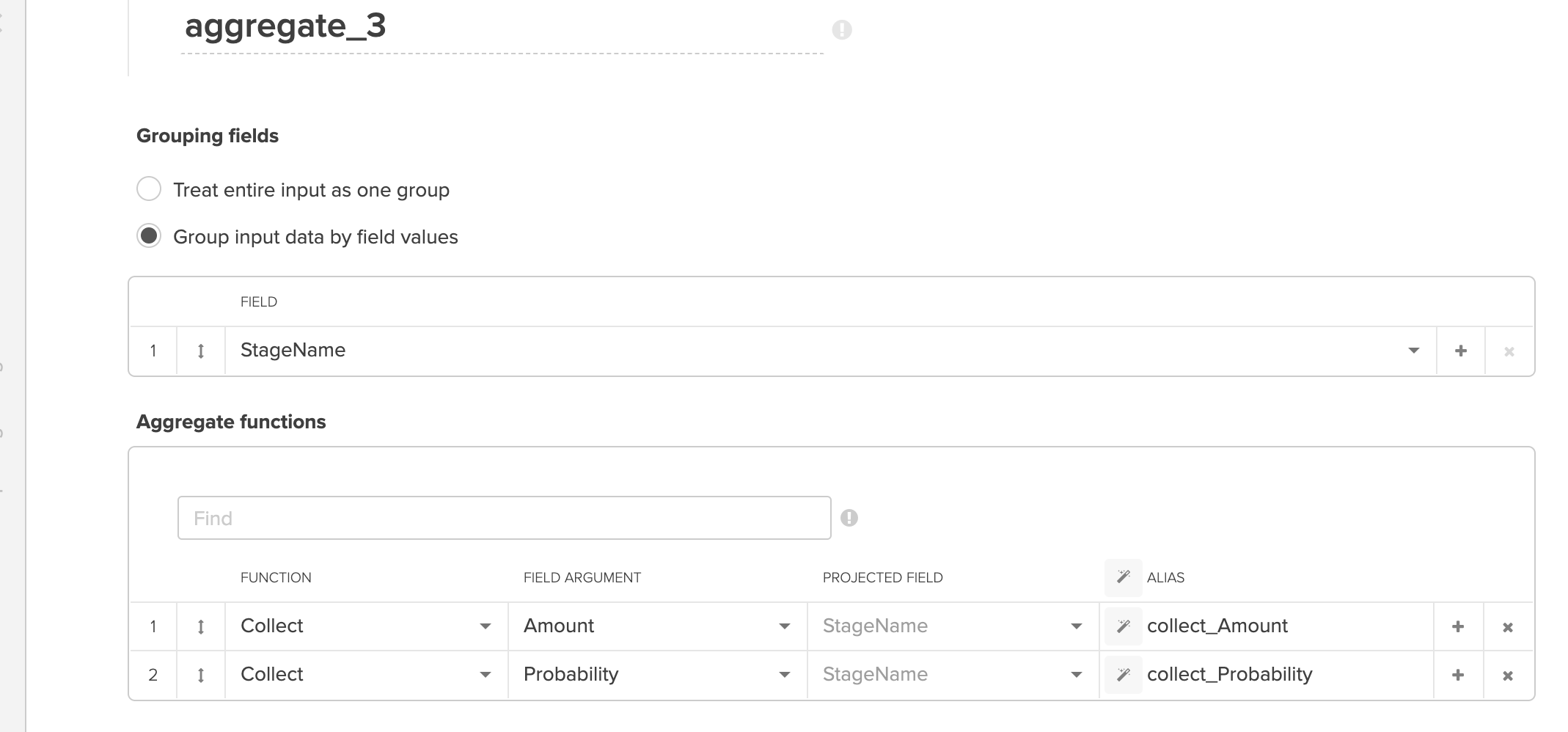
Collectの設定
これをAggregateのCollectを使用して、集約を行うよう設定します。
-
結果
変換すると、指定したグループ化項目である「Stage Name」別に数値や文字列をBAG型に変換します。
| StageName | Amount | Probability |
|---|---|---|
| Prospecting | [{"Amount":null},{"Amount":null}] | [{"Probability":"10"}, |
| Qualification | [{"Amount":"15000"}] | [{"Probability":"10"}] |
| Negotiation/Review | [{"Amount":"125000"}] | |
| Closed Won | [{"Amount":"220000"},{"Amount":"85000"}] | [{"Probability":"100"},{"Probability":"100"}] |
Collectでまとめた文字列フィールドから個別の値を抽出する場合
1. 上記AmountフィールドをJSON形式に明示的に変換する
field1 = ToJson(Amount)
4行目を変換した場合 ==> [{"Amount":220000},{"Amount":85000}]
2. Field1の文字列から個別の値を取得する
JsonExtractScalar(field1,'$.[0].Amount')
==> 220000
JsonExtractScalar(Field1,'$.[1].Amount')
==> 85000