前置き
こんにちは!データエンジニアの山口歩夢です。
SnowflakeにはLLMを活用するための機能が多くあります。
今回は、それらの機能について簡潔にまとめてみました!
本題
SnowflakeはLLM機能とML機能を提供しています。
本記事では、Snowflake CortexのLLM関連の機能に焦点を当て、その特徴と活用法について解説します。
Snowflake Cortex
Snowflake Cortexは、LLM(大規模言語モデル)を活用したAI機能群です。
非構造化データを理解し、自然言語での質問にも対応できる優れた特徴を持っています。
以下は、Snowflake Cortexで利用可能な主要な機能です。本記事ではこれらの機能についてできるだけ簡潔に解説していきます。
-
Snowflake Cortex LLM Functions
SQLを実行することで、LLMを活用してSnowflakeがサポートしているモデルに対して自然言語で質問したり自然言語のベクトル化ができる機能です。 -
Snowflake Copilot
SnowflakeのWorksheetsやNotebooks環境で、自然言語でクエリの生成や修正をアシスタントしてくれる機能です。 -
Document AI
非構造化データ(例:PDFや画像ファイル)を解析し、テキストを抽出してデータベースに取り込むことができる機能です。 -
Cortex Fine-tuning
SQLを実行することで、自社のデータやユースケースに合わせて、Snowflakeが提供するLLMをファインチューニングできる機能です。 -
Cortex Search
自然言語で質問することで、Snowflakeデータの中から必要な情報を迅速に検索できる機能です。こちらを活用することで、ハイブリッド検索の機能を実装することができます。 -
Cortex Analyst
自然言語で質問をすることで、yamlに書いたテーブルやメタデータの定義について自然言語やSQLで回答を得ることができる機能です。
Snowflake Cortex LLM Functions
Snowflake CortexのLLM関数を利用することで、SQLを実行してLLM(大規模言語モデル)を簡単に活用できます。
Snowflake内でSQLクエリを実行するだけで、AIを使った自然言語処理が可能になります。
Snowflake Cortexでは、GoogleやMetaといった企業の研究者たちによって開発されたLLMモデルに加え、Snowflake Arcticと呼ばれるSnowflake独自のLLMにもアクセスすることができます。
使い方
本記事では、COMPLETE関数というものを使ってみます。
使用するモデル名と、自然言語での質問を以下のように渡して実行するだけです。
SELECT SNOWFLAKE.CORTEX.COMPLETE('mistral-large', 'Snowflakeについて教えてください。')

Snowflake Copilot
Snowflake Copilotは、Snowflake上のテーブルを用いたデータ分析を簡素化するLLM(大規模言語モデル)アシスタントです。
この機能を利用することで、自然言語を使ってデータ分析を行えるため、従来のようなSQLの専門知識がなくても直感的にデータを操作できます。
SnowsightのWorksheetsやNotebooks環境で自然言語で質問を入力することで、即座に回答を得ることができます。
使い方
まずは、Worksheetsの右下の「Ask Copilot」をクリックします。

次に、Chatbotが出てくるのでこちらに自然言語で問い合わせをします。
すると、このように回答を返してくれます。
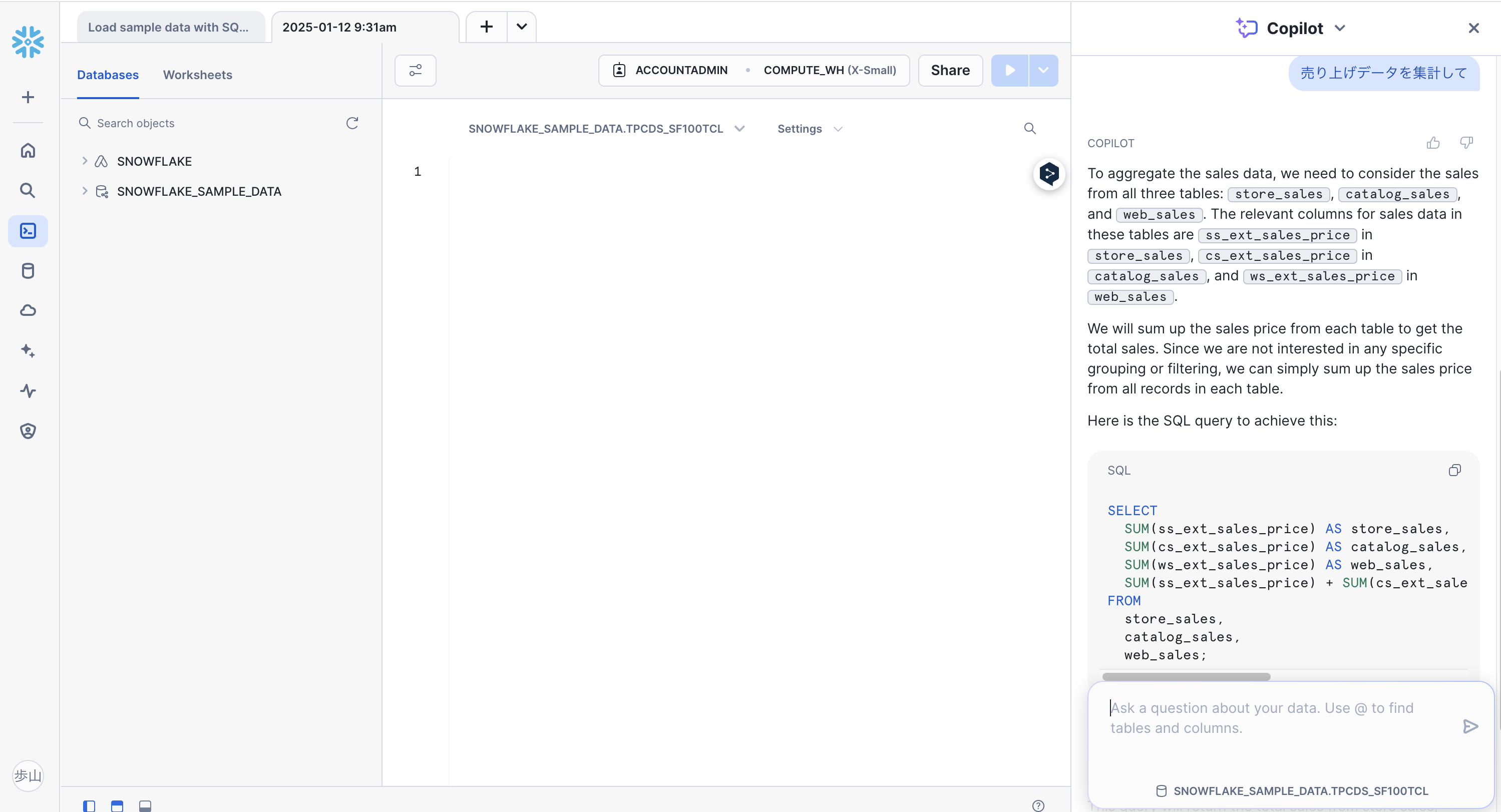
日本語での質問を受け付けてはくれますが、回答は英語でした。
まだ、本記事執筆時点では、日本リージョンをサポートしていないので、日本語対応まではもう少し待つ必要がありそうです。
Document AI
PDF、JPEG、PNG、HTMLなど、さまざまな非構造化データを処理し、その中から必要な情報を構造化データとして抽出するAI機能です。
この機能を使えば、これまで扱いづらかったファイル形式のデータもSnowflakeのテーブルに取り込むことが可能になります。
このAI機能は、Snowflake独自のLLMである「Arctic-TILT」を活用しています。Arctic-TILTは、非構造化データの解析に特化したモデルで、特にドキュメントからの情報抽出に高い精度を発揮します。
また、このモデルはファインチューニング(Fine-tuning)にも対応しており、業界固有の用語や社内特有の表現に合わせてモデルをトレーニングすることができます。
非構造化データであるドキュメントをテーブルに変換する際などに推奨されているため、社内ドキュメントなどをRAGとして使用したい時などにも有用だなと感じました。
日本リージョンに対応しているようですが、まだ日本語の非構造化データの処理は苦手なようです。
使い方に関しては、こちらの記事が勉強になりました。
Cortex Fine-tuning
Snowflake上で提供される完全マネージド型のファインチューニングサービスです。
従来のLLM(大規模言語モデル)のファインチューニングにかかるコストや時間を抑えながら、特定の業務領域に適したモデルを構築できる機能を提供します。
この機能を使えば、既存のLLMをユーザー独自のデータを基に調整し、より精度の高い応答を得ることが可能になります。
FINETUNE関数を使用することで、SQLでファインチューニングを行うことができるようです。
使い方に関しては、こちらの記事が勉強になりました。
Cortex Search
Snowflake上のデータに対して、低遅延かつ高品質なあいまい検索を実現します。
これにより、大規模なデータセットに対しても高速で精度の高い検索が可能になります。
主な活用シーンとしては、Chatbot向けのRAG(Retrieval Augmented Generation)エンジンとしての利用や、アプリケーション内の検索機能のバックエンドとしての利用があります。
前述した、Snowflake Cortex LLM Functionsと組み合わせることで、以下のようにハイブリッド検索(ベクトル検索とキーワード検索を組み合わせた検索) を可能にして、LLMの回答の精度を高めることが可能です。

使い方に関しては少々複雑そうに感じたので、
別記事などでアウトプットしたいなと考えています。
Cortex Analyst
Snowflakeのテーブルデータに、自然言語で質問し、SQLを使わずに即座に回答を得られるようにする、LLM(大規模言語モデル)機能です。
REST APIを通じて簡単に既存のアプリケーションに統合でき、SQLクエリを生成する際には最新のLLM(Meta Llama、Mistral、OpenAI GPT)を活用します。
yamlファイルでテーブルやカラムの意味を定義することでSnowflakeにデータについて理解させることができます。(これを「セマンティックモデル」と呼びます。)
使い方
使い方に関しては、以下の記事が勉強になりました。
まず、yamlファイルでテーブルやカラムの意味などを定義して、Cortex Analystにデータについて理解させます。
そして、StreamlitなどからREST APIでSnowflakeに通信をしてデータについての質問を投げて回答を得るなどの使い方がありそうです。
まとめ
今回は、SnowflakeのLLM機能群についてまとめてみました!
今年はStreamlitでLLMに関連したアプリケーション開発やアウトプットを頑張っていきたいなと思っています。
宣伝
先日、Streamlitの書籍を出版しました。
LLM関数とStreamlitを活用した簡単なChatbot開発についても解説させていただきましたので、是非チェックしてみてください!