今回の課題
Snowflakeを通してデータ活用をする際の、データの流れのパターンを理解する。
下記の動画で紹介されていたアーキテクチャを参考に調査して勉強をしてみた。
※紹介されていたアーキテクチャ
データ活用時のデータ基盤の構成について
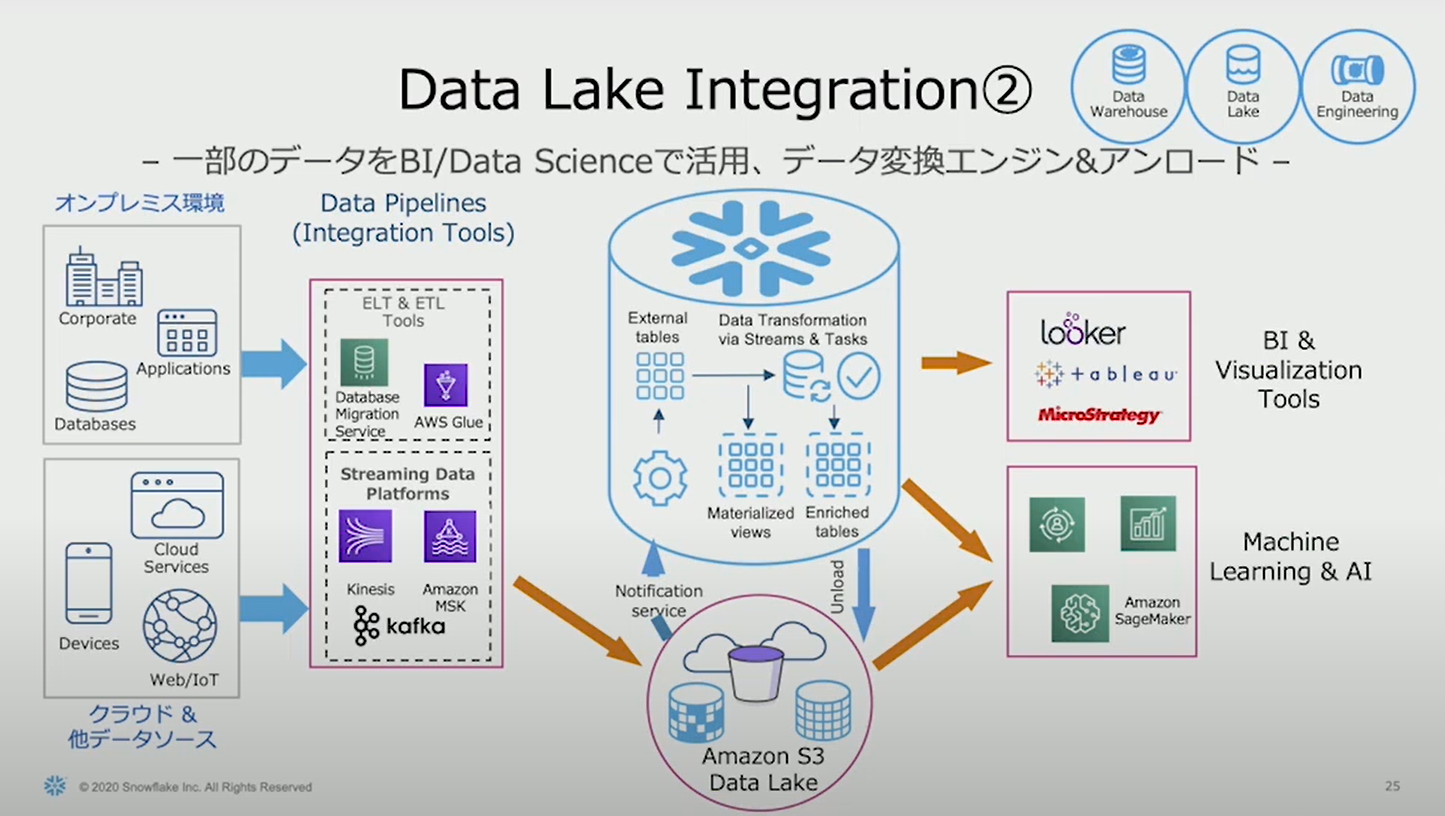
上記のアーキテクチャでは、大きく分けて3パターンのデータの流れが紹介されていた。
1)Snowpipeなどを使用してSnowflakeに格納したデータをBIツールと連携
S3から、Snowpipeなどを使用してSnowflakeにデータをロードしてテーブルを生成し、
そちらをBIツールやAmazon SageMakerなどに連携する基本的な使い方。
2)Snowflakeの外部テーブル機能でS3のデータを参照し、それらをBIツールやAmazon SageMakerと連携
外部テーブルとは、読み取り専用でS3などの外部のストレージのデータに、Snowflakeからアクセスすることができる機能。
Snowflake内にテーブルを生成しなくても、Snowflakeの外部テーブル機能でS3などのストレージにあるCSVやParquetファイルを読み込み、
それらをBIツールやAmazon SageMaketに連携することで、1)と同様にデータを活用することができる。
また、S3のデータをSnowflakeに外部テーブル機能で読み込み、
それらを加工して新たなテーブルを生成して、データ活用したり、S3にデータをアンロードするといったことも可能。
3)S3から直接AmazonSageMakerに連携する。
Snowflakeを通さず、AWSのサービスでデータ活用をすることも可能。
まとめ
SnowflakeとAWSをデータ基盤として使用する際に、
1)のようにデータレイクからSnowflakeにデータをロードして生成したテーブルを活用するということ以外にも、データ活用時に行える方法があることを学べた。