あるテキストファイルから各列を抽出する方法をまとめておく。
ポイントとして、今回扱うテキストファイルは項目ごとにカンマで区切られていない。(スペースで区切られている。)
また列(カラム)の名前がない。
data.txt
-4.27664 2.32979
4.31421 6.18227
-2.71355 4.94826
-0.969893 6.99936
0.919589 9.9744
このデータを1列目がx, 2列目がyの5行2列のデータとして認識させたい。
結論
import pandas as pd
df = pd.read_csv("data.txt", delim_whitespace=True, names=('x','y'))
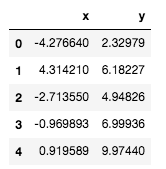
以下で詳しく説明する。
pandasのread_csvを用いてデータを読み込む
import pandas as pd
df_1 = pd.read_csv("data.txt")
print(df_1)
このままだとdf_1は、カラム名が-4.27664 2.32979の4行1列のデータとなってしまう。
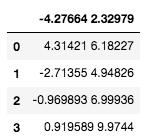
スペースを区切り文字に指定する
delim_whitespaceをTrueにすることでスペースを区切りとして認識させることができる。
df_2=pd.read_csv("data.txt", delim_whitespace=True)
print(df_2)
これにより、df_2は2列のデータとして認識させることができた。
ただし、このままではカラムの名前がそれぞれ-4.27664, 2.32979の4行2列のデータとなってしまう。
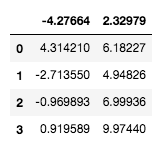
※ 区切り文字の指定については他にもsep, delimiterなどがある。
参照:https://deepage.net/features/pandas-readcsv-deep.html
カラム名を設定する
namesによって2列のカラム名をそれぞれx, yと設定する。
df_3=pd.read_csv("data.txt", delim_whitespace=True, names=('x','y'))
print(df_3)
これにより、1列目がx, 2列目がyの5行2列のデータとして認識させることができた。
補足
x列のデータ、y列のデータはそれぞれ以下のようにして取り出すことができる。
これは列ごとの合計や平均、またxとyの共分散などを求める際に便利である。
df["x"]
df["y"]