意気込み:6/17日の統計検定にむけてがんばるぞい!
2級と準1級を目標にしています。
統計学が発達した背景
統計学が発達した要因は人間及び社会の活動から起こり、その活動で得られた知識が融合して大きな理論体系が出来上がった。
具体的に言うと
①ゲームのテーブルから起こった確率論
②常備軍や国家財政上の必要から起こった国家状態の統計
③古代地中海貿易での、海上保険の計算
④ペストをきっかけとする死亡率表の研究
などである。
Advanced Theory of Statistics という本に統計学が発達した要因が詳しく書かれているのでいつか読んでみようと思う。
ここで重要なことは現象の法則性に対する人間の関心が統計学を生み出したということです。
例えば③海上保険において「難波事故は何月に発生しやすいか?」や④ペストにおいて「どのような人間あるいはどの国が死亡する確率が高いか」といういずれも傾向や法則を知りたいニーズがあって統計学が発達したことが言えます。
記述統計学と推測統計学
現象の法則性を知るために、すべてを(例えば日本国全員の高校生の得点)調査してそこから日本人高校生の得点の傾向・法則を発見する→記述統計学
現象の法則性を知るために、一部を(例えば新宿区全員の高校生の得点)調査してそこから日本人高校生の得点傾向・法則を発見する→推測統計学
記述統計学で代表的なものは**国勢調査**であり、全数調査の原理にそって行われています。
そして歴史的にみて、統計は国家の状況を歴史的に記述するものであったのです。詳しくはこちらを参考に。
近代統計学の確率
ケトレー(1796-1874)は全ての人間集団には「平均」という型があり、個人差はあっても最もよく観察されるのは「平均」であるといった。先の国勢調査のような大量観察は一定の普遍性をもった法則をもたらす。
メモ:
ピアソンによって近代統計学理論の基礎が定まった。積率相関係数を導入したので、飛躍的に統計学が発展した→標本と母集団が区別されるようになった。
フィッシャーによって推測統計学の論理が築かれた。仮説検定及び推定、分散分析、実験計画法。
質的データと量的データ
説明は割愛します。Pythonで質的データと量的データの要約統計量を出したいなら、
# dfはデータフレーム
df.describe() #量的データのみの要約統計量
df.describe(include=['O']) #質的データのみの要約統計量
df.describe(include=['all'])#すべての要約統計量
と記述すれば大丈夫です。
時系列データとクロス・セクション・データ
同一の対象の異なった時点での観測値データを時系列データ
異なった対象の同じ時点での観測値データをクロスセクション・データ
時系列データとクロスセクション・データを合わせたものをパネルデータ
と呼ぶ!
実験及び調査プロセス
①仮説と分析する対象を決める。また全数調査か標本調査か定義する。
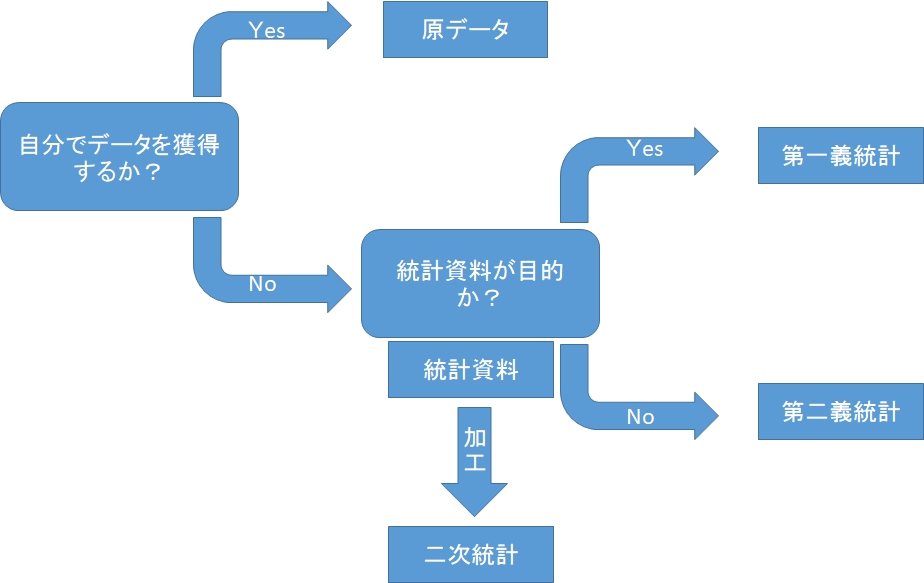
②実験あるいは調査によって原データを獲得する。
因みにデータ獲得の作業を自然科学では実験と呼び人文・社会科学分野では調査と呼ぶ
統計資料
実験・調査は費用と時間がかかるので、国や研究機関といった第三者が行った調査結果を統計データとして利用することが多く行われる。その統計データは統計資料と呼ばれる。
統計資料は第一義統計と第二義統計の2種類に分類される。
第一義統計とはあらかじめ統計資料を作成する目的で調査を行いその結果を集計したものである。
(社会分野が主なので調査と表現している)
代表的な資料は国勢調査報告や事業所統計調査報告である。
第二義統計(または業務統計)は統計資料の作成が目的でない資料を集計して得た統計資料である。
代表的な資料は貿易統計・犯罪統計である。
また、統計資料を加工して作られた統計資料を二次統計と呼ぶ。
代表的なものは物価指数・国民経済計算。