はじめに
※本記事は2022年8月に新着レシピ分を記事に追加いたしました。
Axross Recipeを運営している松田です。
Axross Recipe は、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、Pythonプログラミングを活用して実際の業務に近いテーマで、動くものを作りながら学ぶことができます。
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/AxrossRecipe_SB

画像生成の仕組み
画像生成とは
画像生成(Image Generation) とは、機械学習の手法 ディープラーニング(深層学習)の利用用途の1つで、画像や映像などの自動加工や、絵画やデザインの生成を行う技術のことを指します。
画像生成の技術は、ディープラーニングの実務で、学習用データを集める際に良く使われます。
一例として、医療分野におけるディープラーニングの画像認識を用いたがん細胞の発見タスクを挙げます。
ディープラーニングの予測精度で最も重要な要素は、データの質を担保しつつ量を確保することです。そのため、モデルに学習させるためのサンプルデータとなるがん細胞の様々なパターンの画像を用意する必要があります。患者の過去の事例から、様々な形状、大きさ、色付き等のパターンのがん細胞のサンプルを見つけて、学習用データとして集めることはとても大変です。
この場合、画像生成の技術を活用することで、サンプルデータの量が不十分であった場合でも、サンプル画像から類似した特徴量の画像を生成し、学習用に使う膨大なデータを再現することができます。
その他にも、画像生成のビジネス活用例はいくつかあります。
・存在しない人物画像を生成し、企業パンフレット等の被写体として利用する
・製品や建築物、空間のデザインアートに利用する
・バーチャルYouTuber、バーチャルアイドルを自動生成する
・過去の歴史的資料から、当時の光景を再現する
画像生成の手法
現在用いられている画像生成の手法をいくつかご紹介します。
GAN(敵対的生成ネットワーク)
GAN(Generative Adversarial Networks) は、Generator(生成者)とDiscriminator(判定者) という2つのネットワーク構造に分けられます。Generatorは、偽物といえるデータをランダムなノイズから作り出していくという役割を担っています。Discriminatorは、Generatorで生成された偽物データを、本物データと比較していくことによって、そのデータが本物なのか偽物なのか判定していくという役割を担っています。2014年にイアン・グッドフェローらによって発表された教師なし学習で使用される人工知能アルゴリズムの一種です。
フェイスブック社のVP兼チーフAIサイエンティストであるヤン・ルカンは、GANについて、「機械学習においてこの10年間で最も興味深いアイデア」("This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.")と評価しており、GANはAIの今最も熱い研究分野とも言えます。

CycleGAN
CycleGANは、無関係な2枚の写真を使い、互いに変換し合う(特徴を似せ合う)ようにサイクル状のネットワークを構成する、2017年3月に発表されたGANモデルです。
名画と風景画像、人物画像とアニメ画像、同一画像の季節入れ替え 等関係ない画像同士を合わせ、それっぽく合成させた画像を生成することができます。

FACE AGING WITH CONDITIONAL GENERATIVE ADVERSARIAL NETWORKS
DCGAN
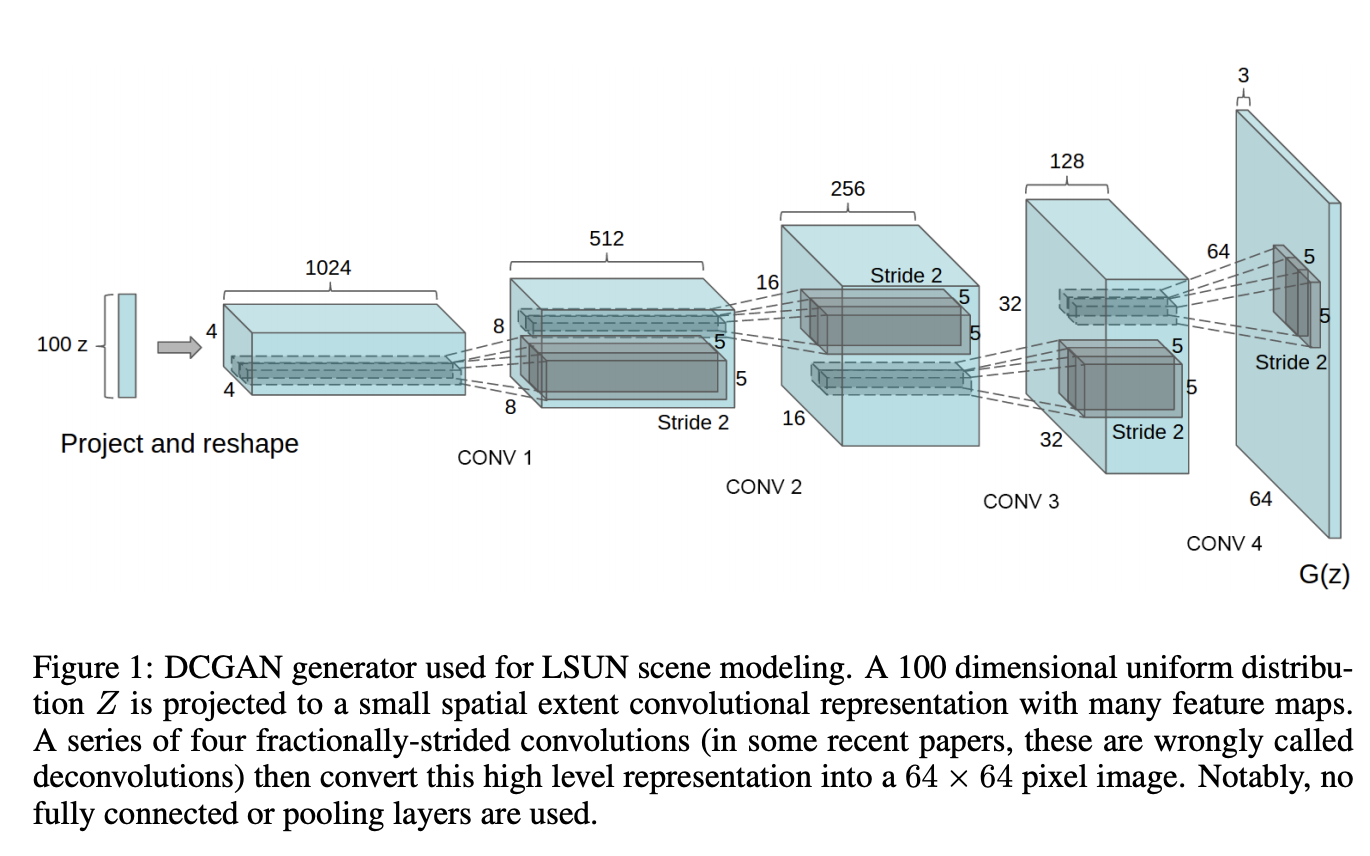
**DCGAN(Deep Convolutional GAN)**は、2015年にA.Radfordらによって発表された敵対的生成ネットワークの一種であり、生成ネットワーク(generator)と識別ネットワーク(discriminator)の2つのネットワークに畳み込みニューラルネットワーク(CNN)を用いたモデルのことです。
引用:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
StyleGAN
StlyeGAN2018年12月にNvidiaの研究者によって導入され、2019年2月にソース利用が可能となった生成的敵対的ネットワークです。
下記画像は一見写真のように見えますが、StyleGANによって生み出された画像です。全て存在しない人物なのです。
引用:A Style-Based Generator Architecture for Generative Adversarial Networks, NVIDIA Open-Sources Hyper-Realistic Face Generator StyleGAN, This Person Does Not Exist

DALL-E
DALL-Eは、OpenAI(オープンエーアイ)が2021年に発表した画像生成モデルです。任意のテキストを入力することによって、その内容に合わせた画像を生成することができます。このモデルは、大きく分けると2つのステージを経て作られます。
ステージ1は、画像の圧縮・復元モジュールの作成です。これには、Discrete VAE(離散変分オートエンコーダ)と呼ばれるモデルが使われていて、エンコーダがRGB 256×256の画像を32×32のパラメータに圧縮し、デコーダはそのパラメータを再び入力とほぼ同品質のRGB 256×256の画像に復元します。
ステージ2は、画像とテキストの対応関係の学習です。これには、Transformerと呼ばれるモデル(赤の点線で囲まれたEncoderの部分)が使われていて、画像情報(画像トークン)とその内容を説明するテキスト情報(テキストトークン)の対応関係を学習します。
下記画像は「アボカドの形をしたアームチェア」を元に生成された画像一覧です。

引用:DALL·E を5分以内で説明してみた-AINOW-
ディープラーニング使って画像生成を行うレシピ
今回は、Axrossのサービスで学べるレシピの中からAxross運営が厳選した、ディープラーニング使って画像生成を行うためのおすすめレシピ5選 をご紹介します。近年の画像生成の発展を学んでみたい方は是非Axross学習時の参考にしてみてください。
ご注意:画像生成技術を使って、人の顔を変化させる行為やデザインを合成する行為等は、個人の勉強の目的且つ正当な範囲内でご活用ください。プライバシー侵害・肖像権侵害・著作権侵害にならないようにご注意ください。
GAN
01_PyTorchを使ってGANを実装し画像生成するレシピ
投稿者:satoshi さん
PyTorchを使ってGANを実装し、実在しない画像データを生成することができるレシピです。
学習用の画像データとしてCIFAR10を使用しているため、他webサイトから画像ダウンロードする必要はありません。画像サイズは大きくないので、比較的少ない時間で学習を行うことができます。GANを実装した画像生成の第一歩を踏み出してみましょう!
02_CLIP+GANでテキストから画像を生成するレシピ
投稿者:12kaz さん
追加の学習を必要としない(ゼロショット)画像分類モデル「CLIP」とGANで構成されるFuseDreamの技術概要を解説し、実際にテキストから画像を生成する方法を学びます。
CLIP+GANアプローチは、トレーニング不要で、任意の入力テキストに対して特定のタスクへの追加の学習なく意味的に関連する画像を生成することができます。
03_CLIP+GANでテキストから動画を生成するレシピ
投稿者:12kaz さん
追加の学習を必要としない(ゼロショット)画像分類モデル「CLIP」とGANで構成されるFuseDreamの技術概要を解説し、実際にテキストから動画を生成する方法を学びます。
製品、建造物などデザインアートへの利用、自然言語表現で指定した画像を生成し広告への活用ができます。
DCGAN
04_Kerasで学ぶ画像生成モデルDCGANレシピ
投稿者:@kz_onkさん
GANとは何かを学び、その後にGANをベースに作られたDCGANモデルの構築を実践形式で行っていきます。
GANモデルを作ってみたい方もしくは興味がある方、実論文で提唱されたモデルを実装する経験が欲しい方、Kerasによる基本実装を経験したい方が対象です!
DALL-E
05_テキストから画像を生成するDALL-Eを実装するレシピ
投稿者:jun40vn さん
2021年1月にOpenAIが発表した「テキストを入力するとそれっぽい画像を生成するモデル」とDALL-Eの実装手法と画像処理について学ぶことができます。
DALL-Eの公開コードと凡庸画像分類モデル(CLIP)を組み合わせて、任意のテキストからその内容に合わせた画像を生成するモデルを作成します。
StyleGAN
06_StyleGANで本物と区別がつかない画像を生成するレシピ
投稿者:@shim tomさん
公開されている学習済みのStyleGANとデータセットを用いて本物と区別がつかない画像を生成するレシピです。
Style GANの解説が中心で、画像生成では学習済みのネットワークを利用します。
StarGAN-v2
07_StarGAN-v2で顔の特徴操作・顔の合成を実現するレシピ
投稿者:@lulu1351さん
有名人の顔写真データセットを用いて、StarGAN-v2による画像に写る人の顔の特徴操作・顔の合成を行う手法を学ぶことができます。
実際に深層学習GANモデルによる顔画像の生成や顔の特徴や位置の操作を行い、Google Colaboratory上で手を動かしてその性能を体感しながら、画像処理を学ぶことができます。
Latent Diffusion Models
08_Latent Diffusion Modelsを用いてテキストから画像を生成するレシピ
投稿者:12kaz さん
Latent Diffusion Modelsの技術概要を理解し、Huggingfaceのdiffusersライブラリを用いて、テキストから画像を生成する方法や、モデルが画像を生成する過程をアニメーションで可視化する方法を学びます。
製品、建造物などデザインアートへの利用、自然言語表現で指定した画像を生成し広告への活用が可能です。
GLIDE
09_GLIDEで様々な条件を指定したテキストから画像を生成するレシピ
投稿者:12kaz さん
GLIDEの技術概要を学び、論文発表元が公開するミニモデルGLIDE(filterd)を用いて、テキストから画像を生成する方法や、テキストに応じた画像修復方法を学びます。
GLIDEを用いたText to Imageタスク、自然言語表現から画像を生成する仕組みを学ぶことができます。
最後に
今回は、Axross Recipeで学べるディープラーニング使って画像生成を行うレシピ をご紹介しました。
プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
Axross Recipeのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。
