※本記事は2022年8月31日に更新しました。
Axross Recipeを運営している松田です。
今回は、Google検索エンジンのアルゴリズムにも使われている自然言語処理技術 BERTモデルを解説し、BERTを活用したレシピについて紹介します。
自然言語処理の理解
自然言語処理(Natural Language Processing=NLP)とは、人間が互いのコミュニケーションを行うために自然に発生した言語、例えば日本語や英語などの「自然言語」と、自然言語をコンピューターに理解・処理させる一連の技術を意味する「処理」を組み合わせた言葉です。
自然言語処理のタスクは、人の言葉の「あいまいさ」や会話の中での「意味の重複」により、人によって解釈の違いが存在するため、画像や数値データと比べて実用化が難しいと言われていました。
BERTの仕組み
BERTとは
BERTとは、2018年10月にGoogle社のJacob Devlinらの論文で発表された自然言語処理(NLP)モデルです。Google検索のアルゴリズムにも使われており、長文による検索でより文脈に合った検索結果が出るようになったのはBERTのおかげです。

BERT(Bidirectional Encoder Representations from Transformers)を和訳すると**「Transformerによる双方向のエンコード表現」となります。BERTには、Transformerアーキテクチャ(構造)が組み込まれており、文書中の単語の一部を隠し、隠した単語の正体を当てるように文章を双方向(文頭と文末)から学習** します。この学習方法により、隠した単語の後に現れる文章も予測可能で、長文であっても**「文脈から読解すること」**を可能にしました。
BERTは、機械翻訳、文書のカテゴリ分類、質問応答、文章生成などの自然言語処理タスクの課題を高い精度で解決し、8個のベンチマークタスクにおいて前SOTAを上回る、当時の最高スコアを叩き出したことで話題になりました。
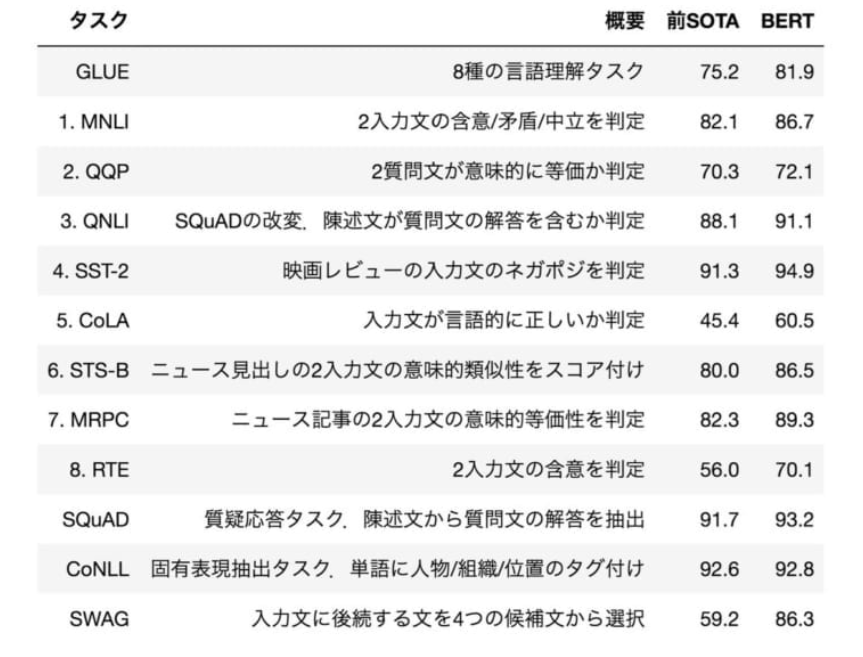
下グラフは、GLUEのNLP技術の各項目における平均スコアの推移を示したものです。
2018年10月のBERT登場を皮切りにスコアが飛躍的に上がり、2019年ごろには数値上は、AIが人間の会話能力を超えたことになります。
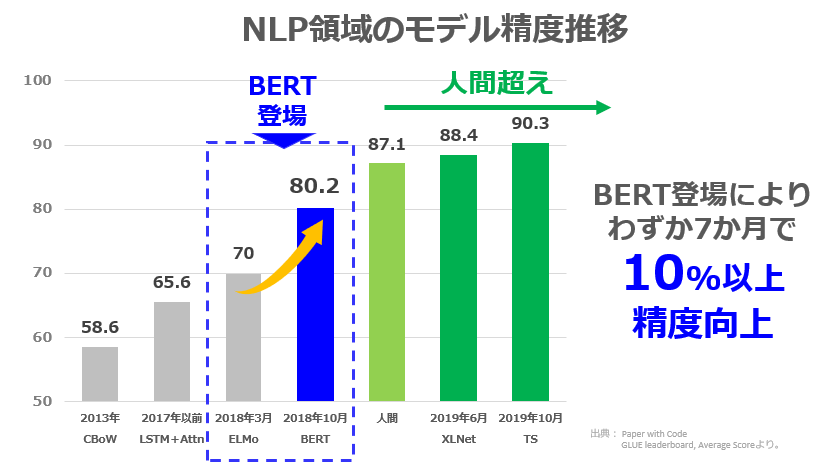
近年における自然言語処理の発展
大規模言語モデル(Transformer)の登場によって、自然言語処理の実用性が一気に高まりました。
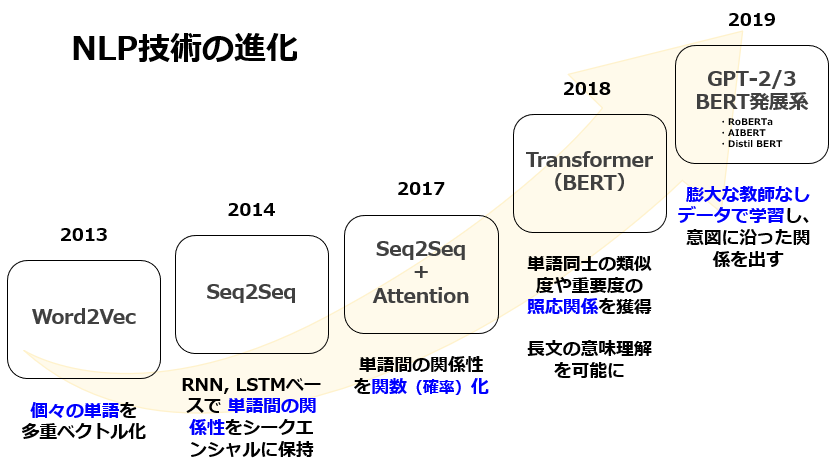
チャットボットを例にすると、従来までのチャットボットは 一問一答で教師データを作成するFAQ型のものや、条件分岐によるシナリオ型のものしかなく、構造化させた学習データの準備や、回答率を上げるための定常的な運用が課題でした。
しかし、Transformerを組み込んだBERTを活用する場合、サンプル学習モデルによって単語同士の類似度や重要度といった文脈を高精度で読むことができ、多義語や代名詞が何を指しているかまで読み取ることができます。抽象的な表現に対しても、文章のかたまりから導き出して近しい解答ができます。また、従来までは自然言語処理を行うためのラベルが付与されているデータセットは数が少なく、そのデータセットにラベルを付与する場合には多くの時間と労力を必要でしたが、BERTの場合、ラベルの付与されていないデータセットも処理することができる為、学習用のデータセット不足の課題を解決し、データセットを容易に準備することができます。
もう1つのBERTの特徴として、ファインチューニングの際の汎用性の高さもあります。従来のタスク処理モデルは特定のタスクのみに対応しているため、対象に応じてモデルの構造の修正が求められますが、BERTの場合は、モデルの修正の必要がなく、様々なタスクに対応することが可能です。タスク処理モデルの前にファインチューニングするだけで、自然言語処理の精度を高めることができるのです。
BERTの活用例
- 検索エンジン(例:Google)
- チャットボット
- 機械翻訳
- テキストデータのポジティブネガティブ分析
- 大量テキストデータの文章分類
- 大量のテキストデータの文章要約
- 稟議書の記載内容や誤字チェック
- 電子カルテの記載内容チェック
BERTのレシピ紹介
Axrossで学べるBERTを活用したレシピ を11つご紹介します。
チャットボット
01_BERTによる日本語QAの発話応答モデル作成レシピ
投稿者:@kanikaniさん
Google検索エンジンに使われている自然言語処理技術BERTをfinetuningし、QAタスクに適用する手法をPyTorchで学べるレシピです。
BERTを使って、A4紙1枚程度の日本語マニュアルの中から、日本語での質問に対する日本語の回答を探し出すモデルを作成します。
02_【発展編】BERTによるQAチャットボットの学習モデル作成レシピ
投稿者:@kanikaniさん
Google検索エンジンに使われている自然言語処理 BERTと自然言語処理に特化した深層学習のフレームワーク Transformers を活用し、日本語QAチャットボットの学習モデルを作成するレシピです。
BERTは自然言語処理の精度が良いだけでなく、学習が容易という利点があり、金融業界を中心に各社が注目しています。
03_ELECTRAでユーザからの質問に対して応答するレシピ
投稿者:@Kay Hosodaさん
ELECTRAというディープラーニングによる言語モデルを使用してユーザからの質問に応答するプログラム動かしながら学ぶことができます。
チャットボットや音声アシスタントに活用することができます。
04_BERTによるQAチャットボットの作成レシピ
投稿者:@Y Shimizuさん
自然言語処理モデルの中でも人気のある「BERT」を用いて、Wikipediaのコーパスを用いてQAチャットボットを作成する方法を学びます。
コールセンター、ヘルプデスク、オペレーター支援に活用することができます。
05_BERTとXLNetの精度比較を行うレシピ
投稿者:@Y Shimizuさん
自然言語処理の最新モデルである「BERT」と「XLNet」を用いて、Wikipediaのコーパスをベースに質疑応答のタスクを処理する方法を学び、その精度を比較します。
コールセンター、ヘルプデスク、オペレーター支援に活用することができます。
感情予測
06_日本語BERT事前学習モデルを使ってMultilabel Sentiment分類器を学習するレシピ
投稿者:@sb-toukouさん
事前学習モデルを使ったマルチラベルデータの学習方法と、テキストから感情分類をするモデルの作成手法を学ぶレシピです。
Twitter APIを使ってTwitterのツイートから日本語の教師データを集めて、Hugging Faceで公開されているBERTの事前学習モデル使って、モデルをFinetuningし、マルチラベル問題の分類器を作成します。
文章分類
07_日本語BERTを利用してZero-shotで文書分類するレシピ
投稿者:@睦広さん
教師データに存在しないラベルを予測する「Zero-shot Learning」という問題設定でテキスト分類するレシピです。
自然言語処理の分野ではトップの国際会議である、ACL2020でBERTを利用したモデルが提案されました。比較的少ないコードでZero-shot Text Classificationを実装する方法を紹介します。
08_フェイクニュースを検知するレシピ
投稿者:@Kay Hosodaさん
近年ディープラーニングを使った文章生成の技術が進化しており、それに対抗するためにフェイクニュースを検知する研究も盛んに行われるようになりました。
BERTベースのGraph Neural Network(GNN)用いた、GNN-based Fake News Detectionというディープラーニングの技術を使って、フェイクニュースを検知する方法を実際にプログラム動かしながら学ぶレシピです。
09_Googleが開発しているJAX用の高性能ニューラルネットワークライブラリFlaxを用いてツイート分類を行うレシピ
投稿者:@petapetaさん
FlaxとはGoogleによるDeep Learningフレームワークです。FlaxはTensorFlowと比較して簡素に、柔軟に書くことができ、huggingfaceのtransformersもv4.8.0からFlaxをサポートするようになっています。
GPUやTPUといったアクセラレーター対応による高速化を図ることができるレシピです。
10_BERTを用いたネガポジ分類モデルの実装
投稿者:@petapetaさん
近年自然言語処理タスクで利用されているBERTについて、実際にツイート情報を用いて実装、またBERTの他にRobertaと呼ばれるモデルも実装していき、BERTとの比較を行うレシピです。
テキストのネガポジ分類、スパムメールの分類に使用することができます。
文章要約
11_BertSumを使った文書要約のレシピ
投稿者:@Kay Hosodaさん
文書要約技術で話題となっているBERTを応用して文書要約を行う深層学習モデルBertSumについて、実際にプログラム動かして、最先端の文章要約性能を体感しながら学ぶレシピです。
BertSumのコンピュータによって文章から要約を生成する技術は、ニュース記事のサマリや、議事録・日報の自動生成等、様々な業務シーンに応用ができます。
12_BertSum(T5)を用いてアンケートの自由記述を要約するレシピ
投稿者:@Y Shimizuさん
「BERTSum」や「T5」を用いて、自由記述アンケート回答の要約を作成します。
自然言語処理を用いた要約プログラムが作成できるようになると、様々な文章の要約が可能になります。
13_類似文章を検索するAPIを作成するレシピ
投稿者:@runnerさん
自然言語処理の各分野で顕著な成果を挙げている深層学習モデルBERTを使ったマイクロサービスを作成するレシピです。具体的には、transformerとflaskを使って、類似文章を検索するAPIを作成したいと思います。
BERTを用いて、文章から検索するサービスの開発に活用できます。
択一問題
14_日本語の択一問題を解くレシピ
投稿者:@su2umaruさん
rinna社の機能を用いて、択一問題を解くタスクをテーマに解説し、日本語言語モデルの発展を体感しながら学ぶレシピです。
マイクロソフトのAIチームから独立したrinna株式会社が、日本語GPT-2/BERTの事前学習モデルを開発し、オープンソース化を発表しました。rinna社が公開したHuggingFaceページでは、一般的な日本語テキストの特徴を有した高度な日本語文章の自動生成を実行できます。
画像分類
15_BERTをImage Transformersに応用したBEiTで画像分類するレシピ
投稿者:@12kazさん
Microsoft Researchが2021年6月に論文発表した、Transformerベースの自己教師あり画像分類モデルBEitを使用してアノテーションコストを削減するレシピです。
本技術を使えば、データのラベル付けなどアノテーション作業に多くのコストを要するという問題解決に役に立ちます。
実務では、商品写真から商品カテゴリを分類することによる自動タグ付け等の画像分類ができるようになります。
誤字チェック
16_BERTによる日本語の誤字をチェックするレシピ
投稿者:@佐藤優さん
BERTの内容を理解すると同時に、自動で文章校正を行うコードをを学ぶレシピです。
ディープラーニングの概要に加え、誤字チェックに活用できる技術を学ぶことができます。
最後に
AxrossRecipe は、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、実際の業務に近いテーマで、動くものを作りながら学ぶことができます。
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/AxrossRecipe_SB

プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
AxrossRecipeのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。