はじめに
AxrossRecipeを運営している藤原です。
AxrossRecipe とは、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いのもと、ソフトバンクの社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウを"レシピ"として教材化し、実際にプログラミングで実装を追体験しながら学ぶことができます。AI/機械学習をテーマにした、様々な業務領域やビジネスの課題解決に応用できる実践的な学習教材を340以上揃えています。(2022年6月時点)
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/AxrossRecipe_SB

今回は、AIを活用した音声認識の仕組みや事例を紹介し、Axrossのサービスで学べる実践的な、音声認識を活用した人気レシピをご紹介します。
音声認識とは
音声認識とは、人間が発話した音声データに対して、コンピュータが音と文字とをパターンマッチングで認識し、テキストに変換する技術のことです。
音声認識は、ディープラーニングの登場によって膨大な情報を処理できるようになり、データから自動で特徴を抽出し、分類や予測を行うことで、音声認識の著しい向上につながりました。
身近な活用シーンでは、コールセンターでのお客様対応における録音した音声ファイルの文字起こしの自動化や、音声をテキスト化することによりマーケティングや商品開発で役に立つ新たな知見の発見、SiriやAlexa等の音声アシスタントやスマートスピーカーでの音声指示や音声対話によるハンズフリー操作などで活用されています。
音声認識の仕組み
音声認識技術の基本的な仕組みや音声認識精度を高めるコツを理解することで、自社での活用におけるアイデア出しや実運用の企画立案ができるようになります。
音声認識のおおまかな流れは、録音した音声データをデジタルに変換し、コンピュータで言語処理・学習することで、その内容を認識させる、といったものです。
まず、アナログ信号である音声データを入力とし、コンピュータが処理しやすいようにデジタル信号の波形に変換する、音響分析を行います。音響分析では、音声の最小単位である音素を抽出し ノイズを除去する作業を行うことで、音声データの音の強弱や周波数、音の感覚、時系列などの様々な特徴量を抽出したり、音響モデルで認識しやすいようにデータを整形します。
次に、音声から抽出された特徴量が、どの音素に近いかを統計的に処理する「音響モデル」と、ある文字列に続く直後の文字の出現しやすさをパターン化し、出現確率を定義する「隠れマルコフモデル」という手法を使います。
テキスト化した文章を、文字列や単語列に区切り、言語・単語として適切かどうかを評価するためには、言語モデルを活用します。言語モデルは、膨大な量のテキストから単語の出現頻度を記録・蓄積し、単語のつながりを予測判定し、認識したいデータと照合して、出現確率が高い文章に統計処理をして、正確な文脈になるよう単語を文章に組み立てます。
発話辞書は、音声モデルと言語モデルを結びつける役割をします。音響モデルから導き出された音素と、適切な文章を評価するための言語モデルで、どの単語と近いかをパターン学習したデータベース発話辞書と照らし合わせ、音素や単語の類似度や整合率を計算します。認識デコーダ―の役割は、音響的にも、言語的にも、発話辞書との照合でも最も適合する言語表現を探し出し、その文章をテキストとして出力します。実務では、音声データに方言や独特の言葉遣い、言い淀みが含まれていたり、雑音が多い環境や複数人が同時に発話している場面などでは、事前に学習した発音辞書で照らし合わせることが困難になるため、音声認識を阻害する要因となります。
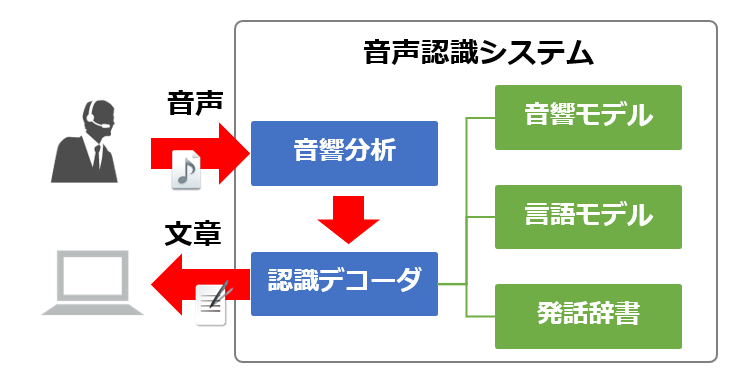
音声認識の代表的なモデル
音響モデルは「ディープニューラルネットワーク(DNN)」を組み入れた、「DNN-HMM」、言語モデルは、任意の文字列や文書を連続したn個の文字で分割するテキスト分割方法N-gramと「リカレントニューラルネットワーク(RNN)」との併用が広がっており、更にひとつのニューラルネットワークで音声認識を実現する「End to Endモデル」も主流になりつつあります。
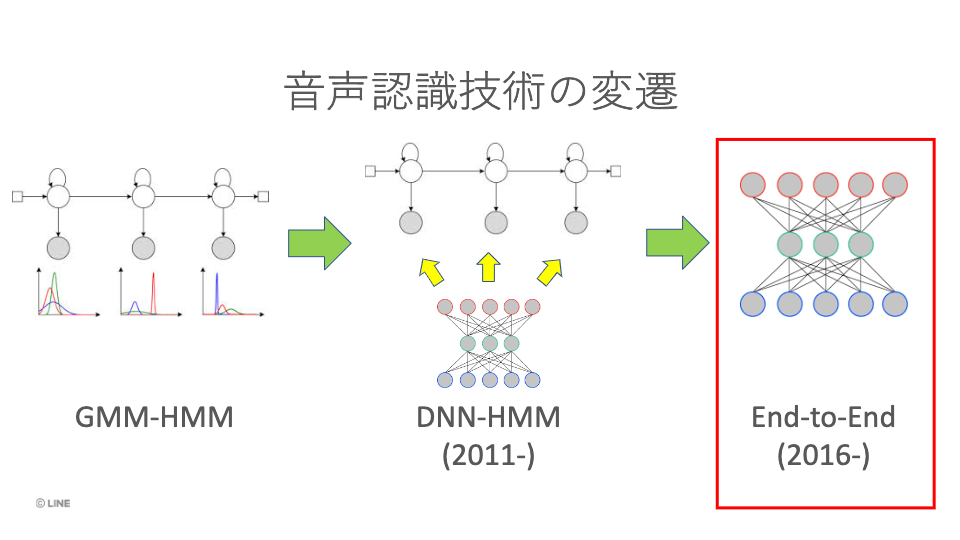
出典:LINEが取り組む音声認識の取り組み
音声認識AIを活用したレシピの紹介
01.楽曲のムードを深層学習で分類するレシピ
投稿者:@belltree さん
楽曲100曲ずつムード別(happy, relax, sad, angry) に分類した音声データを学習し、音響的特徴量を使って深層学習(keras)で楽曲を分類する手法を学べます。
音の周波数と時間軸をグラフ化したスペクトログラムグラフを作成し、画像データとして可視化することで、画像分析モデルを作成・加工し、Fine Tuningで学習モデル精度を向上させます。SpotifyやApple Music等での楽曲自動再生で利用されてる技術です。
02.AWSのサービスを活用した音声合成と機械翻訳の連携のレシピ
投稿者:@zaaak さん
AWSのサービスであるAmazon Pollyの音声合成とAmazon Translateの機械翻訳を連携させる手法を学べます。音声合成と機械翻訳により、近年流行のボイスチャットボットや翻訳アプリの作成に活用できます。
本レシピはシリーズものになっており、音声合成と機械翻訳のそれぞれ単体のレシピの学習を終えた方向きです。発展編として、**AWSのサービスを活用した有名人画像認識アプリの開発のレシピ 前編(画像認識)/ 後編(音声合成&機械翻訳)~**のレシピもありますので、音声処理と画像処理、自然言語処理もマルチモーダルな開発を学びたい方は、こちらもお試しください。
03.音声処理ツールキットESPNetを用いて日本語音声認識を行うレシピ
投稿者:@sbtoukou さん
マイクで録音した音声信号データを用いて、その発話内容である文字列に変換する音声認識技術として、OSSとしてGitHubに公開されているBaidu社の音声処理ツールキットのESPNetを使い、音声認識モデルのTransformer ASRの概要について解説します。
音声処理ツールキットESPNetの実行環境をlocal PC内にて構築し、実際にEnd to Endの日本語の音声認識技術を体験しながら学ぶことができます。
04.画像から音楽を生成するモデルを構築するレシピ
投稿者:@milkty さん
クリエイティブなAIを体験するレシピとして、深層学習を用いて画像から音楽を生成するモデルを作成します。
まず画像を収集し、それぞれにBGMを割り振ります。そして、BGMのコード進行をテキスト化し、転移学習による画像分類とコード進行生成を行い、最後にChord2Melodyを使用して画像に合ったそれっぽい音楽を自動生成します。
Encoder-Decoderによる画像分類モデルと言語生成モデルをつかった、画像から音楽を生成モデルの作り方を手順に沿って学べます。
05.Zoom会議の録音データから音声認識で議事録を自動生成するレシピ
投稿者:@benao_python さん
PCマイクから録音(Pyaudio)や、文字起こし(Watson API)等Pythonのライブラリを用いて、ZOOM会議の録音履歴データを自動でテキスト化(Speech to Text)する音声処理の手法を学べます。
Watson APIは、機械学習の機能が揃うライブラリで、音源ファイルを処理する機能も豊富に用意され、簡単に扱えます。
Watsonの機械学習とPythonを活用して、普段の会議の議事録やメモ作成の業務を自動化してみましょう!
@benao_python さんのPythonを活用した音声認識関連レシピとして、ZOOM会議に映る顔の表情認識を画像処理で行う**あなたのPCをPepperのような表情認識ロボットにできるレシピや、GPT-3の文章生成言語モデルを応用し、文章入力を介さず音声のみで会話するボットの作成を行う【GPT-3発展編】音声だけで会話するチャットボットを作るレシピ**も併せてお試しください。
最後に
今回は、Axrossサービスで学べる実践的な、音声認識AIを活用したレシピ をご紹介しました。
AIを活用できる人材になるためのコツは、座学勉強よりも、まず実際にAIを実装する体験をしてみる、そして、様々なテーマやデータセットで、異なるAIモデルの実装を繰り返し演習することが近道だと思います。
Axrossのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。

また、Axrossでは自身のナレッジを学習教材"レシピ"として寄稿いただけるエンジニアの方も募集しています!
見習いエンジニアから募った学びたい内容を**ウィッシュリスト**として掲載しています。募集中のテーマからご自身で作成いただけるようでしたら、レシピ作成にご協力お願いいたします。