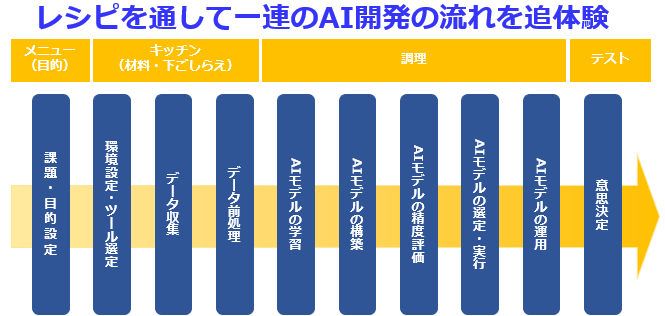
はじめに
AxrossRecipeを運営している松田です。
AxrossRecipe は、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、実際の業務に近いテーマで、プラグラミングで動くものを作りながらAI開発やデータ分析を学べます。
Axross: https://axross-recipe.com
Twitter: https://twitter.com/Axross_SBiv
自然言語を処理するとは
自然言語処理(Natural Language Processing、略称:NLP)は、人間が日常的に使っている話し言葉や書き言葉(自然言語)を、コンピュータに処理させる一連の技術のことです。
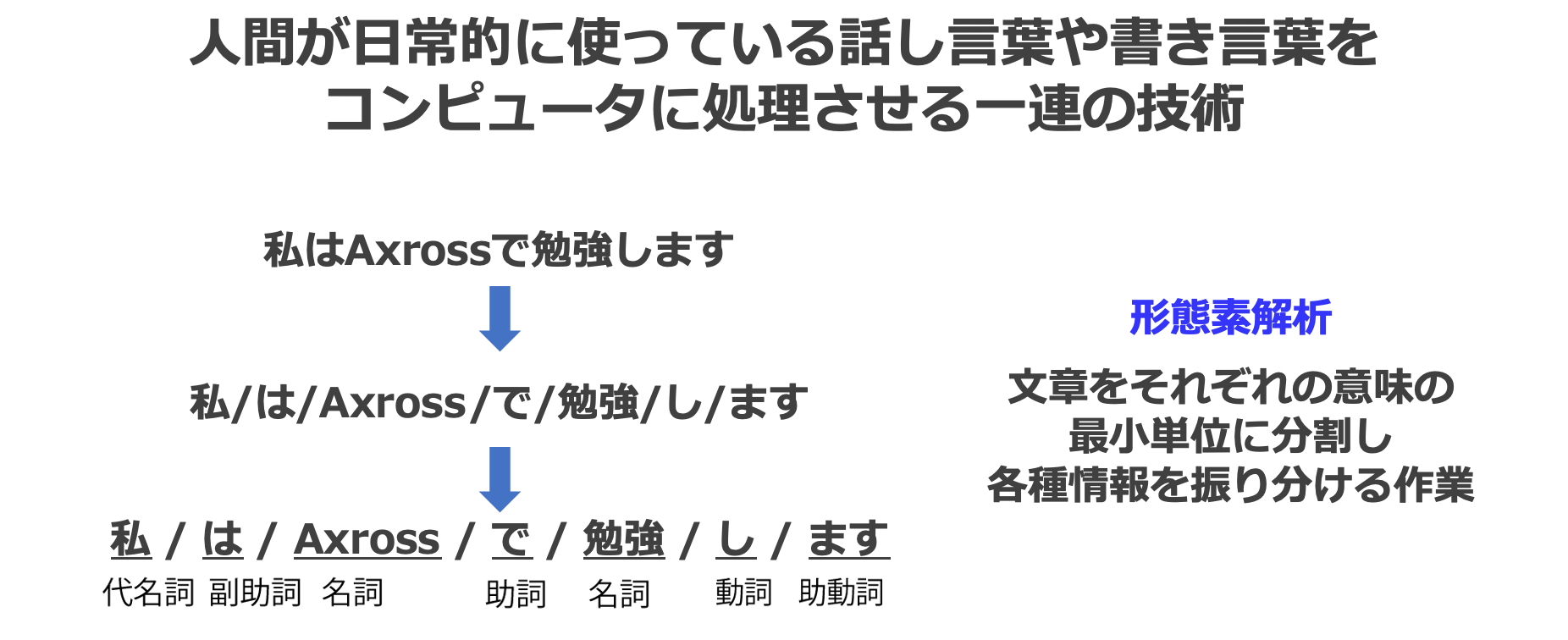
自然言語とよく対比されるのが、プログラミング言語で、コンピュータを制御するためのプログラムを記述するために利用します。自然言語は、人間が使う言葉であり、人によって言葉の意味が異なったり、前後の文脈やその人の意図・感情などの要素を汲み取らないと文章の解釈が分かれたりするため、言語に「曖昧性」が含まれます。一方で、プログラミング言語は、コンピュータが同じ表現を常に同じ解釈で、同じように制御するようにプログラムするための言語であるため、言語は一意で、曖昧性はありません。

自然言語処理
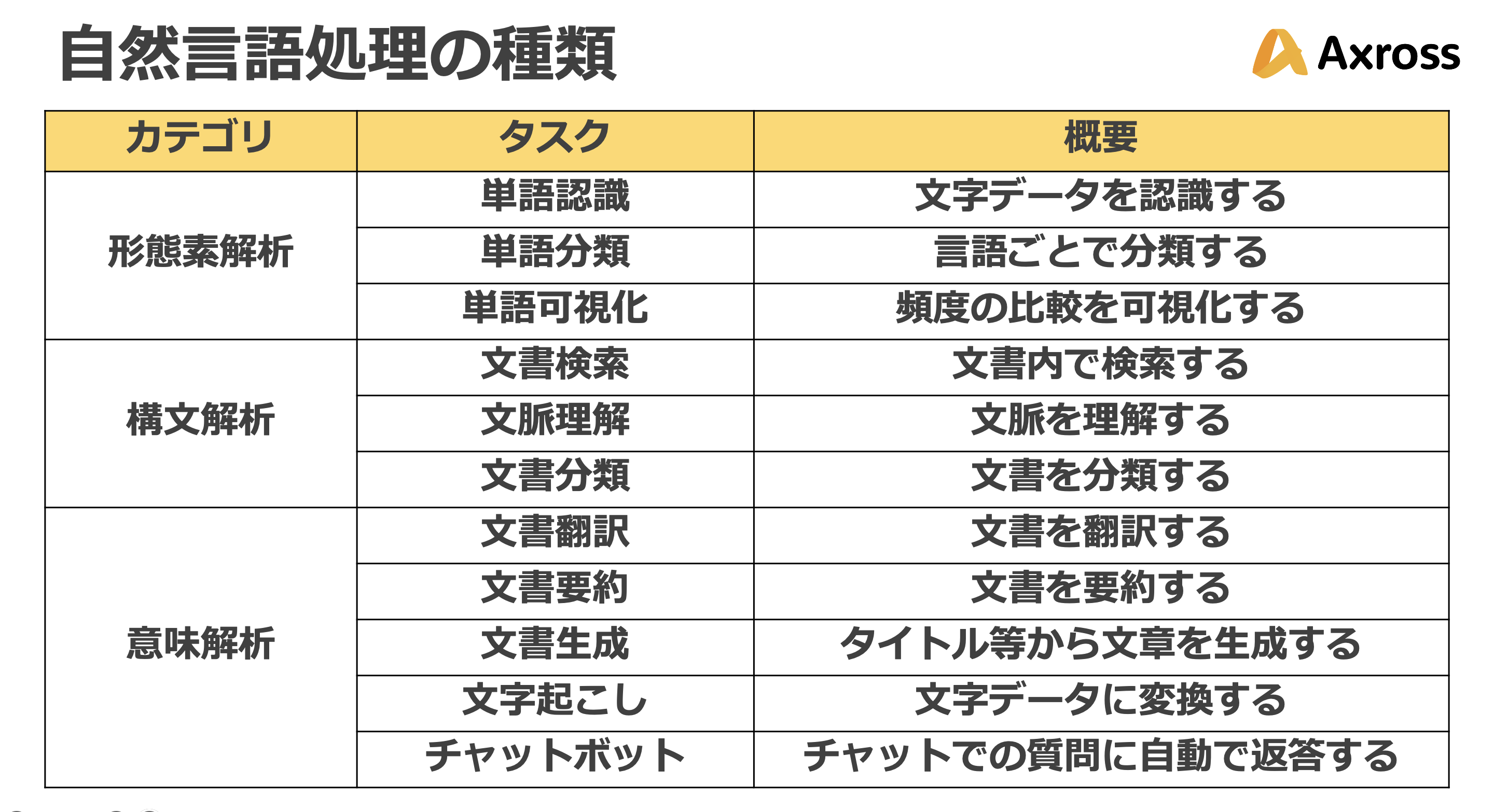
単語認識
単語認識は、言葉が持つ意味を認識する技術です。
単語分類
単語分類は、読み込んだ文字データから、単語の持つ意味ごとにカテゴリ分類する技術です。ポジネガ判定がその例です。
自然言語データを前処理することによって、単語認識や分類ができるようになります。

単語可視化
単語可視化は、読み込んだデータの中で頻出単語の頻度や共起関係等を可視化する技術です。Wordcloudが代表的なライブラリです。
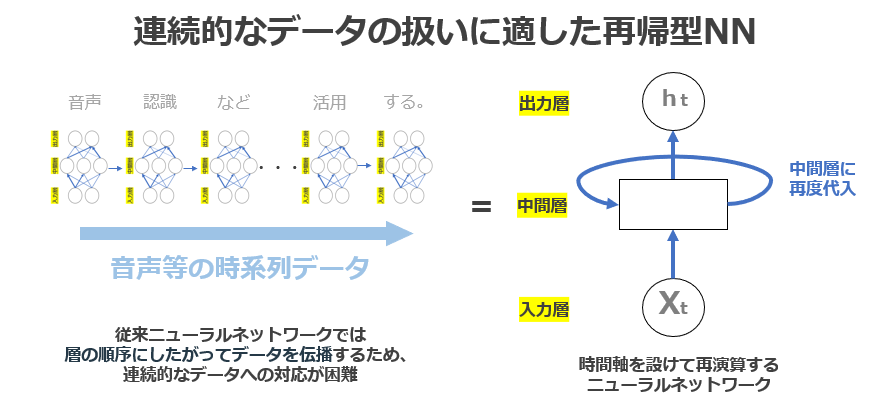
RNN (Recurrent Neural Network)
RNNは、人間の会話や文章のような、連続的なデータ処理に特化したニューラルネットワークです。時系列を考慮することができるため、2010年ごろに自然言語処理の分野で活用できると、一躍脚光を浴びました。
LSTM (Long short-term memory)
LSTMは、2014年に発表されたRNNの改良モデルです。RNNの長期依存性、勾配消失の問題を、LSTMブロックという機構を導入することで解決し、時系列情報をうまくネットワーク内に保持できるようになりました。
word2vec
word2vecは、2013年にGoogleの研究チームによって開発された、単語の分散表現を獲得する推論ベースのモデルです。単語間の類似度だけではなく、単語の概念も獲得することが可能です。
文字起こし
文字起こしは、録音ファイル等の音声データから、文字データに変換する技術です。
文書要約
文書要約は、読み込んだ文書データをもとに要約する技術です。
文書翻訳
文書翻訳は、ある言語を他の言語に翻訳する技術です。
チャットボット
チャットボットは、リアルタイムで短文のやり取りを行うことを意味する「チャット」と、一定の作業を自動化するロボットを意味する「ボット」を合わせた名称で、チャットでの質問に自動で返答するプログラムやアプリケーションのことです。
文書分類
文書分類は、電子文書の内容に沿ってカテゴリごとに分類する技術です。
BERT (Bidirectional Encoder Representations from Transformers)
BERTは、2018年にGoogle社のJacob Devlinらの論文で発表された自然言語処理モデルです。
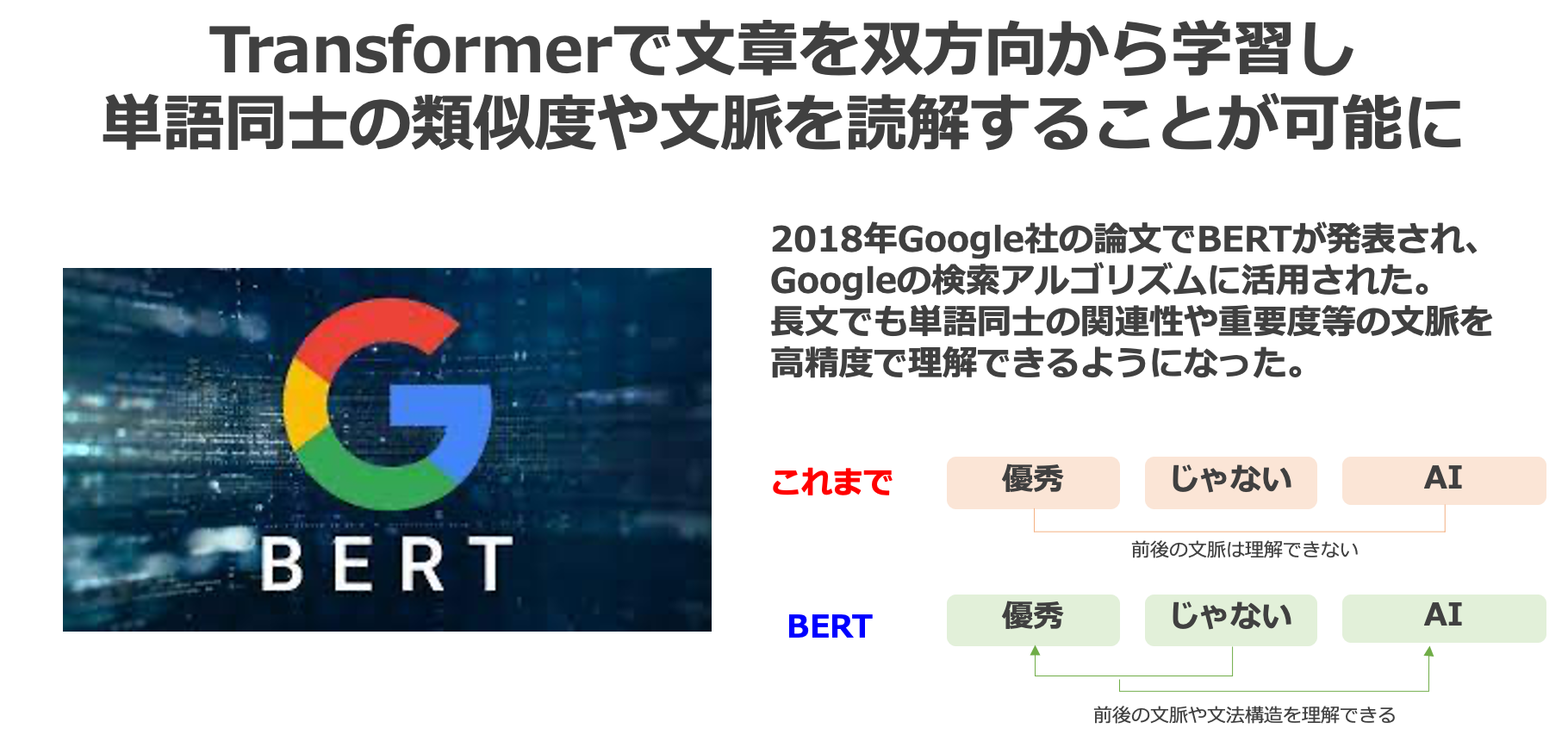
Google検索のアルゴリズムにも使われており、長文による検索でより文脈に合った検索結果が出るようになったのはBERTのおかげです。

BERTは、機械翻訳、文書のカテゴリ分類、質問応答、文章生成などの自然言語処理タスクの課題を高い精度で解決し、8個のベンチマークタスクにおいて前SOTAを上回る、当時の最高スコアを叩き出したことで話題になりました。
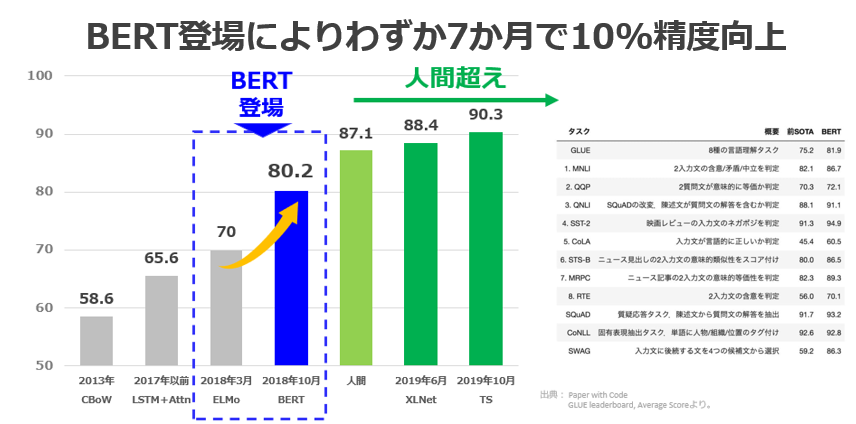
下グラフは、GLUEのNLP技術の各項目における平均スコアの推移を示したものです。2018年10月のBERT登場を皮切りにスコアが飛躍的に上がり、2019年ごろには数値上は、AIが人間の会話能力を超えたことになります。
文書検索
文書検索は、文書群の中から指定した特定の文章及び単語を照合する技術です。
文書生成
文書生成は、タイトルや要約などの文章をデータとして与え、その記事の本文を自動生成する技術です。
GPT(Generative Pretrained Transformer)
GPTは、2015年12月に設立された非営利の人工知能研究組織「OpenAI API」が開発している「文章生成言語モデル」です。イーロンマスクが共同経営していることでも有名です。

様々なAI自然言語処理の手法を学べるレシピ紹介
言語認識
1.Pythonの辞書を用いて文章中の各名詞の出現回数をカウントするレシピ
辞書型の基礎を学習し、Pythonとpandas、Mecabで日本語文章を形態素解析し、分析した結果と辞書型を用いて文章中の各名詞の出現回数をカウントする自然言語処理の手法を学ぶことができます。
2.フェイクニュースを検知するレシピ
BERTベースのGraph Neural Network(GNN)用いた、GNN-based Fake News Detectionというディープラーニングの技術を使って、フェイクニュースを検知する方法を実際にプログラム動かしながら学ぶことができます。
言語分類
3. コメントからポジネガを自動判定するレシピ
ECサイトのレビュー解析を想定し、WEBスクレイピングで映画サイトのコメントを取得し、日本語テキストのポジネガ分類モデルを実装します。
4. TwitterAPIと形態素解析でフォロワーのいいねしたツイート傾向を分析するレシピ
Twitter APIとJanomeを活用し、自分のTwitterアカウントのフォロワー分析を行います。
5. 日本語BERT事前学習モデルを使ってMultilabel Sentiment分類器を学習する
Twitter APIを使ってツイートを取得し、事前学習モデルを使ったマルチラベルデータをHugging Faceで事前学習し、テキストの感情分類モデルを作成します。
6. BERTを用いたネガポジ分類モデルの実装
近年自然言語処理タスクで利用されているBERTについて、実際にツイート情報を用いて実装していきたいと思います。
また、BERTの他にRobertaと呼ばれるモデルも実装していき、BERTとの比較を行っていきます。
7. TensorFlow.jsを用いてブラウザで言語処理モデルを実行するレシピ
webアプリケーションフレームワークであるDjangoでwebアプリを開発し、Tensorflow.jsを用いてwebアプリのブラウザ上でテキストの有害度検出、テキストの感情分析、Q&Aを実現する方法を学びます。
8. TwitterAPIで乃木坂46メンバーの話題度を比較分析するレシピ
TwitterAPIのツイート検索機能を使い、アイドルグループの乃木坂46に関するツイートを検索して形態素解析を行い、各メンバーについて言及しているツイート数を比較してその話題度を比較分析するPythonプログラムを作成します。
言語可視化
9. 売れ筋商品の特徴を共起ネットワークで可視化するレシピ
Pythonによる簡易的なWebスクレイピング、テキストデータから単語の共起関係の抽出やNetworkX を利用した共起ネットワークの可視化を行い、日本語テキストのテキストマイニングの流れを学べます。
10. 1冊の本を1枚の画像で可視化するレシピ
日本語のテキストデータにMecabを使って形態素解析し、単語の頻出度に応じてWordCloudで可視化します。
11. 材料の単語分散表現から知見を抽出するレシピ
材料系の膨大な論文をスクレイピングで学習し、mat2vecで材料同士の類似度を分析し、マテリアルズインフォマティクスにおいて、単語分散表現の機械学習モデルから人間が気づかなかった知見を抽出・可視化します。
12. ブラウザの履歴データから形態素解析でユーザーの嗜好を抽出するレシピ
形態素解析ライブラリJanomeを使って、Google Chromeの検索履歴データから頻出単語を取り出してランキング化し、ユーザーのWebページ閲覧傾向を分析します。
13. Rを用いてアンケートの自由記述からキーワードを抽出するレシピ
R言語を用いてアンケートの自由記述に入力された文章からキーワードを抽出するレシピです。
文字起こし
14. Zoom会議の録音データから音声認識で議事録を自動生成するレシピ
PCマイクから録音した音声ファイルデータをWatson APIの音声認識機能を用いて文字起こしし、議事録を自動生成します。
15. Streamlitで音声文字起こしアプリを作るレシピ
SpeechRecognitionというライブラリを使って、マイク入力した音声の文字起こしと、入力したテキストを読み上げるアプリケーションを作成するレシピです。会議の議事録作成などに活用できます。
文書要約
16. GPT-3でタイトルや要約から記事本文を自動生成するレシピ
文章生成モデルGPT-3のAPI機能を使って、長文の自動要約と日本語記事コンテンツ自動生成を行います。
17. BertSumを使った文書要約のレシピ
BERTを応用して文章要約を行うディープラーニングBertSumを実装します。
18. BertSum(T5)を用いてアンケートの自由記述を要約するレシピ
このレシピでは、「BERTSum」や「T5」を用いて、自由記述アンケート回答の要約を作成します。
文書翻訳
19. Amazon Translateを使った機械翻訳のレシピ(基礎編)
AWSのサービスである、Amazon Translateを活用し、実際に機械翻訳を行う流れを体験できます。
択一問題
20. 日本語の択一問題を解くレシピ
Microsoft社のAIチームから独立したrinna社がOSS化した日本語GPT-2、BERTの事前学習モデルを使い、日本語の択一問題を解くタスクを学べます。
チャットボット
21. BERTによる日本語QAの発話応答モデル作成レシピ
BERTを使ってA4紙1枚程度の日本語マニュアルの中から、日本語で質問すると日本語で回答を探し出すモデルを作成します。発展編では、BERTとTransformerを活用し、日本語のQAチャットボットの学習モデルを作成します。
22. BERTによるQAチャットボットの作成レシピ
自然言語処理モデルの中でも人気のある「BERT」を用いて、Wikipediaのコーパスを用いてQAチャットボットを作成する方法を学びます。
コールセンター、ヘルプデスク、オペレーター支援等に活用が期待できます。
23. GPT-3で自然対話するSlackボットを作るレシピ
GPT-3を使って、Slack上で自由に雑談・対話できるボットを作成します。GPT-3を活用することで、文脈を踏まえた自然な返答文を自動生成することができ、暇なときの雑談の相手になってくれます。
24. 【GPT-3発展編】音声だけで会話するチャットボットを作るレシピ
GPT-3の言語生成モデルを応用し、文章入力を介さず音声のみで会話するチャットボット開発を行います。
25. MicrosoftのDialoGPTでチャットアプリを開発するレシピ
Microsoftが開発しているDialoGPTを活用してチャットアプリを開発します。
26. Microsoftから独立した企業が公開した日本語版GPT-2でチャットボットを作るレシピ
日本語で構成されたデータセットで最適化された「りんなGPT-2」の学習済みモデルを用いて、 Pythonでチャットボットや長文生成を試し、過去に書いたGPT-3のレシピとの精度・結果を比較します。
27.Watson Assistantを活用したチャットボットの開発
IBM Watson Assistantを使用して、GUIベースでAIチャットボットを作成します。
28.ELECTRAでユーザからの質問に対して応答するレシピ
ELECTRAというディープラーニングによる言語モデルを使用してユーザからの質問に応答するプログラム動かしながら学ぶレシピです。
チャットボット、音声アシスタントへの活用が期待できます。
29.BERTとXLNetの精度比較を行うレシピ
自然言語処理の最新モデルである「BERT」と「XLNet」を用いて、Wikipediaのコーパスをベースに質疑応答のタスクを処理する方法を学び、その精度を比較するレシピ。
チャットボット、音声アシスタントへの活用が期待できます。
文書分類
30. 日本語BERTを利用してZero-shotで文章分類するレシピ
教師データに存在しないラベルを予測する「Zero-shot Learning」という問題設定でBERTモデルを利用したテキスト分類を行います。
31. Googleが開発しているJAX用の高性能ニューラルネットワークライブラリFlaxを用いてツイート分類を行うレシピ
Twitter API を用いて抽出された160万件のツイートデータからダウンサンプリングしたデータセットデータをJAX用の高性能ニューラルネットワークライブラリFlaxで学習し、ツイート分析を行います。
文書検索
32. 文書の「あいまい検索」機能をつくるレシピ
word2vecの発展系fasttextを使って、日本語文章の検索単語が完全に一致しなくても検索できる「あいまい検索」を実装します。
33. 類似文章を検索するAPIを作成するレシピ
transformerとflaskを使って、類似文章を検索するAPIを作成します。発展編として、Docker上で作成するレシピもあります。
文書生成
34. GitHubのcopilotで自然言語から関数を生成するレシピ
copilotの申請方法からVScodeへの導入方法、実際の関数コードの自動生成までを解説付きで学ぶことができます。
35. GPT-3のNLPアプリケーション開発を体験してみるレシピ
文章生成モデルGPT-3を用いて、NLPアプリケーションの開発を行います。
36. 夏目漱石の「坊ちゃん」を学習させてマルコフ連鎖で新作を自動生成させるレシピ
マルコフ連鎖で文章生成するPythonライブラリMarkovifyを使って夏目漱石の「坊ちゃん」の続編となる文章を自動生成します。
37. LeakGANを使った文書生成のレシピ
チャットボットやAIアシスタントが発話するシナリオ作成への応用を想定し、LeakGANを使って文章生成を行います。
38. ArtEmisでアートを説明するAIを開発するレシピ
絵画に説明文と感情を付与した大規模データセットであるArtEmisを使用して、画像キャプション生成について、実際のプログラムを確認しながら学びます。
文章校正
39. BERTによる日本語の誤字をチェックするレシピ
BERTの内容を理解すると同時に、自動で文章校正を行うコードを学ぶレシピ。
ディープラーニングの概要を学ぶとともに誤字チェックに活用できる技術を学ぶことができます
感情分析
40. Rで肯定的・否定的なレビューを可視化するレシピ
Rを用いて肯定的・否定的なレビューを可視化する方法を実際にプログラム動かしながら学ぶことができます。
ECサイトのレビュー分析、コールセンターのログ分析に活用することができます。
最後に
今回は、AxrossRecipeで学べるさまざまな自然言語処理の手法を学べるレシピ40選をご紹介しました。
プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
AxrossRecipeのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。
