はじめに
※本記事は2022年8月に新着レシピを8個追加いたしました。
AxrossRecipe とは、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いのもと、ソフトバンクと社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、動くものをつくりながら、具体的な目的やテーマをもってプログラミングを学ぶことができます。
AxrossRecipe:https://axross-recipe.com
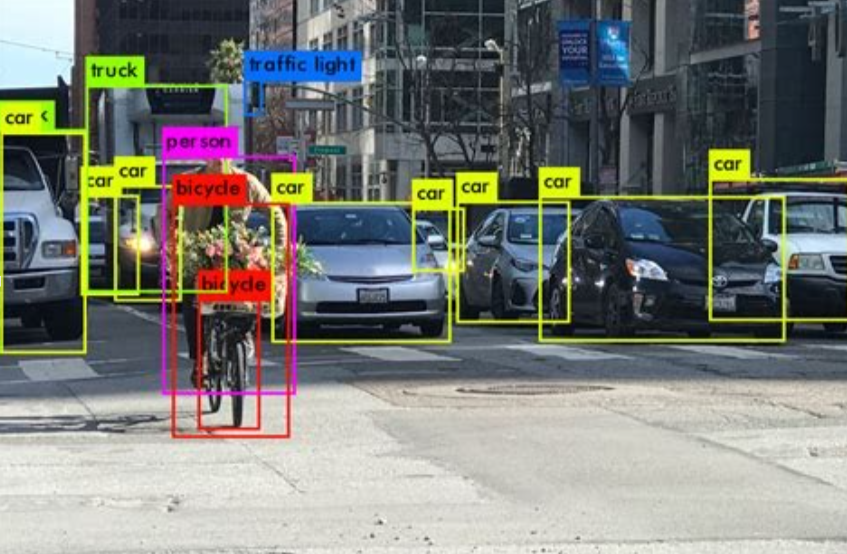
今回は、動画に映る人や物に対して、AI/機械学習を用いて対象物を抽出する 物体検出 の代表的な手法と、Axrossで学べる関連レシピをご紹介します。

物体検出とは
動画像の中から定められた物体の位置と種類、個数を特定する技術です。動画像から物体の種類を分類するのは、画像分類でも行えますが、物体検出ではそれに加え、
- 物体の領域の位置を矩形で予測し絞り込む方法
- 認識対象以外の物体を排除する方法
というような手法を取り入れることで、動画像に映る対象物の位置・個数の検出を可能にしています。
物体検出は、製造業や建設業、流通小売、医療、セキュリティなど業種を問わず幅広い分野で活用されています。
例えば、自動運転車における歩行者の検出、ドローンを活用した高所設備のメンテナンス、スタジアムのマスク着用率の計測、監視カメラの動画における人の購買行動分析、CT医療画像から体の異常部位の検出、Google Lensによる画像検索...、挙げたらきりがないです。
物体検出は、主に「CNN(畳み込みニューラルネットワーク)」を利用しています。CNNとは、ディープラーニングで用いられるネットワークの中で画像からパターンや物体を認識するための有名な手法の1つです。
畳み込み演算とプーリング+活性化関数を活用した画像の特徴の強調を繰り返すことで、画像の部分的な特徴と全体的な特徴を学習していき、画像の特徴量の学習を最適化していきます。
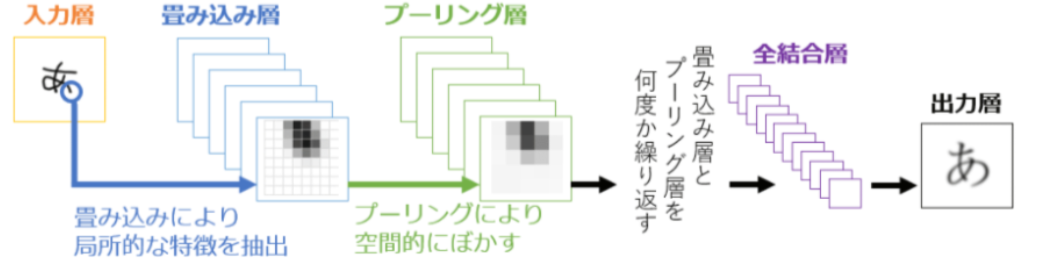
出典:CNN(Convolutional Neural Network: 畳み込みニューラルネットワーク)とは?
物体検出の手法
AI/機械学習を用いて、動画に映る人や物のような対象物を検出する代表的な手法をいくつか紹介します。
YOLO
YOLOは、物体検出の王道と言えるモデルです。You Only Look Onceの略で処理速度が非常に早い のが特徴です。そのため、リアルタイムの物体検出をすることができます。
YOLOの物体認識の手法は、予め画像全体をグリッド分割しておき、各領域ごとで物体の種類と位置を求めます。
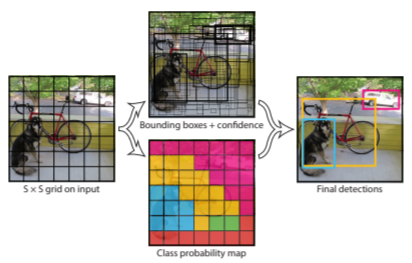
物体が多数写っている場合は、識別精度が低くなりますが、YOLOでは学習時に一枚の画像の全ての範囲を使うため、背景の誤検出は抑えることができます。
YOLOは現在v5まで出ており、現在進行形で成長しています。
出典:You Only Look Once:
Unified, Real-Time Object Detection
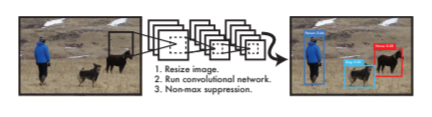
SSD
SSDはSingle Shot MultiBox Detectorの略で、精度はFaster R-CNNと同等程度あり、処理速度も早いという特徴を持っています。YOLO同様、リアルタイムでの物体検出が可能です。
物体検出の手法はYOLOと同じ手法を用いていますが、画像内に物体が多数あったとしても、YOLOより比較的正確に検出することができます。
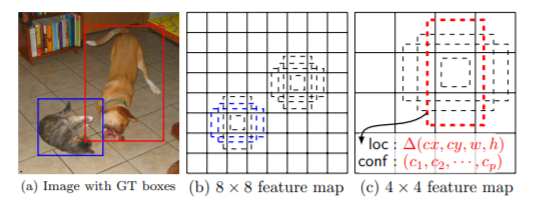
出典:SSD: Single Shot MultiBox Detector
DETR
DETRは今までの物体検出の方法にTransformerというモデルを融合させたモデルです。
言語処理に使われていたTransformerを画像処理に活用することにより、精度を保ちながら、並列計算をすることで高速な処理が可能になりました。
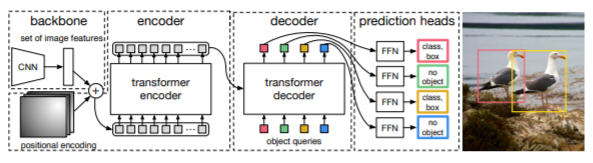
- Backbone:画像の特徴量をエンコードするためのCNNネットワーク。
- Transformer:CNNから取り出された画像の特徴量から注意機構を用いて各物体の位置や種類の情報へと変換。事前に決められた個数Nの物体を予測します。他の予測内容を見て自身の予測を忖度するEncoder-Decoderネットワーク。
- FFN:Transformerの出力を物体の位置座標・クラスラベルにデコードするネットワーク。
シンプルなモデルにもかかわらず高い物体検出精度を出せるのがDETRのの特徴です。
出典:End-to-End Object Detection with Transformers
OpenPose
OpenPoseは、深層学習(ディープラーニング)で、動画像から3次元の人物の体の骨格をリアルタイムで検出・推定することができるシステムです。1つのカメラによる動画や画像から、人の目や鼻などの顔のパーツから、首や肩、肘、手首、腰、膝、足首などの18カ所の関節点を検出することができ、それらを点と線で示して姿勢を推定できます。
また、モーションキャプチャーと異なり、GPUなどの高性能プロセッサを使えば、動画像内に複数人がいても、さらには複数人の体が重なり合っていても、リアルタイムに検出可能である点が特長です。

出典:姿勢推定ライブラリOpenPoseを用いた
機械学習による動作識別手法の検討
深層学習で動画に映る対象物を検出するレシピ12選
物体検出
01.画像/動画の物体検出を通じて、YOLOv4の技術性能と使い方を学べるレシピ
投稿者:@kanikani さん
YOLOv4 darknet を活用し、静止画像と動画、Webカメラからそれぞれリアルタイムに物体検出し、YOLOv4の高い技術性能を体感しながら、その使い方を学ぶことができます。
NVIDIA社が公開しているGPU向けのプラットフォーム「CUDA Toolkit」や、深層学習ライブラリ「cuDNN」を使用し、より実用的かつ高精度な物体検出、画像解析を行います。画像処理における深層学習の最先端を試し、進歩を実体験できます。
02.YOLOv5 と転移学習を使ってマスクの着用者と非着用者の顔検出を行うレシピ
投稿者:@lulu1351 さん
YOLOシリーズの新モデルYOLOv5を活用し、近年需要が高い、マスクの着用者と未着用者の顔検出を行うタスクを実際に体験できます。。
自分のデータセットでトレーニング(転移学習)を行い、Google Colaboratoryを使って、YOLOv5を動かし、TensorBoardツールを使って学習結果の可視化することができるようになります。
03. Facebook AIのDetectron2を使って物体検出とファインチューニングを行うレシピ
投稿者:@lulu1351さん
Facebook AIが開発したPyTorchベースの物体検出のライブラリDetectron2を用いて、様々な学習済みモデルの利用や動画データの物体検出への適用、カスタムデータセットを使ったトレーニング(ファインチューニング)などへの活用を学ぶことができます。
04. YOLOXをColaboratory上でトレーニングするレシピ
投稿者:@高橋かずひとさん
Colaboratory上での物体検出モデルYOLOXのモデルトレーニング方法を学ぶレシピです。
環境構築、モデルの訓練~推論までの一連の流れをGoogle Colaboratory上で実施します。
高精度・高速な物体検出モデルの生成に活用することができます。
3D物体検出
05.Unityで靴の3D物体検出を行うレシピ
投稿者:@高橋かずひとさん
Unity公式の推論ライブラリBarracudaを用いて、靴の3D物体検出を行います。
TensorFlowからONNXモデルへの変換方法および、変換モデルをUnity上で推論・可視化する扱い方を学ぶことができます。アパレル店やECサイト等で、靴の試着を行うアプリ開発等で応用することができます。
人物追跡
06.DeepSORTを用いた人物のトラッキングを行うレシピ
投稿者:@lulu1351さん
YOLO(物体検出)、ReId(同一人物照合)、SORT(トラッキング)のアルゴリズムが組み合わせた、**DeepSORT(Simple Online Realtime Tracking)**のアーキテクチャーを用いて、動画に映る人物の追跡を行います。
追跡したいオブジェクトを指定し、特定のオブジェクト(例えば車や人物など)をトラッキングする手法を学ぶことができます。商業施設やイベント会場などでの人の流れの統計や密集度合い、人と人との距離などの分析に活用できます。
07.ByteTrackで対象のオブジェクトが障害物に隠れても正しいラベルでトラッキングするレシピ
投稿者:@12kaz さん
ByteTrackの技術概要を理解し、任意の動画に映る複数の人物を追跡する方法を学びます。
店舗に入退室するユーザーの動線パターン分析、団体競技における選手の行動分析に活用することができます。
08.YoutuReIDを用いて人物再特定(Person ReIdentification)を行うレシピ
投稿者:@高橋かずひとさん
YoutuReIDを用いて人物再同定(Person ReIdentification)を行うレシピです。
人物再同定は人物再特定と呼ばれることもあります。
複数の監視カメラに映った同一人物の検出等に活用することができます。
09.TrackFormerで多人数を追跡するレシピ
投稿者:@12kaz さん
TrackFormerの技術概要を理解し、任意の動画に映る複数の人物を追跡する方法を学ぶレシピです。
店舗に入退室するユーザーの動線パターン分析、団体競技における選手の行動分析に活用することができます。
動画分類
10. Time-Space TransformerでYouTube動画を分類するレシピ
投稿者:@12kazさん
Time-Space Transformerの技術概要を解説し、Time-Space Transformerを用いた動画分類方法と、Time-Space TransformerモデルのFine tuning方法を学ぶレシピです。
スポーツ映像からプレー映像のみを抽出することによるハイライト動画生成、
映像への自動タグ付けに活用することができます。
合成・編集
11. 1枚の静止画を動画に合わせて動かすレシピ
投稿者:@jun40vnさん
1枚の静止画を動画に合わせて動かす「Motion Representations for Articulated Animation」についてモデル概要を説明し、Google Colabratoryで実装する方法を学べます。
静止画と動画を入力して、CNNを使った領域予測器によりヒートマップを求めます。体のパーツ毎に基準に対して静止画と動画がどれだけズレているかを計算し、その次に各ピクセルを適切な位置に再配置することで、静止画を動画に合わせて動かす動画の合成処理を行います。
12.PF-AFNでバーチャル試着を実装するレシピ
投稿者:@jun40vnさん
バーチャル試着は、Eコマースやファッション画像編集などの分野で様々なアプリケーションが発表されており注目されていますが、従来手法では、パース(人間が人物画像を上半身、下半身、腕、顔、髪などに区分すること)が必要であり、パースのわずかな間違いが生成する画像の質を大きく左右するという課題がありました。
最近のディープラーニング研究では、パースを必要としない WUTONが提案されています。このレシピは、WUTONにさらに改良を加えた最新のPF-AFNのモデル概要を説明し、実装を通してバーチャル試着の技術を体験できます。
13.自分の表情や顔の動きに合わせて、キャラクターアバターを動かすレシピ
投稿者:@kanikani さん
同じカテゴリの静止画と動画を使って、静止画を動画のように動かす、FOMM(First Order Motion Model)モデルを使用して、動画とWebカメラを通して、他人の顔画像や自分の顔画像を動かす画像処理の手法を学ぶことができます。
最終的には、Web接客のようなアバターを用いたサービス利用の実務を想定し、ZOOMで任意のアバター画像を表示し、自分の表情や顔の動きに合わせて動かしてみます。
14.MODNetで動画の背景を合成するレシピ
投稿者:@12kaz さん
MODNetの技術概要を理解し、動画から背景を削除しバーチャル背景を合成する方法を学ぶレシピです。
背景合成によるコストを抑えたプロモーション動画作成、リモート会議中のバージョン背景合成に活用することができます。
行動認識
15.SlowFastを用いた人物の行動認識を行うレシピ
投稿者:@lulu1351さん
FacebookのAI研究チームが人の行動認識のために開発したAIモデル SlowFastをつかい、動画に映る人物の行動認識を行います。物体検出ライブラリDetectron2を用いてSlowFastを実装し、カメラに映る人物の行動を認識する動画の物体検出の処理手法を学ぶことができます。
16.Openposeで動きの解析が可能なモーションキャプチャーを実装する
投稿者:@Micolash さん
YouTube動画を使用し、Openposeで人の動きの解析が可能なモーションキャプチャーの実装を行い、姿勢推定結果の簡単な精査を行います。
姿勢推定とは、人物の関節や骨格をはじめとした特徴点から座標データを検出し、人間の動きを可視化する技術で、
スポーツ選手のフォーム解析や、ダンス振付の矯正等に役立たせることができます。
17.PyMAFで動画から人の動きを3Dオブジェクトで推定するレシピ
投稿者:@12kaz さん
PyMAFの技術概要を理解し、動画から複数人の3Dオブジェクトを生成する方法を学ぶレシピです。
3D姿勢推定による作業員の作業負荷分析、姿勢情報の数値化によるリハビリ・ヘルスケア支援に活用することができます。
ジェスチャー推定
18.MediaPipeを利用して簡単なジェスチャーを推定するレシピ
投稿者:@高橋かずひとさん
MediaPipeを使って手のランドマークを検出し、ランドマークを元に動画上の簡単なジェスチャー認識を行う方法を学ぶことができます。
非接触操作システムでの活用例を参考にして、人差指の指先の軌跡から「静止」「時計回り」「反時計回り」の3種類のジェスチャーを認識するプログラムを作ります。ジェスチャー学習用データの取得から、ジェスチャー分類モデルの定義、作成、動作確認までの一連の開発を体験できます。
姿勢推定
19.MoveNetのキーポイントからボディランゲージを読み取るレシピ
投稿者:@高橋かずひと さん
TensorFlow Hubを用いた学習済モデルを利用し、高速な姿勢推定モデルMoveNetによるキーポイントの取得と、キーポイントからのボディランゲージの認識を学ぶことができます。
ボディーランゲージの認識や、防犯カメラの動画に映る不審な行動検出に応用できます。
20.OpenPoseでプロ野球選手のバッティングフォームを分析するレシピ
投稿者:@t25 さん
深層学習によって動画から人物検出や姿勢推定・骨格検出などができるシステムOpenPoseを用いて、ソフトバンクホークス柳田選手のバッティング動画から「重心位置の軌跡」を推定し、リアルタイムフォーム分析を行います。
OpenPoseのインストールおよびビルド方法、MotionAnalysisの利用法、YouTube動画のダウンロード方法と再生法、ffmpegによる動画のトリミング方法、動画から重心位置の軌跡の表示方法などについて学ぶことができます。
最後に
今回は、AxrossRecipeで学べる深層学習で動画に映る対象物を検出するレシピ を紹介しました。
AIを活用できる人材になるためのポイントは、
● 常に最新AI技術(モデルやライブラリ)やトレンド、ユースケースをキャッチアップすること
● AIを使って何かアウトプットを出す疑似体験を繰り返すこと
● 様々なAI技術を動かしてみて手触り感を把握すること
だと思います。
ぜひAxrossのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、AIを活用できる人材が少しでも多く増やすことができたらと思います。
