はじめに
※本記事は2022年8月16日に20個のレシピを追加し50選へと更新いたしました。
AxrossRecipeを運営している松田です。
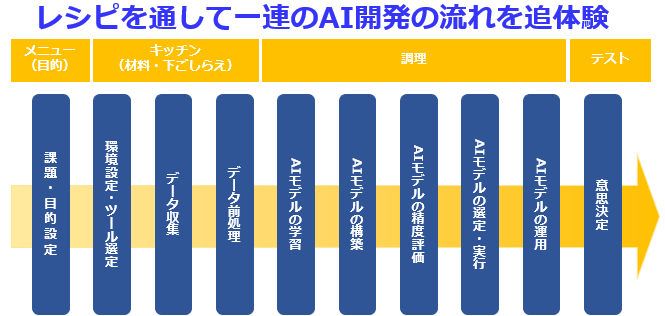
AxrossRecipe は、エンジニアの"アカデミックな教育"と"現場の業務"のスキルギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによるノウハウが"レシピ"として教材化されており、動くものを作りながらAI開発やデータ分析の流れを追体験できます。
AxrossRecipe: https://axross-recipe.com
Twitter: https://twitter.com/AxrossRecipe_SB
画像処理とは
画像処理は、「動画像のデータに対して、コンピュータが何かしらの処理を施すこと」の総称で、「画像認識」や「物体検出」、「画像合成・加工」等が該当します。
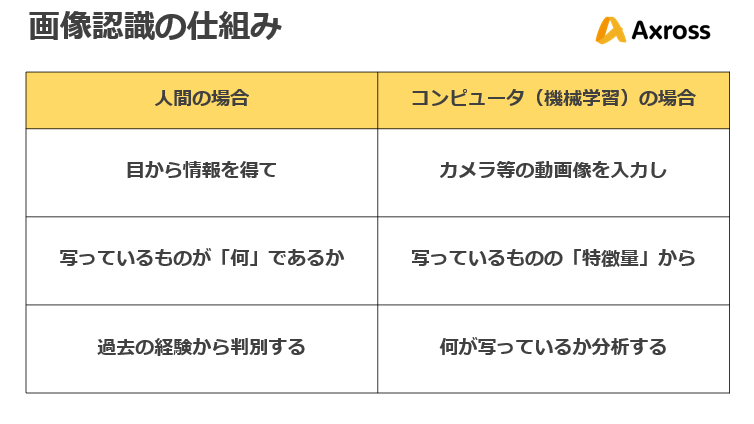
例えば、「画像認識」を例にすると、人間は目で見た情報に対して、過去の経験をもとに何が写っているかを判断しますが、コンピュータは、カメラ等から得た動画像の入力に対して、画像をピクセル(画素)の集まりから特徴量を抽出し、何が写っているかを識別します。
機械学習、ディープラーニングの手法の進化により、膨大な画像データを学習し、高速処理ができるようになったことで、画像認識精度が格段に向上しました。
世界中の研究者やGAFAM、BATHといった企業が競うように画像認識モデルを開発し、2015年には、ILSVRCという画像認識コンテストにおいて発表されたモデルが、エラー率で人間の認識能力を超越しました。
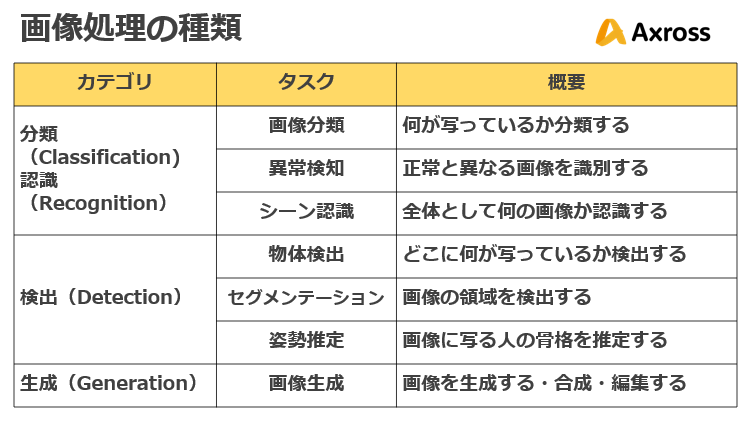
画像処理の種類
画像処理の種類は、大きく分けて下記表のように分類できます。
画像認識(Image Recognition)
画像認識は、画像に「何が映っているか」を認識できる技術です。
コンピュータは、画像をピクセル(画素)のパターンから色や形などの特徴を抽出し、その類似の範囲や差異を学習させることで、画像に映ったものは何かを認識し、識別、分類などの処理を行えるようになります。
画像分類(Image Classification)
画像分類は、画像認識技術の延長で、画像に写っているものを識別し、特徴別に分類する技術です。
異常検知
異常検知は、画像認識技術の応用で、正常時の画像データを元に画像の異常有無を判断する技術です。
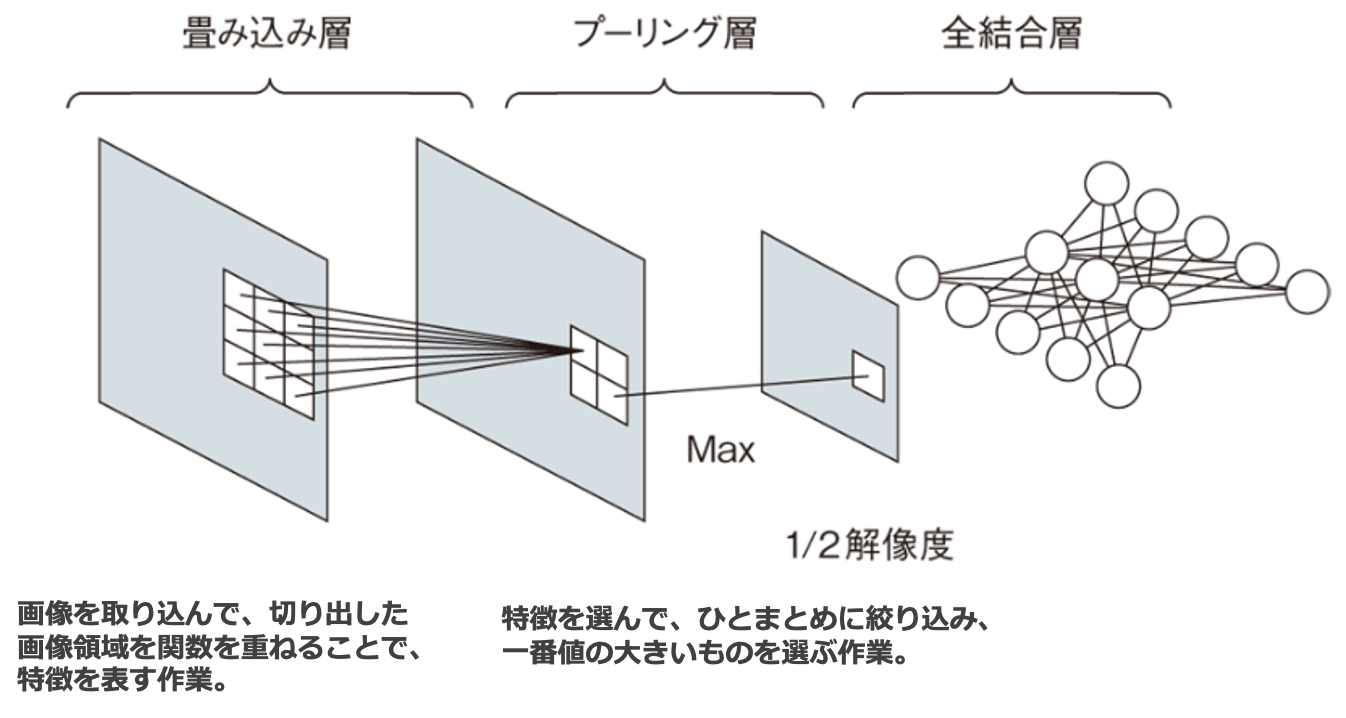
畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)
CNNは、画像データをそのまま入力し、「畳み込み」と「プーリング」を交互に行なうことで、画像の特徴を抽出し認識する 画像処理の分野で利用するニューラルネットワークです。
物体検出(Object Detection)
物体検出は、動画像の中から定められた物体の位置と種類、個数を特定する技術です。
YOLO
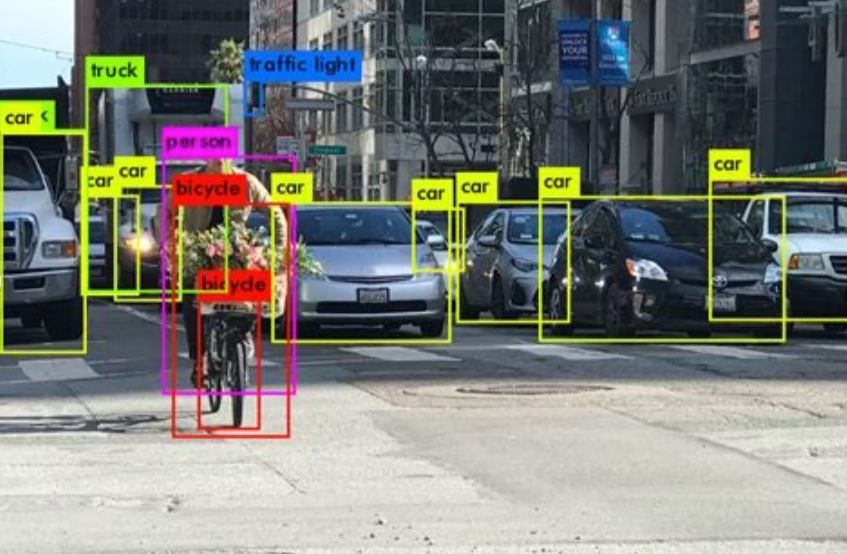
YOLOは、リアルタイムに物体を矩形で囲んで、オブジェクト検出を行うアルゴリズム です。YOLOという名前の由来は、「You Only Look Once」という英文の頭文字をつなげて作られた造語で、「一度見るだけで良い」というリアルタイムでの検知の意味を持っています。
YOLOの物体認識の手法は、予め画像全体をグリッド分割しておき、各領域ごとで物体の種類と位置を求めます。
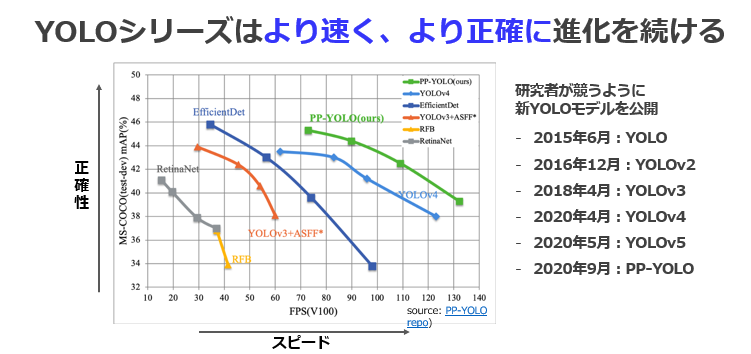
YOLOは、現在v5まで出ており、現在進行形で進化しています。
動画像のような2次元データのみならず、3次元データ(3Dモデル)も取り扱うことができます。
姿勢推定(Pose Estimation)
人物の関節や骨格をはじめとした特徴点から座標データを検出し、人間の動きを可視化 する技術手法です。

出典:Multi-Person Pose Estimation with Local Joint-to-Person Associations
姿勢推定の有名なアルゴリズムとして、OpenPose がありますが、深層学習(ディープラーニング)で動画像から人物の骨格をキーポイントとして検出し、3次元的に身体の動きをリアルタイムに推定することができます。
セグメンテーション(Segmentation)
セグメンテーションは、画像の各ピクセル(画素)に対して、何が写っているかといったラベルやカテゴリを関連づけて色分け を行う技術です。

出典:Introduction to Semantic Image Segmentation
距離測位(Distance Positioning)
距離測位は、画像データから、物体までの距離(奥行)を推定し、物体の寸法を測定 する技術です。
画像生成(Image Generation)
画像生成は、ディープラーニング(深層学習)を利用し、画像やデザインの生成や、動画像の加工・編集を行う技術です。
敵対的生成ネットワーク(Generative Adversarial Networks:GAN)
GANは、2014年にイアン・グッドフェローらによって「Generative Adversarial Nets」という論文で発表されたディープラーニング技術で、互いに競合する2つのニューラルネットワークモデルを用いて、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換する 画像生成モデルです。
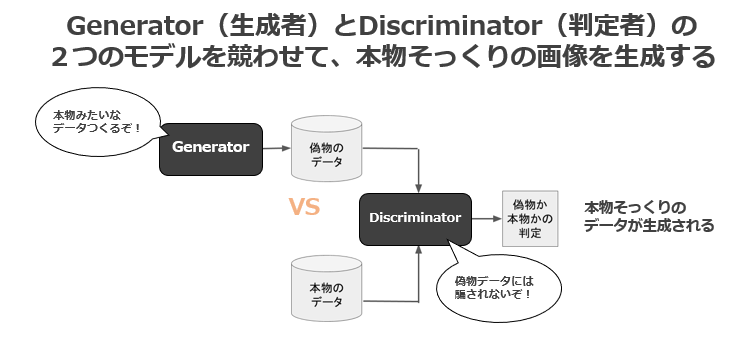
GANは、深層学習で最も熱い分野の1つであり、世界中の研究者が応用モデルを開発し、今では人間が見分けがつかないほどの高い精度で画像生成できるようになっています。

画像合成・編集
複数の画像データを合成・編集する技術です。GANを応用することで、「ディープフェイク」とも呼ばれ、自由自在に高い精度での画像合成が実現ができます。
超解像化(Super Resolution)
超解像は、動画像の入力信号の解像度を高めて出力信号を作り出す 技術のことです。これにより、解像度の高い映像や画像を出力できます。
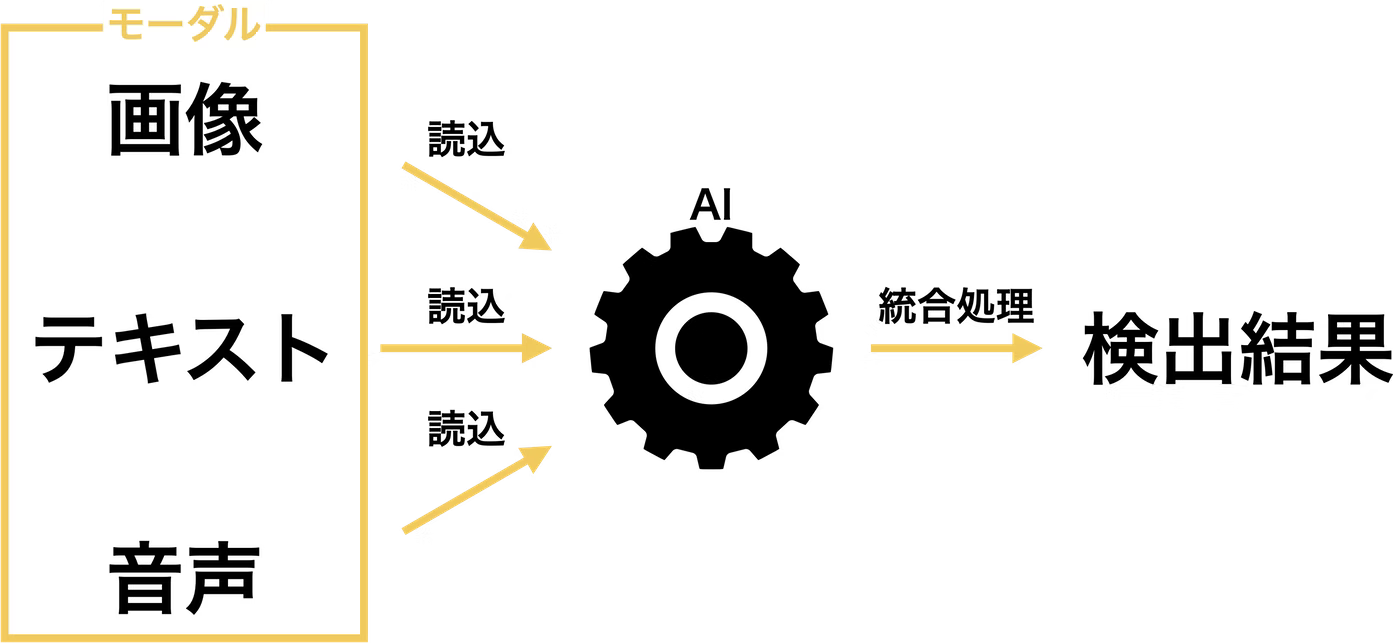
マルチモーダル処理(Multi-modal Information Processing)
マルチモーダル情報処理とは、画像や音声、テキストなどの複数モーダルのデータをコンピュータで処理 して、予測や分類を行う技術のことで、ディープラーニング(深層学習)と組み合わせて利用されます。
様々な種類の情報を入力として、複合的に予測・判断・実行できるAI「マルチモーダルAI」の開発は今後のトレンドとなっています。
AI画像処理を学べるレシピ紹介
画像認識
01 . DjangoとPytorchを使って花を認識するwebアプリを作成するレシピ
花の種類をPyTorchを使って画像認識し、WebアプリケーションフレームワークのDjangoを使って花の種類検索Webアプリを作成します。
機械学習による簡易的な画像認識Webアプリの開発に活用できます。
02 . PyTorchによる画像認識最強モデル「EfficientNet」実装!
層の深さ、層の幅、入力画像サイズの3つのちょうどよいバランスを提案する最強の画像認識の深層学習モデル「EfficientNet」を実装します。
顔認証や自動運転、医療画像診断、製造現場での検品などに活用できます。
03 . あなたのPCをPepperのような表情認識ロボットにできるレシピ
pazというロボット開発OSSライブラリを用いて、対話する人の表情を認識して発話するボットを開発します。
Pepperのようなコミュニケーションロボットの開発に応用できます。
画像分類
04 .CNNもAttentionも使わないMLP-Mixerを用いて任意の画像を1000クラス分類するレシピ
「MLP-Mixer」のImageNetによる学習済みモデルを活用した任意の画像の1000クラス分類の実装を行います。
ユーザが投稿した写真の自動分類やアルバムに保存されている写真の情景分類に活用できます。
05 . ml5.jsを用いてブラウザでAIを動かすレシピ
webアプリケーションフレームワークであるDjangoでwebアプリを開発し、ml5.jsを用いてブラウザ上で画像分類、物体検出、顔のランドマーク検出を動かす方法を学べます。
Webサービスにアップロードした写真の自動タグ付けに活用できます。
06 . TensorFlow.jsを用いてブラウザで画像処理モデルを実行するレシピ
webアプリケーションフレームワークであるDjangoでwebアプリを開発し、Tensorflow.jsを用いてwebアプリに画像分類・物体検出機能を搭載する方法をご紹介します。
Webサービスにアップロードした写真の自動タグ付けに活用することができます。
07 . BERTをImage Transformersに応用したBEiTで画像分類するレシピ
2021年6月に論文発表されたBEiTの技術概要や、BEiTを用いた画像分類方法、画像分類モデル構築方法を学びます。
商品写真から商品カテゴリを分類することによる自動タグ付け、製品画像から製品状態を分類する製自動判定に使用することができます。
08 . OpenAIのCLIPを使った、ゼロショット画像分類(学習を必要としない画像分類)を実装するレシピ
画像と画像を説明するテキストのペア4億組を学習させた画像分類モデル「CLIP」による、ゼロショット画像分類(全く学習を行わずに画像分類)を行います。
動画分類
09 . Time-Space TransformerでYouTube動画を分類するレシピ
Time-Space Transformerの技術概要を解説し、Time-Space Transformerを用いた動画分類方法と、Time-Space TransformerモデルのFine tuning方法を学びます。
スポーツ映像からプレー映像のみを抽出することによるハイライト動画生成、映像への自動タグ付けに活用することができます。
異常検知
10 . 生産ラインを想定した画像異常検知の実装レシピ
工場の生産ラインの不良品検出を想定して、オートエンコーダモデル と サポートベクトルマシン を構築し、一様なパターンを持つ画像の異常検知をし、異常部分をマーキングします。
工場生産ラインでの異常検知に活用できます。
11 . PyTorchを使ってGANによる異常検知を行うレシピ
深層学習 GAN を画像の異常検知領域に応用した「AnoGAN」と「EGBAD」をPyTorchを使って実装します。
工場での外観検査や製造ラインの不純物の検知、農作物の品質検査、医療画像からの疾患検査に活用できます。
画像検索
12 . クエリ画像に類似する画像をDBの中から探索するレシピ
複数枚の画像が格納されているデータベースから、入力した画像に最も類似する画像を探索(検索)する方法を学べます。
ディレクトリにある複数の画像の中から、入力画像に最も類似している画像を探索することに活用することができます。
12 . Arcfaceを用いた類似顔画像検索アプリケーションの実装レシピ
Arcfaceモデルを用いて顔画像の類似度を算出し、類似顔画像を検索するアプリケーションを作成します。
顔領域の検出から顔領域の補正、特徴抽出、最終的な類似度算出、可視化による定性的な評価を行うまでの処理フローを一通り実装しています。
感情認識
14 . 顔画像から表情を認識するレシピ
Multi-task EfficientNet-B2の技術概要や、Multi-task EfficientNet-B2を用いた顔の表情認識(Facial Expression Recognition)方法を学びます。
車載カメラを用いた運転手の表情のモニタリング、新製品モニターの表情を識別することによる効果測定の際に活用できます。
物体検出
15 . 学習済みSSDを少量のデータでファインチューニングし、新たなクラスの物体検出を行うレシピ
PyTorchの「SSD」モデルを利用して物体検出の学習済みモデルをファインチューニングし、少量データでかつ短時間の学習で新たなクラスの物体検出を実現します。
少量のデータ・短時間の学習で新たなクラスを物体検出する際に活用できます。
16. オリジナルデータにおける「物体検出モデル YOLOv4」の学習と検出
Python + AI技術の学習として、オリジナルデータにおける「YOLOv4」による物体検出の学習と検出実行を学べます。
人流解析、歩行者分析や交通量調査などに活用できます。
17. 検出クラスは2万越え! Deticを使って物体を検出しよう
2022年にMeta(旧Facebook)が発表した「Deitc」の技術概要、Deticの動かし方などを学べます。
製造業の外観検査や医療画像の病状検出、自動運転の人物検出に活用できます。
18. ReDetで航空写真・衛星画像を物体検出するレシピ
2021年3月に論文発表されたReDetの技術概要や、ReDetを用いた航空写真の物体検出方法、モデル構築方法を学びます。
無人航空機の撮影画像を物体検出することによる建物の被害状況把握、航空写真から特定の樹木を物体検出することによる森林調査に活用することができます。
19. MaskRCNNによるオリジナル画像の物体認識レシピ
数ある画像認識AIの中で、インスタンスセグメンテーションのタスクを解く「MaskRCNN」の環境構築、使い方を学びます。
MaskRCNNによる画像認識そのものの活用、画像のannotation, augmentation処理方法の各種AIでの学習への転用に活用することができます。
20. YOLOXをColaboratory上でトレーニングするレシピ
Colaboratory上での物体検出モデルYOLOXのモデルトレーニング方法を学びます。
高精度・高速な物体検出モデルの生成に活用することができます。
文字検出
21 . AIOCRの鍵を握る文字検出モデルを作成するレシピ
AIOCRの技術説明と共に、オープンソースであるPaddleOCRを使った文字検出や文字検出モデルのトレーニング方法を学びます。
請求書・領収書の入力作業補助、免許証等身分証明書の入力作業補助に活用することができます。
モーション検知
22 . Openposeで動きの解析が可能なモーションキャプチャーを実装する
「OpenPose」を用いて動きの解析が可能なモーションキャプチャーの実装を学びます。
モーションキャプチャー、スポーツのフォーム解析に活用することができます。
姿勢推定
23 . OpenPoseでプロ野球選手のバッティングフォームを分析するレシピ
「OpenPose」を用いて野球選手の動画から人物検出・姿勢推定、骨格検出を行い、重心位置の軌跡を推定してバッティングフォームを解析します。
スポーツにおける動作フォームの解析(競技力向上やケガの防止)や工場や建設現場、病院リハビリ等での正しい作業/動作フォームの分析・教育に活用できます。
24 . SlowFastを用いた人物の行動認識を行うレシピ
Faccebook社が開発した人物の行動認識を行うライブラリ「Detectron2」を用いて「SlowFast」を実装し、カメラに映る人物の行動認識を行います。
コンビニやスーパーの万引き対策や禁煙エリア(学校や病院、行政機関が敷地内)の喫煙等の防止に活用できます。
25 . MoveNetのキーポイントからボディランゲージを読み取るレシピ
TensorFlow Hubを用いた学習済モデルを利用し、高速な姿勢推定モデル「MoveNet」によるキーポイントの取得と、キーポイントからのボディランゲージの認識を行います。
ジェスチャーの認識や防犯カメラ画像の不審行動の検出に活用できます。
人物追跡
26 . ByteTrackで対象のオブジェクトが障害物に隠れても正しいラベルでトラッキングするレシピ
ByteTrackの技術概要を理解し、任意の動画に映る複数の人物を追跡する方法を学びます。
店舗に入退室するユーザーの動線パターン分析、団体競技における選手の行動分析に活用することができます。
27 . YoutuReIDを用いて人物再特定(Person ReIdentification)を行うレシピ
YoutuReIDを用いて人物再同定(Person ReIdentification)を行うレシピです。
複数の監視カメラに映った同一人物の検出に活用することができます。
セグメンテーション
28 . セマンティックセグメンテーションで道路画像から人や車を認識するレシピ
自動運転における周囲環境把握を想定し、PyTorchによるセマンティックセグメンテーション手法「PSPNet」を活用して道路画像から人と車を識別します。
セマンティックセグメンテーションによる画像の中の物体検出する際に活用できます。
29 . 航空写真からアノテーションデータを作成して、対象物を抽出するセマンティックセグメンテーションモデルを作成するレシピ
Tellusの衛星データを用いてゴルフ場コースを セマンテックセグメンテーション で検出します。
衛星画像や航空写真、ドローンによる空撮画像から、機械学習によって対象物を検出するセグメンテーションモデルを構築する際に活用できます。
30 . Python + EdgeNets(ESPNetv2)をオリジナルデータで物体の色分け(セマンティックセグメンテーション)を実装する
「EdgeNets(ESPNetv2)」によるセマンティックセグメンテーションのオリジナルデータにおける学習を学べます。
自動運転やMRI画像の臓器判別、コンクリートの劣化領域の検出する際に活用できます。
距離測位
31 . 単眼デプス推定を用いて距離を計測するレシピ
単眼デプス推定モデルのMiDaS v2.1 の推論結果に対し、シンプルなキャリブレーションを行い、距離を測定します。
カメラを使用した簡易な距離計測に活用できます。
画像生成
32 . StyleGANで本物と区別がつかない画像を生成するレシピ
学習済み「StyleGAN」とデータセットを用いて、本物と区別がつかない存在しない人物の顔画像を生成します。
存在しない人物画像の生成する際に活用できます。
33 . CLIP+GANでテキストから画像を生成するレシピ
「CLIP+GAN」で構成されるFuseDreamの技術概要を解説し、実際にテキストから画像を生成する方法を学べます。
デザインアート(製品、建造物など)や自然言語表現で指定した画像を生成し広告への活用できます。
34 . Pythonでモザイクアート画像を作成するレシピ
Pythonでモザイクアート画像を作成するレシピです.
このレシピでは一般的な画像データセットからモザイクアート画像を作成するものになっていますが、画像を差し替えることで自分の好きな画像でモザイクアート画像を作成することができます。
Python画像処理(リサイズ、配列のスライス、色補正)、ファイルの一括処理方法を学ぶこととしても活用することができます。
35 . Latent Diffusion Modelsを用いてテキストから画像を生成するレシピ
Latent Diffusion Modelsの技術概要を理解し、Huggingfaceのdiffusersライブラリを用いて、テキストから画像を生成する方法や、モデルが画像を生成する過程をアニメーションで可視化する方法をを学べます。
製品、建造物などデザインアートへの利用、自然言語表現で指定した画像を生成し広告への活用ができます。
36 . GLIDEで様々な条件を指定したテキストから画像を生成するレシピ
GLIDEの技術概要を理解し、論文発表元が公開するミニモデルGLIDE(filterd)を用いて、テキストから画像を生成する方法や、テキストに応じた画像修復方法を学べます。
g製品、建造物などデザインアートへの利用、自然言語表現で指定した画像を生成し広告への活用ができます。
動画生成
37 . CLIP+GANでテキストから動画を生成するレシピ
CLIP+GANで構成されるFuseDreamの技術概要を理解し、テキストから以下のような動画を生成する方法を学べます。
CLIP+GANアプローチはトレーニングが不要で、ゼロショットで、様々なジェネレータで簡単にカスタマイズできます。
画像合成・編集
38 . StyleGAN+CLIPモデルで、テキストによる顔画像の編集を行うレシピ
StyleGANとCLIPモデルを実装し、編集したい内容をテキストで指示できる汎用性を持たせ、ランドマークに合わせた顔画像の切り出し、顔画像を生成する潜在変数の推定・編集を学べます。
顔画像の編集に活用できます。
39 . 1枚の静止画を動画に合わせて動かすレシピ
Motion Representations for Articulated Animationを使い、静止画を動画に合わせて動かす動画像合成処理を行います。
メタバース空間でのアバター作成など、動画処理に活用できます。
40 . PF-AFNでバーチャル試着を実装するレシピ
ECやアパレルで活用されているバーチャル試着について、パースを必要としないWUTONを改良した最新深層学習モデルPF-AFNを実装します。
Eコマースやファッション画像編集に活用できます。
41 . Python + CycleGANでオリジナルデータを学習し、白黒画像をカラー画像に変換するレシピ
Python + 画像変換技術の学習として、オリジナルデータにおける「CycleGAN」の学習と画像変換を学べます。
白黒画像のカラー変換や実写から絵画への変換、顔などの特定箇所に画像加工(モザイク)する際に活用できます。
精度向上
42 . EfficientNetとEfficientNetV2の画像分類精度を比較するレシピ
EfficientNetとEfficientNetV2の技術概要を理解し、それぞれを用いたFine Tuningの方法を学べます。
商品写真の画像分類による自動タグ付け、製品画像から製品の状態を自動判定に活用することができます。
43 . 【PyTorch】精度爆上げのオレオレベストプラクティスを10個まとめてみた!
機械学習の画像分類モデル精度を実務レベルまで上げるための10個のベストプラクティスを学べます。
ノイズ消去
44 . DRUNetを用いて画像のノイズ除去を行うレシピ
DRUNetというディープラーニングを用いた画像のノイズ除去のアルゴリズムを実際にプログラムを動かしながら学べます。
ディープラーニングによる画像のノイズ除去、画像回復アルゴリズム開発に活用することができます。
3Dモデル
45 . Unity上で靴の3D物体検出を行うレシピ
Unityの推論ライブラリBarracudaを用いて、靴の3D物体検出を学べます。
靴の試着アプリの開発に活用できます。
46 . 3次元点群のディープラーニング応用レシピ
自動運転技術の分野で活用されている、3Dデータ形式の3次元点群の基礎とディープラーニングへの応用について学べます。
車の自動運転や人間とロボットの協働作業に活用できます。
47 . PyMAFで動画から人の動きを3Dオブジェクトで推定するレシピ
PyMAFの技術概要を理解し、動画から複数人の3Dオブジェクトを生成する方法を学びます。
3D姿勢推定による作業員の作業負荷分析、姿勢情報の数値化によるリハビリ、ヘルスケア支援に活用することができます。
超解像化
48 . PULSEを動かして超解像を学習するレシピ
超解像手法の一つである「PULSE」の技術概要、使い方などを学べます。
印刷に耐えない低画質データや歴史写真の高解像度化に活用できます。
マルチモーダル
49 . PyTorchを活用し画像のキャプションを自動生成するレシピ
PyTorchによるオートエンコーダモデルを使って、画像キャプションを自動生成するレシピです。
発展編では、画像の特徴量をTransformerに入力させ、AttentionとBeam Searchを利用してより高精度な画像キャプションを自動生成します。
画像の下にキャプション(画像の説明文)を入れる場面(WEBセミナーでの説明やプロモーション動画制作、教育面)で活用できます。
50 . 深層学習モデルを活用し、画像から音楽を生成するレシピ
エンコーダーデコーダによる画像分類と言語生成のディープラーニングモデルを用いて、画像から音楽BGMを自動生成するレシピです。
動画のBGMを自動作成する際や視覚障害者の方へのイメージの伝達の際に活用できます。
最後に
いかがでしたでしょうか。
今回は、さまざまなAI画像処理の手法を学べるレシピ50選をご紹介しました。
プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
AxrossRecipeのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。
