はじめに
はじめまして、Axrossを運営している藤原です。
Axross とは、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いのもと、ソフトバンクと社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウを"レシピ"として教材化し、実際にプログラミングで実装を追体験しながら学ぶことができます。
なぜ"レシピ"なのかと言うと、実行環境やツール、ライブラリのバージョン、データセットなどを定義して実際にものをつくりながら学ぶための教材としての品質維持や学びやすさを追求するためのフレームワーク設計と、「料理をつくるように 楽しく 手軽にものづくりができたら」というAxrossメンバーの想いで学習教材を料理の"レシピ"に喩えて提供しています。
現在は、AI/機械学習をテーマにした、様々な業務領域やビジネスの課題解決に応用できる実践的な学習教材を140以上揃えています。(2021年6月時点)
Axross:https://axross-recipe.com

今回は、AIを活用した物体検出の考え方と物体検出の代表的な手法を紹介し、Axrossのサービスで無料で学べるレシピの中から、動画や画像に映る人や物に対して、AI/機械学習を用いて抽出する 物体検出 の人気レシピをご紹介します。

物体検出とは
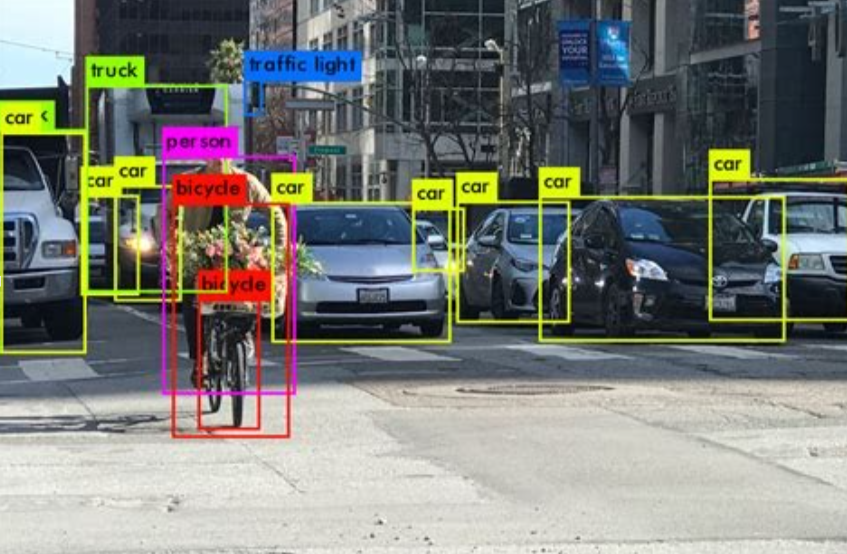
物体検出は、画像を取り込み、画像の中から定められた物体の位置と種類、個数を特定するという技術です。画像から物体の種類を分類するのは、画像分類でも行えますが、物体検出ではそれに加え、
- 物体の領域の位置を矩形で予測し絞り込む方法
- 認識対象以外の物体を排除する方法
というような手法を取り入れることで、画像に写る対象物の位置・個数の検出を可能にしています。

物体検出は、製造業や建設業、流通小売、医療、セキュリティなど業種を問わず幅広い分野で活用されています。
例えば、自動運転車における歩行者の検出、ドローンを活用した高所設備のメンテナンス、スタジアムのマスク着用率の計測、監視カメラの動画における人の購買行動分析、CT医療画像から体の異常部位の検出...、挙げたらきりがないぐらいです。
身近な例では、Facebookのタグ付け機能やGoogle Lensの画像検索機能、顔などを検出のためのスマートフォンのカメラにも利用されています。
物体検出の種類と仕組み
物体検出は主に「CNN(畳み込みニューラルネットワーク)」というものを利用しています。
CNNとは、ディープラーニングで用いられるネットワークの中で、画像からパターンや物体を認識するための有名な手法の1つです。
畳み込み演算とプーリング+活性化関数を活用した画像の特徴の強調を繰り返すことで、画像の部分的な特徴と全体的な特徴を学習していき、画像の特徴量の学習を最適化していきます。
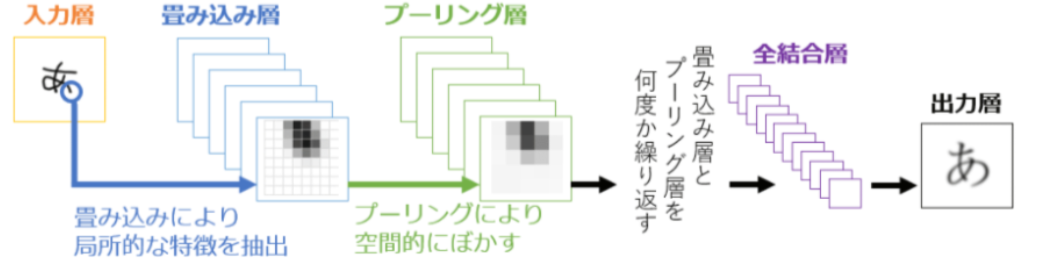
出典:CNN(Convolutional Neural Network: 畳み込みニューラルネットワーク)とは?
物体検出の代表的な手法をいくつか紹介します。
R-CNN
R-CNNは、ディープラーニングを用いた物体検出の先駆け的な存在です。

- 画像を入力する
- 画像の中から、物体が写っている領域の候補(Region Proposal)を抽出する
- CNNを用いてそれぞれの候補の特徴量を計算する
- それぞれの領域に何が写っているか分類する
これによって、今までのディープラ−ニングを用いない画像処理方法より、高精度の物体検出が実現できるようになりました。一方で、R-CNNはそれぞれの項目ごとで別々に学習する必要があり、学習に非常に時間がかかり、メモリの消費量も大きいという課題がありました。
これを解決するために、Fast R-CNNやFaster R-CNNが開発されました。
Faster R-CNNの開発により、画像の入力から物体の検出まで一気に学習・推定ができるようになり、学習時間・メモリの消費量ともに大幅に削減し、約10倍の高速化を実現しました。
出典:Rich feature hierarchies for accurate object detection and semantic segmentation
Tech report (v5)
出典:Faster R-CNN: Towards Real-Time Object
Detection with Region Proposal Networks
YOLO
YOLOは、You Only Look Onceの略で、処理速度が非常に早い のが特徴です。そのため、リアルタイムの物体検出をすることができます。
YOLOの物体認識の手法は、予め画像全体をグリッド分割しておき、各領域ごとで物体の種類と位置を求めます。
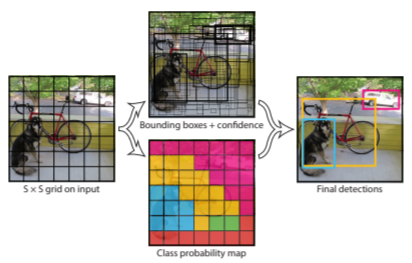
物体が多数写っている場合は、識別精度が低くなりますが、YOLOでは学習時に一枚の画像の全ての範囲を使うため、背景の誤検出は抑えることができます。
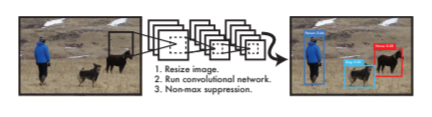
YOLOは現在v5まで出ており、現在進行形で成長しています。
出典:You Only Look Once:
Unified, Real-Time Object Detection
SSD
SSDはSingle Shot MultiBox Detectorの略で、精度はFaster R-CNNと同等程度あり、処理速度も早いという特徴を持っています。YOLO同様、リアルタイムでの物体検出が可能です。
物体検出の手法はYOLOと同じ手法を用いていますが、画像内に物体が多数あったとしても、YOLOより比較的正確に検出することができます。
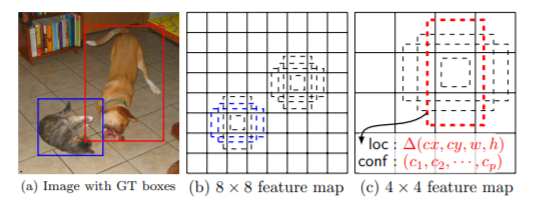
出典:SSD: Single Shot MultiBox Detector
DETR
DETRは今までの物体検出の方法にTransformerというモデルを融合させたモデルです。
言語処理に使われていたTransformerを画像処理に活用することにより、精度を保ちながら、並列計算をすることで高速な処理が可能になりました。
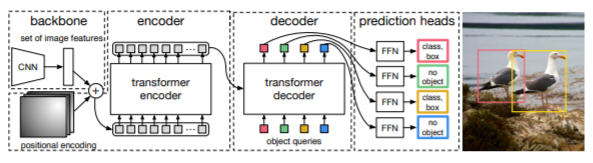
- Backbone:画像の特徴量をエンコードするためのCNNネットワーク。
- Transformer:CNNから取り出された画像の特徴量から注意機構を用いて各物体の位置や種類の情報へと変換。事前に決められた個数Nの物体を予測します。他の予測内容を見て自身の予測を忖度するEncoder-Decoderネットワーク。
- FFN:Transformerの出力を物体の位置座標・クラスラベルにデコードするネットワーク。
シンプルなモデルにもかかわらず高い物体検出精度を出せるのがDETRのの特徴です。
出典:End-to-End Object Detection with Transformers
Axrossで学べる人気物体検出レシピ
Axrossでは、様々な動画や画像から物体検出を実践するためのAI活用レシピを公開しています。その中で、無料で学習できる人気レシピを紹介します。
[TensorflowのObject Detection APIで道路標識検出モデルを訓練するレシピ] (https://axross-recipe.com/recipes/158)
投稿者:@KzhtTkhs さん
TensorFlow Object Detection APIを用いて、オリジナルデータで画像の中の関心対象の物体を自動で背景から区別して物体検出する機械学習モデルの作成方法を学べます。
自動運転の仕組みを想定し、道路標識の「一時停止」を検出するタスクを通して、環境構築から、自前データの取得、アノテーション、モデルの構築、訓練、結果の推論まで一通りの物体検出/画像処理の流れをGoogle Colaboratory上で体験することができます。
画像/動画の物体検出を通じて、YOLOv4の技術性能と使い方を学べるレシピ
投稿者:@katkazzzzzさん
YOLOv4 darknet(リアルタイムオブジェクト検出アルゴリズム)による静止画像、動画、Webカメラの身近な画像 それぞれにおける物体検出をおこない、YOLOv4のモデルアーキテクチャーと技術性能、使い方を学ぶことができます。
NVIDIA社が公開しているGPU向けのプラットフォーム「CUDA Toolkit」と、深層学習ライブラリ「cuDNN」を使用し、より実用的かつ高精度な物体検出、画像解析を行います。画像処理における深層学習の最先端を試し、YOLOの進歩を実体験できます。
学習済みSSDを少量のデータでファインチューニングし、新たなクラスの物体検出を行うレシピ
投稿者:@jun40vnさん
物体検出の学習済みモデルをファインチューニングすることによって、少量のデータでかつ、短時間の学習で新たなクラスの物体検出を実現する方法を、SSD(Single Shot MultiBox Detector)のサンプルコードを実行しながら解説します。
BCCD DatasetをPyTorchのSSDモデルで読み込んで利用し、学習済モデルによるVOCクラスの物体検出とファインチューニングによる新たなクラスの物体検出を学ぶことができます。
航空写真からアノテーションデータを作成して、対象物を抽出するセマンティックセグメンテーションモデルを作成するレシピ
投稿者:@regonn_haizine さん
Tellusの衛星データを用いたゴルフ場コースのセマンティックセグメンテーションタスクを例に、衛星画像等のリモートセンシングデータに対象物がどこに写っているのかを判別するモデル作成の一連の流れを体験しながら学ぶことができます。
画像データの取得から始め、アノテーションデータを追加してデータセットを作成し、その自作データセットを用いて予測モデルを作成します。衛星画像・航空写真・ドローン空撮画像から、機械学習で対象物を検出するセグメンテーションモデルを作成できるようになります。
Raspberry piでリアルタイムにディスプレイを読み取るレシピ
投稿者:@KzhtTkhs さん
OpenCVを用いて7セグメントの画像認識モデルを作成し、TensorFlow Lite形式に変換してRaspberry pi上で数値の推論を行います。
カメラ設置を想定し、射影変換による画像の前処理と、OpenCVを用いた画像処理、TensorFlow Keras Applicationsを用いた画像分類モデルの構築~評価までの一連の開発について学べます。デジタルメータの定点監視に活用できます。
簡単な顔画像認識を機械学習で処理するレシピ
投稿者:@asr さん
顔画像データセットに対して、データの収集⇒データの観察⇒モデルの実装⇒モデルの改善 という流れで、サポートベクタマシン(SVM)を用いたクラス分類モデルの実装を行います。
Google Colaboratoryを使ってscikit-learn組み込みの顔画像データに対して、基本的な機械学習の流れをポイント解説を交えながら体験することができるため、Python初心者におすすめです。
最後に
今回は、Axrossで無料で学べる、物体検出のテーマの人気レシピをご紹介しました。
AIを活用できる人材になるためのコツは、様々なテーマで実際にAIを実装する体験を繰り返すことだと思います。
Axrossのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。

また、Axrossでは自身のナレッジを学習教材"レシピ"として寄稿いただけるエンジニアの方も募集しています!
見習いエンジニアから募った学びたい内容をウィッシュリストとして掲載しています。募集中のテーマからご自身で作成いただけるようでしたら、レシピ作成にご協力お願いいたします。