はじめに
Axrossを運営している松田です。
Axross は、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、実際の業務に近いテーマで、動くものを作りながら学ぶことができます。
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/Axross_SBiv
機械学習の概念
機械学習とは
機械学習(Machine Learning) とは、データを「機械(コンピューター)」で反復的に「学習」することによって、未知のデータに対する結果を予測する技術です。
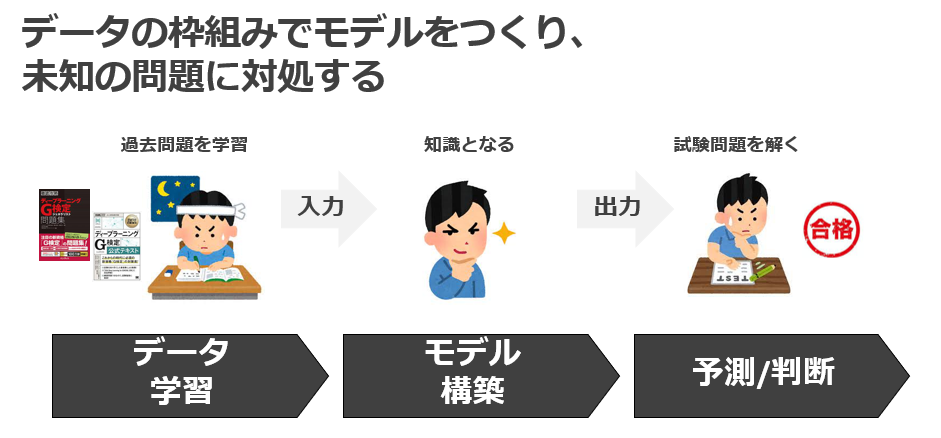
機械学習を、受験生の勉強に喩えて表現すると、
受験生が、参考書や過去問(データ)を入手(インプット)して反復学習し、良い点数を取るために自身の脳(モデル)を鍛え、試験問題(未知のデータ)に対して回答(アウトプット)を出します。
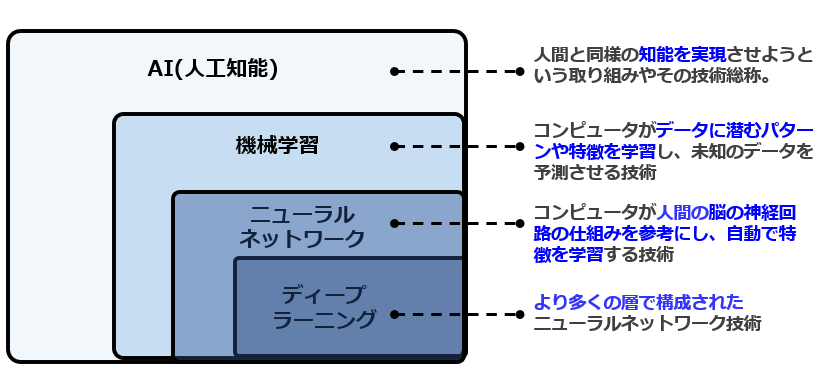
機械学習は、人工知能(AI)の概念の1つの手法で、機械学習の代表例が、ニューラルネットワークであり、ディープラーニングです。
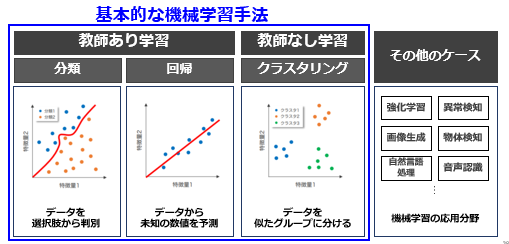
機械学習の種類
機械学習の手法は大きく分けると、「教師あり学習」、「教師なし学習」、強化学習などの「その他のケース」の3種類があり、今回は教師あり学習と教師なし学習を解説します。
教師あり学習
教師あり学習とは、正解のあるデータをもとに学習する手法です。
学習データと正解データをセットで与え、未知のデータをカテゴリ分類したり、数値を予測する ときに利用します。
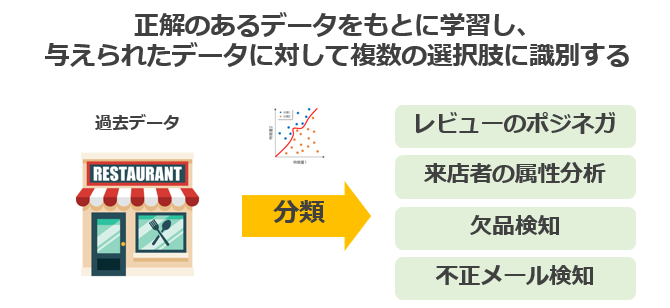
分類(Classify)
分類 とは、与えられたデータに対して、いくつかの選択肢(カテゴリ)の中からどれに対応するか判別 する方法です。
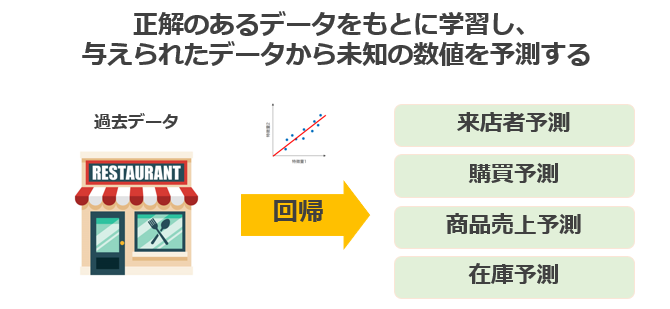
回帰(Regression)
回帰 とは、選択肢の中から該当するものを当てるのではなく、与えられたデータから 未知の数値を予測 する方法です。
教師なし学習
教師なし学習とは、正解のないデータを基に学習する手法です。
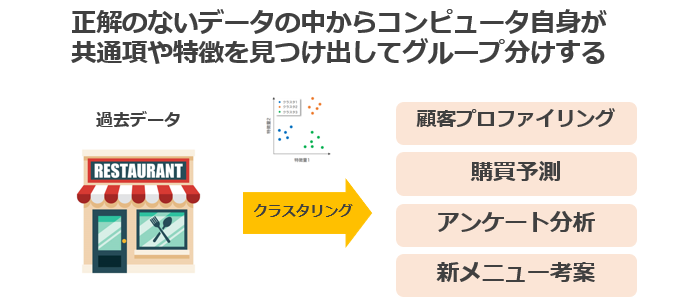
クラスタリング(clustering)
クラスタリングとは、正解データを与えずにコンピュータ自身がデータの中から共通項や特徴を見つけ出し、グループ分けをする ときに利用します。
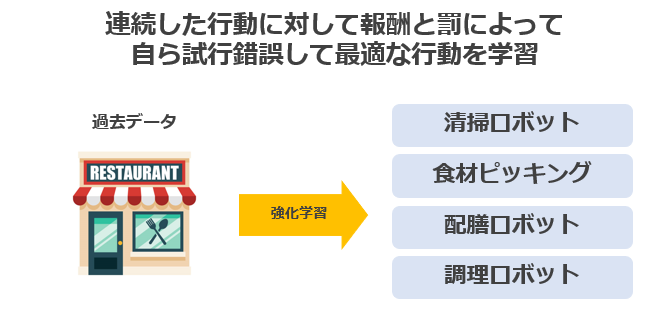
強化学習(Reinforcement Learning)
強化学習とは、連続した行動に対して、報酬と罰によって自ら試行錯誤して最適な行動を学習 するときに利用します。
機械学習モデルの評価
機械学習モデルとは、何かしらの入力内容に対して、それの評価を出力するもの を指します。評価するためにデータセットを使ってモデルを学習し、回答精度の向上を図ります。この学習済みモデルを未知のデータの予測や分類に活用します。
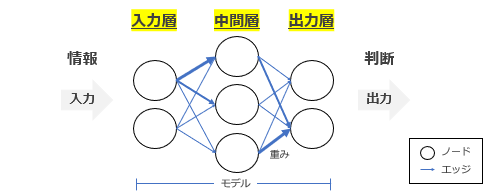
説明変数と目的変数
機械学習の基礎用語として、予測したい値を目的変数、予測するための値を説明変数と呼びます。
たとえば、機械学習をつかってレストランの売上予測を行う場合、「来月の売上」や「1か月以内に来店しそうな人」を予測する場合は、未来の値を予測するため目的変数です。来月の売上を目的変数とする場合、説明変数として考えられるものは、そのレストランのWEBページ閲覧数や、予約検討した数、過去の予約/キャンセル数、季節(天気や気温)等があります。このように、目的変数の値を予測するにあたり、特徴がありそうな値群を説明変数と言います。
機械学習は、説明変数を含むデータをもとに学習し、予測モデルを構築し、未知のデータに対しても目的変数を予想できるのです。
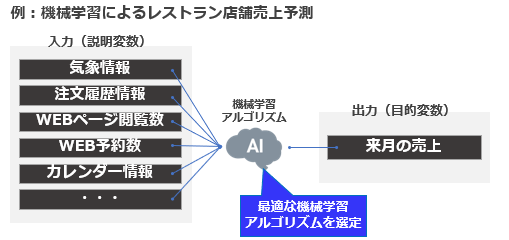
また、解決したい問題(目的変数)と利用できるデータ(説明変数)と機械学習アルゴリズムとの相性によって、目的変数の結果に影響がありますので、複数の機械学習アルゴリズムを使い分けることが必要になります。
機械学習に不向きなこと
機械学習は、データセットの量と質によって大きく結果が変わります。また、人間が判断できないものは、機械学習も評価できないです。
下記は機械学習に不向きなものです。

機械学習アルゴリズム
機械学習は、数多くのアルゴリズムが存在し、それぞれ異なる特徴を持っています。機械学習のアルゴリズムの選定は、AutoMLといったツール等で近年、自動化されつつありますが、どのようなアルゴリズムが使われているか、その構造まで理解しておくと、例えばAIプロジェクトで相手に説明するときに深みが出て説得力が増します。
先ほど説明した教師あり学習、教師なし学習に該当する主な機械学習アルゴリズムは下記のとおりです。
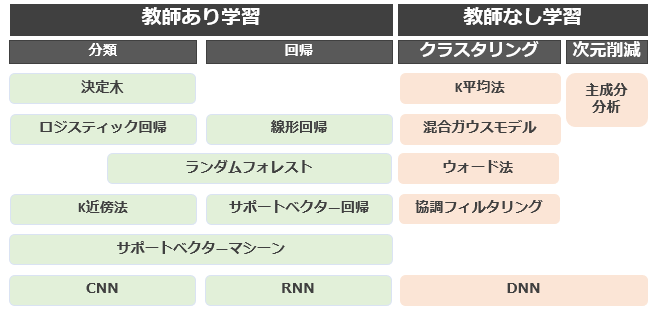
参考:G検定シラバス2021_修正版
機械学習アルゴリズムはチートマップが存在しますので、興味ある方は「機械学習アルゴリズム」と検索して確認してみてください。
主な機械学習アルゴリズム
機械学習アルゴリズムの代表例をいくつか紹介します。

法則性が存在しているデータセットを分類する教師あり学習はロジスティック回帰、正確性を重視した数値予測を行う際はランダムフォレスト、法則性が存在していないデータセットを分類する教師あり学習はサポートベクターマシン、確率を考慮しないで済む教師なし学習はk平均法などそれぞれのアルゴリズムには特徴があり、用途によって使い分けることが鍵となります。
ロジスティック回帰
ロジスティック回帰は、複数の変数から分析を行う「多変量解析」モデルの1つです。高精度な分析・予測が必要とされる場面で活用されています。
ランダムフォレスト
ランダムフォレストは、複数の決定木を生成し、各決定木の結果を集計して多数決または平均を取って予測する手法です。Webサイト上での行動履歴や、ユーザーの属性等を活用するなどのデジタルマーケティングの分野で活用されています。
サポートベクターマシン(SVM)
**サポートベクターマシン(SVM)**は、パターン識別時に用いられる教師ありモデルの1つです。テキスト分類や数字認識、ピクセル値を用いた顔検出の分野で活用されています。
K平均法
K平均法は、機械学習のクラスタリング手法の1つです。画像処理の際に処理速度向上・付加軽減が必要とされる場面で活用されています。
機械学習の主要アルゴリズムを事例から学べるレシピ紹介
ロジスティック回帰
01_営業の成約率を予測する機械学習モデルのレシピ
投稿者:@belltreeさん
銀行営業データセット(Bank Marketing Dataset)を学習し、ロジスティック回帰モデルを用いて、成約率が高い営業の傾向を予測します。
営業の際の成約率予測に活用できます。
02_Pythonによるコンジョイント分析で製品開発を検討するレシピ
投稿者:@小林 猛さん
アンケート結果を学習し、ロジスティック回帰を用いて、製品開発を検討するレシピです。
アンケートの結果などから消費者の製品・サービスに対する評価を集計し、その製品・サービスが有する属性が購買行動に与える影響を明らかにすることに活用できます。
03_RFM分析、分散分析、ロジスティック回帰分析による顧客管理レシピ
投稿者:@小林 猛さん
顧客の送品購買データを学習し、RFM分析、分散分析、ロジスティック回帰分析といった様々な統計分析手法を用いて、顧客シェアや顧客ロイヤルティの拡大の指標の改善に向けた数値データの分析を行うレシピです。
ミクロ視点でロイヤルティの高い顧客へ効果的なマーケティングを行う際に活用できます。
ランダムフォレスト
04_科学のニュース記事を分類するレシピ
投稿者:@su2umaruさん
scikit-learnに同梱されている20newsgroupsというニュース記事のデータセットを学習し、ランダムフォレストを用いて、性能を向上させるレシピです。
実務では、ニュース記事やレビューといったテキストデータを機械学習でテーマ別に自動分類するときに役立つ手法です。
05_機械学習の特徴量の重要度を表示・活用するレシピ
投稿者:@Jolibeeさん
沈没したタイタニック号への乗客者の生存状況データセットを学習し、ランダムフォレストを用いて、タイタニック号の乗客の生存を予測するレシピです。
機械学習 アルゴリズムの「ランダムフォレスト」において、特徴量の各要素がどの程度モデルの予測に寄与したか、その重要度を算出する際に活用できます。
06_GPUを使用せずに機械学習モデルで顔画像を分類するレシピ
投稿者:@su2umaruさん
scikit-learnに同封されているOlivetti faces datasetという顔画像のデータセットを学習し、ランダムフォレストを用いて、画像分類を行うレシピです。
PCで顔画像を自動分類する際に活用できます。
サポートベクターマシン(SVM)
07_SVMの精度向上のためにハイパーパラメータを探索するレシピ
投稿者:@su2umaruさん
Scikit-learnに同封されいているirisというアヤメのデータセットを学習し、SVMを用いて、精度を向上させるレシピです。
ハイパーパラメータを探索して同じデータセットに対して同じ分類器で精度を向上させる際に活用できます。
08_サポートベクトルマシンを用いた回帰分析の方法と実演レシピ
投稿者:@Jolibeeさん
ボストンの地価データを可視化、学習し、サポートベクトルマシン(SVM)、多次元回帰分析を用いた回帰モデルでどのような変数が地価データに影響するか傾向を予測します。
SVMを活用して関連するデータを見つけ出し、数値予測に活用できます。
09_生産ラインを想定した画像異常検知の実践レシピ
投稿者:@appleさん
手書きアルファベット文字の画像データを学習し、TensorFlowとKerasを用いて構築されたオートエンコーダ、畳み込みオートエンコーダ、サーポートベクトルマシン(SVM)モデルを用いて、異常検知分類を行うレシピです。
工場生産ラインでの画像を使った異常検知に活用できます。
k平均法
10_機械学習応用編~k平均法によるカラー画像圧縮法~のレシピ
投稿者:@pythonistaDさん
カラー画像を学習し、k平均法を用いて、カラー画像を圧縮するレシピです。
画像圧縮は、画面の処理速度の向上や負荷軽減に活用できます。
最後に
今回は、Axrossで学べる機械学習の主要アルゴリズムを事例から学べるレシピ をご紹介しました。
プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
Axrossのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。
