Axross Recipe運営メンバーの三井です。
今回は最近ホットな生成AIについて解説し、それらを用いたレシピについて紹介します。
生成AIとは
生成AIとは、最近ホットな画像、テキスト、動画、音楽を生成するAIのことを指します。
特に、2022年には新しい画像生成AI(MidJourney,DALL-E 2,Stable Diffusion)が次々と出てきており、画像生成分野において話題になっています。

※Stable Diffusionを使用し筆者作成
コンピューティングはこれまで下記のような進化をたどってきました。
「推論」はレコメンド機能、顔認証等、今日使用されてきています。
そして次のフェーズが「創造」であり、画像、テキスト、動画、音楽を生成することを指します。

生成AIの種類(画像、テキスト)
生成AIの手法の例をいくつかを紹介します。
Imagen(画像生成)
テキストから画像生成する手法は下記の通り移り変わっています。

Imagenは2022年5月にGoogleによって発表されたテキストから画像を生成するAIです。
手法としては、
- テキストを大規模な言語モデルで特徴量ベクトルに変換
- 特徴量ベクトルから、U-Net構造の拡散モデルを用いて64×64の画像を生成
- 超解像モデルで1024×1024まで高解像度化
の処理を行うネットワークとなります。
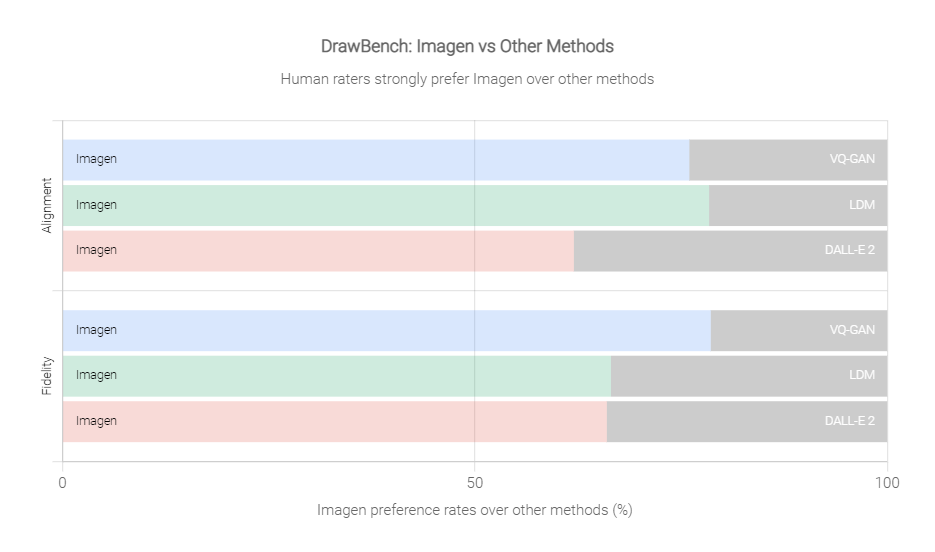
ImagenはDALL-E2、GLIDE、VQ-GAN+CLIP、Latent Diffusionなどの最新の手法より高い結果を出している最新の画像生成AIになります。
Imagenを用いると、以下のような画像をテキストから生成することができます。

現在Imagenは画像生成におけるAI倫理上の問題からオープンアクセスではありません。
画像出典:Imagen: Text-to-Image Diffusion Models
Stable Diffusion(画像生成)
Stable Diffusionは、2022年8月にStability.AIによって公開された画像生成モデルです。
特徴としては、Latent Diffusion Modelを用いており、5850億ものテキストと画像のペアを持つLAION-5Bデータセットでトレーニングされています。
その表現力の高さから、大きな話題となっており、以下のような画像を生成することが可能です。


出典:https://github.com/CompVis/stable-diffusion
GPT-3(テキスト生成AI)
2020年5月にOpenAIの論文「Language Models are Few-Short Learners」の中で、GPT-2の後継モデルとしてGPT-3が発表されました。
・超巨大なTransfomerベースのモデルを使用する。
・ラベルなしの大量のテキストデータをモデルに読み込ませて事前学習を行う。
・事前学習済みモデルを使うと、様々なタスクに対してFinetuningなしで対応できる。
GPT-3は、約45TBの大規模なテキストデータのコーパス(自然言語の文章を構造化し大規模に集積したもの)を、約1,750億個のパラメータを使用して学習しています。GPT-3の前のバージョンであるGPT-2の事前学習で使用されるテキストデータは40GBで、パラメータ数が15億個であることから、それぞれテキストデータは1,100倍以上、パラメータは約117倍以上となります。GPT-3の言語モデル精度が高い理由として、これまでにないほどの大量のデータセット、パラメータで事前学習しているかがわかると思います。

生成AIのレシピ34選
画像生成
01.Imagenを用いてテキストから画像生成するレシピ
2022年にGoogleが発表した、テキストから画像生成をするAI「Imagen」を実際にプログラムを動かしながら学ぶことができます。
02.CLIP+GANでテキストから画像を生成するレシピ
CLIP+GANで構成されるFuseDreamの技術概要を理解し、実際にテキストから画像を生成する方法を学ぶレシピです。
製品、建造物などデザインアートへの利用に活用することができます。
03.CLIP+GANでテキストから動画を生成するレシピ
CLIP+GANで構成されるFuseDreamの技術概要を解説し、テキストから動画を生成する方法を学ぶレシピです。
自然言語表現で指定した画像を生成し広告への活用に活用することができます。
04.Latent Diffusion Modelsを用いてテキストから画像を生成するレシピ
Latent Diffusion Modelsの技術概要を理解し、Huggingfaceのdiffusersライブラリを用いて、テキストから画像を生成する方法や、モデルが画像を生成する過程をアニメーションで可視化する方法を学ぶレシピです。
自然言語表現で指定した画像を生成し広告へ活用することができます。
05.GLIDEで様々な条件を指定したテキストから画像を生成するレシピ
GLIDEの技術概要を理解し、論文発表元が公開するミニモデルGLIDE(filterd)を用いて、テキストから画像を生成する方法や、テキストに応じた画像修復方法を学ぶレシピです。
自然言語表現で指定した画像を生成し広告へ活用することができます。
06.MODNetで動画の背景を合成するレシピ
MODNetの技術概要を理解し、動画から背景を削除しバーチャル背景を合成する方法を学びます。
背景合成によるコストを抑えたプロモーション動画作成に活用することができます。
07.Plenoxelsを用いて入力画像から自由視点画像を生成するレシピ
Plenoxelsの技術概要を理解し、テストデータセットから自由視点画像を生成する方法を学ぶレシピです。
自由視点画像を用いた全体俯瞰による周囲監視、遠隔移動操作ロボットインターフェースに活用することができます。
08.Pythonでモザイクアート画像を作成するレシピ
Pythonでモザイクアート画像を作成するレシピです。
このレシピでは一般的な画像データセットからモザイクアート画像を作成するものになっていますが、画像を差し替えることで自分の好きな画像でモザイクアート画像を作成することができます。
Python画像処理(リサイズ、配列のスライス、色補正)、モザイクアート画像の作成に活用することができます。
09.Python + CycleGANでオリジナルデータを学習し、白黒画像をカラー画像に変換する
Python + 画像変換技術の学習として、オリジナルデータにおけるCycleGANの学習と画像変換を学ぶレシピです。
白黒画像のカラー変換、実写から絵画への変換に活用することができます。
10.Kerasで学ぶ画像生成モデルDCGANレシピ
そのGANとは何かをまずは学び、その後にGANをベースに作られたDCGANモデルの構築を実践形式で行っていきます。
11.StyleGAN+CLIPモデルで、テキストによる顔画像の編集を行うレシピ
顔画像の編集を行うStyleGAN+CLIP モデルを実装し、ランドマークに合わせた顔画像の切り出し、編集したい画像を生成する潜在変数の推定、テキストによる潜在変数の編集の手法、様々な潜在変数の編集例を学ぶことができます。
StyleGANにCLIPモデルを組み合わせることで、編集したい内容をテキストで指示できる汎用性を持たせ、かつ高速処理が可能になります。実務では、顔画像の編集・分析を行う場面に活用できます。
12.StyleGANで本物と区別がつかない画像を生成するレシピ
StyleGANは、人の目ではもはや見分けがつかないレベルにまでリアルな画像を生成できると話題になった超高精度な画像生成ができる最新のGANモデルです。
公開されている学習済みのStyle GANとデータセットを用いて、本物と区別がつかない画像を生成する手法を、実際に動かし体験しながら学ぶことができるレシピです.
13.テキストから画像を生成するDALL-Eを実装するレシピ
DALL-Eの一部公開されているコードに、OpenAIのCLIPを組み合わせて、DALL-E全体を動かすコードをGoogle Colabで実装します。
製品や建築物、空間のデザイン、アートに活用することができます。
14.1枚の静止画を動画に合わせて動かすレシピ
1枚の静止画を動画に合わせて動かす「Motion Representations for Articulated Animation」についての概要を説明し、Google Colabで実装します。
動画編集に活用することができます。
15.Stable Diffusionを用いて画像生成・画像修復するレシピ
Stable Diffusionの技術概要を解説し、テキストから画像を生成するText to Image、画像とテキストから新たな画像を生成するImage to Image、画像の指定範囲をテキストで指示した画像で修復するInpaintingを行う方法を学びます。
製品、建造物などデザインアートへの利用に活用することができます。
16.DALL-E2を用いてテキストからリアルな画像を生成するレシピ
DALL-E2というテキストから画像生成をするAIを実際にプログラム動かしながら学びます。
イラストの制作やゲームの開発に活用することができます。
17.NAFNetで画像からノイズを除去するレシピ
NAFNetの技術概要を理解し、画像のノイズ除去を行う方法や、モデルのトレーニング方法を学びます。
撮影画像の手振れ、ノイズ除去による鮮明化に活用することができます。
18.日本語版Stable Diffusionを用いて画像・アニメーションを生成するレシピ
Stable Diffusionの技術概要を理解し、rinna社が公開した日本語に特化したStable Diffusionを用いてテキストから画像を生成する方法やアニメーションを生成する方法を学びます。
19.Unified-IOを用いてテキストから画像を生成するレシピ
Unified-IOを用いた画像生成について、実際にプログラムを動かしながら
テキストから画像を生成する仕組みと実装方法を学ぶことができます。
20.GFPGANを用いてより高解像度な画像を生成するレシピ
GFPGANの概要や、GFPGANを用いた顔画像の高解像度化、カラー化を行う方法を学べます。
Stable Diffusionで生成した画像の顔部分の復元などにも応用ができます。
21.形態素解析で記事のタイトルからサムネイル画像を自動生成するレシピ
タイトルの形態素解析をJanome、画像取得にPixabay APIをそれぞれ使ってタイトルからサムネイル画像を自動生成するプログラムを学びます。
記事コンテンツのサムネイル生成に活用することができます。
22.rinna社の日本語に特化した言語画像モデルCLIPを用いて日本語テキストから画像を生成するレシピ
本レシピでは、日本語に特化した言語画像モデル #CLIP を用いて日本語テキストから画像を生成する方法をご紹介します。
23.NVIDIAのInstant NeRFを用いて2D画像から3Dシーンを生成するレシピ
本レシピでは、Instant NeRFの技術概要を解説し、2次元画像から3Dシーン(自由視点画像)を生成する方法を学ぶことができます。
テキスト生成
24.GPT-3を使いプログラムコードを自動生成するレシピ
CODEX というGPT-3を元とするプログラム合成モデルを実行し、
コードを自動生成する方法を学ぶことができます。
プログラミング言語の変換やリファクタリングなどに活用できます。
25.LeakGANを使った文書生成のレシピ
GANによる文書生成技術の中でも性能が高いLeakGANを取り上げます。それでは、LeakGANのプログラムを動かして、最先端の文書生成技術を学ぶことができます。
チャットボット、AIアシスタントのシナリオ作成に活用することができます。
26.GitHubのcopilotで自然言語から関数を生成するレシピ
copilotの申請方法からVScodeへの導入方法、実際の関数コードの自動生成までを解説付きで学ぶことができます。
近年TransformerというPythonの自然言語処理系ライブラリが公開されたことで、それを基盤としたGPT-3をはじめとした文章生成言語モデルが多くの企業で公開されるようになりました。このライブラリはその膨大なモデルサイズから、チャットボットのような文脈に沿ったコミュニケーションが必要な機能においても既存のモデルにない性能を誇っていることで注目されています。実際にGPT-3のハイレベルな文章生成能力を体験してみましょう。
27.夏目漱石の「坊ちゃん」を学習させてマルコフ連鎖で新作を自動生成させるレシピ
マルコフ連鎖で文章生成をするPythonライブラリであるMarkovifyを使って、夏目漱石の「坊ちゃん」をデータセットとして**「坊ちゃんの新作」文章を生成**するプログラムを解説します。
Web上のテキストデータをデータセットとして使うためのクレンジング方法と、マルコフ連鎖による言語モデルの作成とそれによる文章生成方法について学ぶことができます。
28.GPT-3でタイトルや要約から記事本文を自動生成するレシピ
GPT-3の文章生成言語モデルのAPIを使い、タイトルや要約などの文章をデータとして与え、その記事の本文を自動生成させます。GPT-3による日本語の記事コンテンツの自動生成と長文の自動要約を行う手法を学ぶことができます。
GPT-3のような言語モデルによって、ブログやSNSの文章のコンテンツを自動で作成する未来もそう遠くはないでしょう。
29.ArtEmisでアートを説明するAIを開発するレシピ
絵画に説明文と感情を付与した大規模データセットであるArtEmisを使用して、画像キャプション生成について、実際のプログラムを確認しながら学ぶレシピです。
コンテンツへの画像キャプションの自動挿入に活用することができます。
30.GPT-3のNLPアプリケーション開発を体験してみるレシピ
言語モデル「GPT-3」について、実際にGPT3を用いたアプリケーションを作って理解を深めます。
文章生成機能や文書変換機能など、実験的なNLPアプリケーションや機能の開発に活用することができます。
31.GPT-3で自然対話するSlackボットを作るレシピ
OpenAIが開発した文章生成言語モデルであるGPT-3を使って自由に対話できるボットを作成し、Slackに導入する方法を学べます。
業務で使っているSlackグループに雑談ボットとして導入できます。
32.【GPT-3発展編】音声だけで会話するチャットボットを作るレシピ
文章入力を必要としないGPT-3会話ボットの作成を解説していきます。
pepperのようなロボット開発に応用できます。
33.PyTorchを活用し画像のキャプションを自動生成するレシピ
ディープラーニングを用いた画像のキャプション自動生成方法を、作りながら理解していきます。
WEBセミナーでの説明(営業/マーケティング)、プロモーション動画制作、教育で活用することができます。
音楽生成
34.深層学習モデルを活用し、画像から音楽を生成するレシピ
画像から音楽を生成するモデルを作成するレシピです。
動画のBGMを自動作成、視覚障害者の方へのイメージの伝達に活用することができます。
最後に
AxrossRecipe は、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、実際の業務に近いテーマで、動くものを作りながら学ぶことができます。
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/AxrossRecipe_SB

プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
AxrossRecipeのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。