はじめに
Axrossを運営している松田です。
Axross は、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いで、ソフトバンク社内起業制度にて立ち上げたサービスです。
現役エンジニアによる実践ノウハウが"レシピ"として教材化されており、実際の業務に近いテーマで、動くものを作りながら学ぶことができます。
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/Axross_SBiv

マルチモーダルAI
マルチモーダル情報処理とは
マルチモーダル情報処理(Multi-modal Information Processing)とは、画像や音声、テキストなどの複数のモーダルのデータをコンピュータで処理して予測や分類を行う技術のことで、機械学習の手法 ディープラーニング(深層学習)と組み合わせて利用されます。
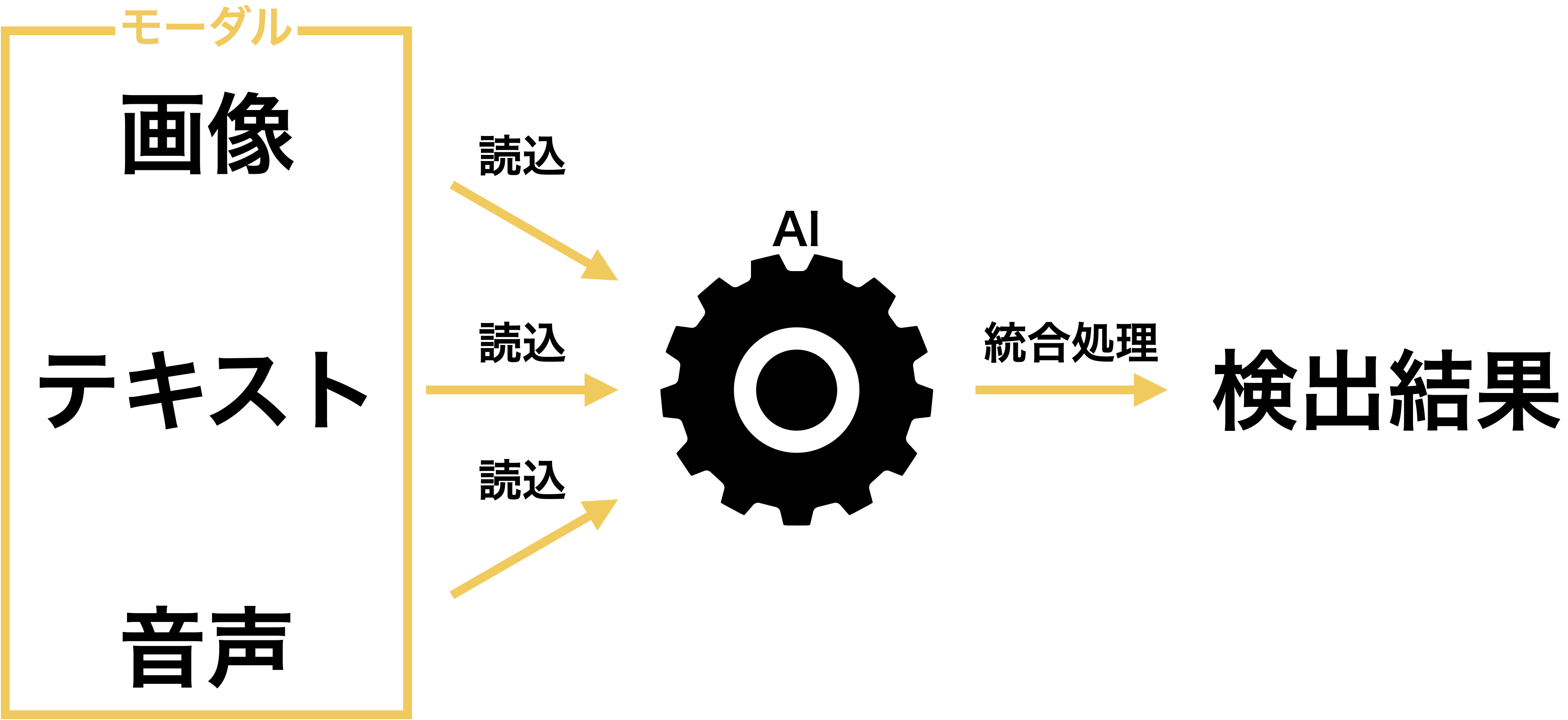
「モーダル」という言葉はAIへの入力情報の種類(映像、音、テキストなど)を意味し、「マルチモーダル」AIとは、様々な種類の入力情報を利用するAIのことを指します。
マルチモーダルAIの仕組み
AI(機械学習)の代表的な手法として、人の脳の仕組みを模したアルゴリズムのニューラルネットワークがあります。
ニューラルネットワークは、人と同じように経験や感覚、記憶、思考、感情、言語、匂い、音など、いわゆる五感で得られる様々な情報をインプットとし、過去の経験から学習することによって効果的な判断を行えるようになります。
農家によるりんご収穫を行う場面を例にすると、人は木になっているりんごをこれまでの経験情報に即して判断します。
人は、これまで経験したことがない、新たな品種のりんご(りんごに似た物体)が目の前に現れたとすると、その物体の色合いや形、大きさなどの様々な要素を組み合わせて判断します。また、視覚のみを用いるのではなく、匂いを嗅いだり、実際に触ってみてその肌触りや、半分に切ってみて硬さを確認し、そして軽く叩いてみてその音を聴き、食べてみることでりんごの味がするか確認するなど、その物体の情報をより細かく取得して、自分の目の前にあるりんごらしきものが、本当にりんごであるか推察することができます。さらに、他者にその考察結果を説明する際には、これらの複合的な情報を総合的に分析し、より高い精度の説明ができるようにします。
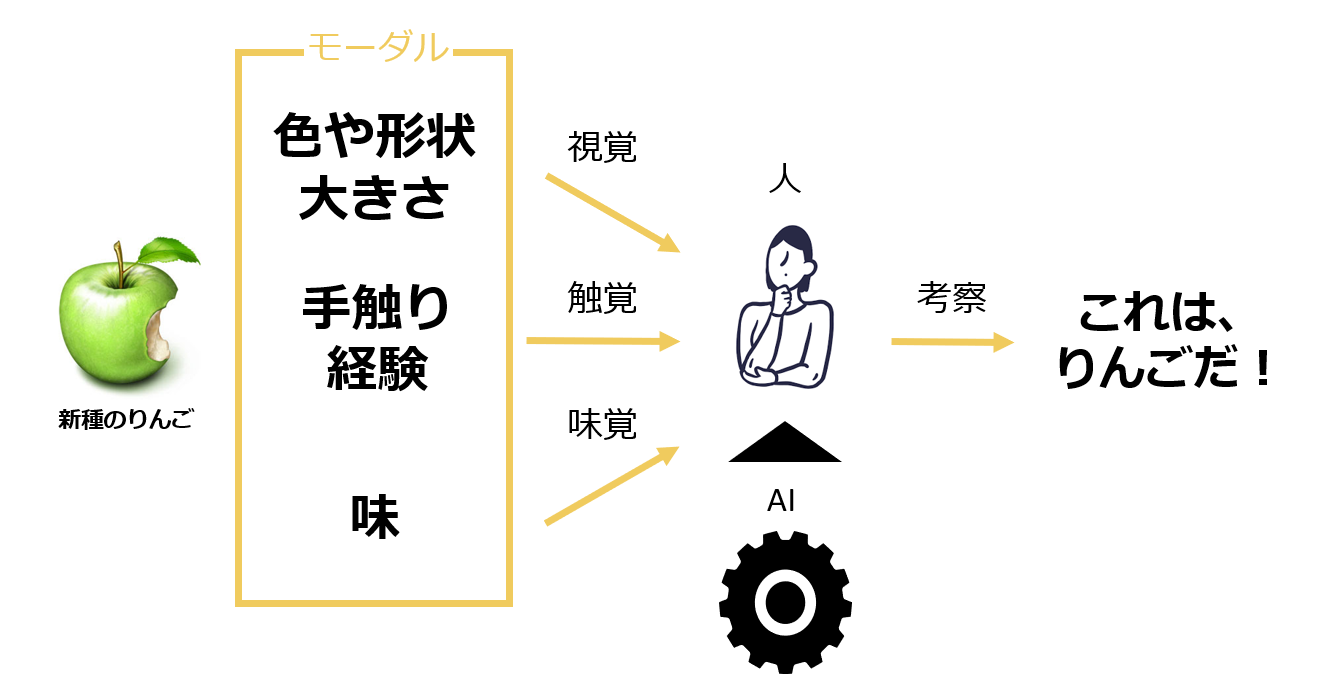
このように、人が物事を判断するときに行うような仕組みで、複合した情報の処理ができるAI・機械学習を実装することで、多様な情報を一元処理し、より精度の高いパフォーマンスを発揮するようになります。
マルチモーダル情報処理の活用例
マルチモーダル情報処理の活用例をいくつかご紹介します。
音声×画像
・工場作業での行動認識において、画像だけでは判別しにくい部分をセンシングデータと補完する
・ビルエントランスで人の行動を検出・記録し、迷惑行為に対してアラートを出す
・画像中の音の発生源を可視化する
・音楽(BGM)に見合った画像を生成する
・楽曲の曲調やムードに合わせて画像を生成し、分類する
画像×テキスト
・テキストと画像を用いた不正出品を検知する
・文字を用いて画像を生成・編集する
・画像を説明するテキスト(キャプション)を生成する
・店舗内顧客情報集計や解析する
・様々なデータを統合して、交通量解析や予測する
テキスト×音声
・文字を入力すると、それに関連する内容を音声で説明する
・リモート会議の内容が音声認識により文字起こしされ、要約された議事録が生成される
マルチモーダルAIのレシピ紹介
Axrossで学べるディープラーニングを活用したマルチモーダル処理を実装を通して学べるレシピ を7つご紹介します。
音声×画像
01_楽曲のムードを深層学習で分類するレシピ
投稿者:@belltree さん
楽曲100曲ずつムード別(happy,relax,sad,angry)に分類した音声データを学習し、音響的特徴量を使って深層学習(keras)で楽曲を分類する手法を学ぶことができます。
音の周波数と時間軸をグラフ化したスペクトログラムグラフを作成し、画像データとして可視化することで、画像分析モデルを作成・加工し、FineTurnigで学習モデル精度を向上させます。
SpotifyやApple Music等での楽曲自動再生で利用されている技術です。
02_深層学習モデルを活用し、画像から音楽を生成するレシピ
投稿者:@Hinata Aoki さん
クリエイティブなAIを体験するレシピとして、Encoder-Decoderによる画像分類と言語生成の深層学習モデルを用いて画像から音楽を生成するモデルを作成します。
まず画像を収集し、それぞれにBGMを割り振ります。そして、BGMのコード進行をテキスト化し、転移学習による画像分類とコード進行生成を行い、最後にChord2Melodyを使用して画像に合ったそれっぽい音楽を自動生成します。
画像×テキスト
03_PyTorchを活用し画像のキャプションを自動生成するレシピ
投稿者:@kanikani さん
画像キャプションとは、画像を入力すると、何がどんなふうに映っているか説明する文章のことです。PyTorchによるディープラーニングを用いて、画像キャプションを自動生成する方法を作りながら理解していくことができます。
Seq2Seqと呼ばれるEncoder-Decorderモデルを使って、CNNをEncoderに、LSTMをDecoderに設定してGoogle Colabo環境で作成します。
04_【発展編】深層学習を活用し、より高精度な画像のキャプションを自動生成するレシピ
投稿者:@kanikani さん
PyTorchを活用し、画像の特徴量をtransformerに入力させて、encoder-decoder間でattentionを利用して、重要と思われる単語を選択し、Beam Searchと呼ばれる、シーケンス内の各単語がそれを後続する単語を選択する手法を適用します。
前回の画像キャプション自動生成レシピ(Pytorchのlstmを利用したseq2seqモデル)よりも高精度なモデル作成手法を学ぶことができます。
05_StyleGAN+CLIPモデルで、テキストによる顔画像の編集を行うレシピ
投稿者:@jun40vnさん
このレシピでは、顔画像の編集を行うStyleGAN+CLIPモデルを実装し、ランドマークに合わせた顔画像の切り出し、編集したい画像を生成する潜在変数の推定、テキストによる潜在変数の編集の手法、様々な潜在変数の編集例を学ぶことができます。
テキスト×音声
06_【GPT-3発展編】音声だけで会話するチャットボットを作るレシピ
投稿者:@ベナオさん
GPT-3の文章生成言語モデルの発展編として、文章入力を介さず音声のみで会話するボットの作成を解説していきます。
Pythonには音源を文字に変換したり、その逆に文字を音源に変換したりとするライブラリがライブラリが用意しており、GPT-3と組み合わせることで、Pepperのように口頭で会話できるボットを作成できます。これまでのレシピで使ってきた技術が多く出てくるので、そう復習としてもおすすめです。
07_Zoom会議の録音データから音声認識で議事録を自動生成するレシピ
投稿者:@ベナオさん
PCマイクから録音(Pyaudio)や、文字起こし(Watson API)等Pythonのライブラリを用いて、ZOOM会議の録音履歴データを自動でテキスト化する音声処理(Speech to Text)の手法を学ぶことができます。
Watson APIは、機械学習の機能が揃うライブラリで、音源ファイルを処理する機能も豊富に用意され、簡単に扱えます。Watsonの機械学習とPythonを活用して、普段の会議の議事録やメモ作成の業務を自動化を試してみよう!
最後に
プログラミングは「習うより慣れろ、繰り返し演習すること」が重要です。
Axrossのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。