はじめに
Axrossを運営している藤原です。
Axross とは、エンジニアの"教育"と"実務"のギャップに着目し、「学んだが活用できない人を減らしたい」という想いのもと、ソフトバンクの社内起業制度にて立ち上げたサービスです。
現役エンジニアによる開発ノウハウや事例を"レシピ"として教材化し、実際にプログラミングで実装を追体験しながら学ぶことができます。AI/機械学習をテーマにした、様々な業務領域に応用できる専門的な学習教材を140以上揃えています。(2021年6月時点)
Axross:https://axross-recipe.com
公式Twitter:https://twitter.com/Axross_SBiv

今回は、AIによる画像認識の仕組みとその代表的な手法を紹介し、Axrossのサービスで無料で学べる、AIを活用したおすすめの画像認識レシピをご紹介します。
画像認識とは
画像認識は、画像から「何が映っているか」を認識できる技術です。
コンピュータは、画像をピクセル(画素)の集まりによって認識します。コンピュータは、事前に組み込まれた演算処理を通して、ピクセルのパターンから色や形などの特徴を抽出し、その類似の範囲や差異を学習させることで、画像に映ったものは何かを認識し、識別、分類などの処理を行えるようになります。
2012年、トロント大学のチームがILSVRCという大規模な画像認識コンテストにて、ディープラーニングを用いて画像認識のエラー率を大幅に改善し、圧勝したことがきっかけになり、ディープラーニングを活用した画像認識技術が飛躍しました。ディープラーニング手法により、構造が定義されていない、文章や画像、動画などの「非構造化データ」の処理が可能になり、2015年には人間の眼以上の画像認識能力を発揮できるまで精度が格段に向上しました。従来は人の眼によって判断していた数多くのタスクが、AIで自動化できるようになり、製造業や医療、小売、セキュリティ等の幅広い分野で活用され、画期的なイノベーションを起こしています。
画像認識の活用例
AIによる画像認識技術は、様々な場面で活用ができます。
画像に映ったものをどのように認識するか、といった仕組みも踏まえて活用例をご紹介します。
文字抽出(OCR)
レシートや名刺などの画像から文字を認識するために利用されます。
画像から文字を認識するためには、画像内の前処理が重要です。画像にはAIが認識する上で邪魔になる要素(ノイズや背景)が多く含まれており、特に光の反射や影、傾きは画像から文字を検出する上で厄介です。画像認識の精度を上げるために、そのような要素を事前に取り除く処理が必要です。
前処理ができたら、AIに「文字らしい」部分の特徴を抽出させます。そして、予想される文字情報の特徴と照らし合わせます。画像の特徴が文字情報の特徴と一致すれば、その文字として認識され、出力されます。一致しない場合は、別の文字候補から適切な文字を予測し、照合を行います。あるいはどの文字にも一致しなければ文字として認識しない、というように処理を繰り返し、文字を認識していきます。
異常検知
画像認識は、異常検知の分野でも活用できます。
画像認識における異常検知は、画像の他のデータパターンや標準的なパターンと異なる挙動のものを識別する技術です。AIに大量のデータを読み込ませ、データ間の共通点や相違点などを深層学習によって比較分析し、パターンを学習させることで、例えば、医療画像から異常を予測したり、工場の生産ラインで設備の故障や不良品を検知したり、エラーが出る可能性のあるものを予測したりできます。
画像分類
入力した画像情報を「形」や「模様」、「色」など特徴量に分解し、入力情報から対象物を判定できるように対応付けを行うことで、AIによる画像分類ができます。例えば、「きゅうり」の画像を判定する画像認識の場合、画像に写る対象を「緑(色)」、「凹凸ある(模様)」、「細長い(形)」といった複数の情報に分割して、事前に作成した「きゅうり」モデルの情報と結びつけて比較を行うことで判別し、画像分類を行います。
ECサイトの商品画像の分類や、野菜やパンの種類別に画像で仕分け、動植物の画像分類 等で画像分類が活用できます。
物体検出
画像認識の応用として、画像に写る物体の種類と位置、個体数などを予測し、画像のどこに何が写っているかをAIで推定することができます。
自動運転の際にカメラの映像で人や山や車などを見分けるときには、画像領域をピクセルごとにカテゴリ識別するセグメンテーション技術が使われています。
物体検出の活用例詳細は「AI物体検出を活用したレシピ紹介」をご参照ください。
顔認識
人の顔を認識するために利用されます。
人の顔画像を認識する場合、画像の中にあるピクセルの色や組み合わせから、目や鼻、口などを認識し、人の顔を構成するピクセルのパターンを大量に学習させる必要があります。AIに人の顔の特徴を覚えさせ、画像の中から顔を認識できるようになっていきます。
顔画像認識の活用例詳細は「顔認識AIを活用したレシピ紹介」をご参照ください。
画像認識の代表的な手法
CNN(Convolutional Neural Network)
AIを活用した画像認識の領域で、畳み込みニューラルネットワーク(CNN) は有名な手法の1つです。
CNNは、従来までの点による特徴抽出ではなく、畳み込み演算とプーリング+活性化関数を活用した画像の特徴の強調を繰り返すことで、画像の部分的な特徴と全体的な特徴を学習していき、画像の特徴量の学習を最適化していきます。1989年に、CNNの原型であるLeNetが、画像のアルファベット文字認識において成功をおさめて提唱されたのが始まりです。
5階層からなるLeNet-5のモデル構成
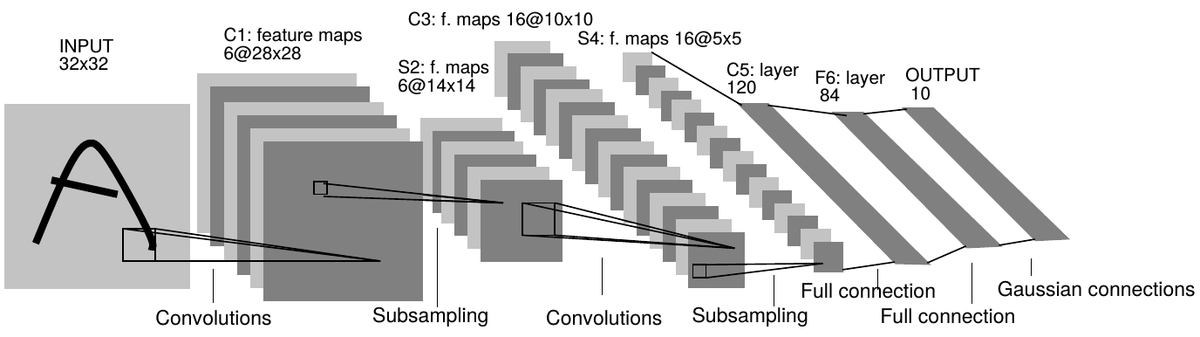
出典:Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
ResNet
ResNetは、2015年にMicrosoft Research(現Facebook AI Research)がCNNを発展させて考案したニューラルネットワークのモデルで、当時、画像認識精度を競うImageNetで優勝した、画像認識のアルゴリズムです。AIの画像認識精度が人間のエラー率を超越したことで話題になりました。
ResNetの特徴として、層が非常に深いことがあります。2014年に優勝したモデルは22層で形成されていたのに対し、2015年に優勝したResNetは152層です。実際、モデルの層が深いほど、画像認識の予測精度が高くなる傾向にありますが、その分モデルを学習させる時間が膨大になり、学習環境を整える必要があるのがResNetの弱みです。
ResNetのネットワーク構造
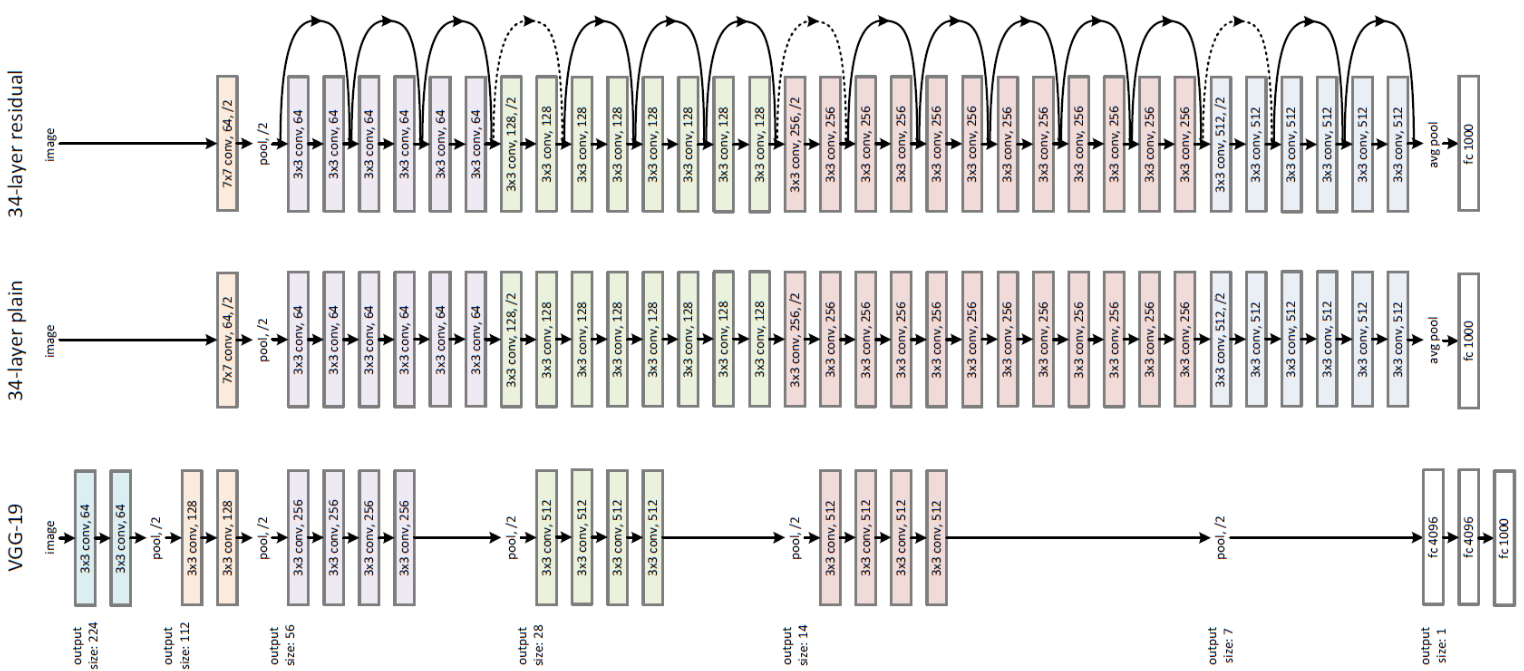
出典:Review: ResNet — Winner of ILSVRC 2015 (Image Classification, Localization, Detection)
VGG16
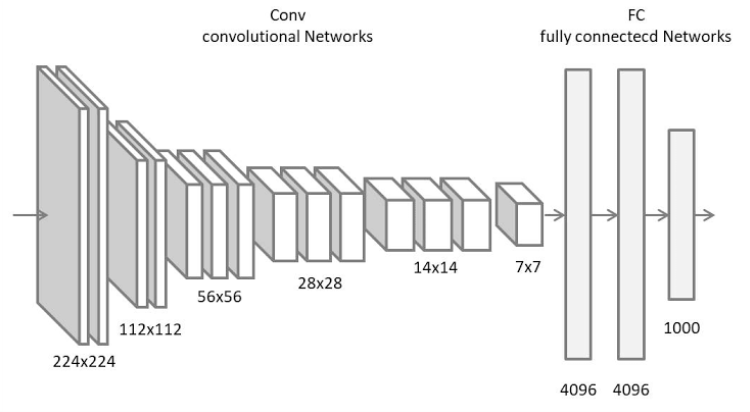
VGG16 は、2014年にOxford大学の研究グループが提案した、ImageNet と呼ばれる大規模画像データセットで学習されたCNNモデルです。VGG16は、深さ16層から成り立っており、入力画像を1000のクラスに分類することができます。
畳み込み層と全結合層を連結しシンプルに層を増やしたネットワーク構造で、使い勝手がよく、その後の研究でもこの構造をベースにして層を増やした研究が行われました。
VGG16のネットワーク構造
Efficient Net
Efficient Netは、2019年5月にGoogle Brainから発表された最強の画像認識モデルで、従来よりかなり少ないパラメータ数で、モデルの「層の深さ」と「層の幅」と「入力画像サイズ」の3つをバランスよい値を提案することで、高い精度を実現できます。転移学習にも最適で高性能であることから、近年Kaggleのコンペ等でも多用されています。
EfficientNetの理論解説とPyTorchでモデルを実装し、CIFAR-10で動かしてモデルの性能評価を行う PyTorchによる画像認識最強モデル「EfficientNet」実装レシピ もありますので、ぜひ活用してみてください。
投稿者:@omiita_atiimoさん
AIを活用したおすすめ画像認識レシピの紹介
Axrossでは、様々な動画や画像のデータセットを用いて、AIを活用した画像認識を実践するためのレシピを公開しています。その中で、受講者から人気なものを一部ご紹介します。
Synthetic Dataを用いて画像から文字を検出するモデルを実装するレシピ
投稿者:@SBtoukouさん
CVPR2019で発表された文字検出モデルの一つ、CRAFTについて解説し、Synthetic Data(人工的に作成した疑似データ)の画像処理ライブラリを用いて、文字検出モデルを学習、推論まで行う仮定を実装します。 最後に、学習したモデルを用いて、実データから文字を検出し、文字領域の予測を行います。
CRAFTは、RegionスコアとAffinityスコアの2つを予測することで、文字形状の傾きや変形・湾曲があっても、文字列の検出が可能です。
YOLOv5 と転移学習を使ってマスクの着用者と非着用者の顔検出を行うレシピ
投稿者:@lulu1351 さん
コンピュータービジョンの「物体検知」の王道とも言えるYOLO (You Look Only Once) シリーズの新モデルYOLOv5を活用し、近年需要が高い、マスクの着用者と未着用者の顔検出を行うタスクを実践します。
自分のデータセットでトレーニング(転移学習)を行い、Google Colabratoryを使って、YOLOv5を動かし、TensorBoardツールを使って学習結果の可視化することができるようになります。
画像認識による乗り物を分類するレシピ(モデル作成編)
投稿者:uehara7 さん
外部APIを用いてWEBサービスからデータを収集し、データの前処理、VGG16モデルの構築・評価まで、機械学習(AI)を活用して画像に映る物体を認識して画像分類する、一連のAI開発手法を学ぶことができます。
また、続編の**乗り物画像分類モデルの精度向上レシピ(転移学習編)**では、転移学習によって、画像分類モデルの精度を向上させる手法を学ぶことができます。
【CNNもAttentionも使わないMLP-Mixerを用いて任意の画像を1000クラス分類するレシピ
投稿者:@su2umaruさん
画像処理分野で、CNNをベースとしたモデルやAttentionをベースとしたモデルがよく使われる一方で、近年注目を集めているのがCNNもAttentionも使わない、MLPをベースとしたモデルMLP-Mixerです。
MLP-Mixerは、CNNやAttentionの画像処理モデルと比べて、学習時間が短いにもかかわらず、同等レベルの高い精度を実現できます。このレシピは、MLP-MixerのImageNetによる学習済みモデルを活用した任意の画像の1000クラス分類の実装を学ぶことができます。
【PyTorch】精度爆上げのオレオレベストプラクティスを10個まとめてみた!
投稿者:@omiita_atiimoさん
画像分類タスクでさらなるモデル精度向上を実現するためのベストプラクティス10個をまとめています。データセットはCIFAR-10を用いており、実際に手を動かしながら学べます。
バッチノームやL2正則化、ドロップアウトなど、もはや当たり前となっているものではなく、「データ水増し手法」、「アーキテクチャ」、「ラベル」、「オプティマイザー」、「学習率」などの点から、実際の経験に基づいて面白いと思ったものをそれぞれ説明・実装し、使い方を紹介しています。
最後に
今回は、Axrossサービスで学べる、AIを活用した人気画像認識レシピをご紹介しました。
AIを活用できる人材になるためのコツは、様々なテーマで実際にAIを実装する体験を繰り返すことだと思います。いろんなデータセットを用いて、AIの画像認識モデル実装を繰り返し演習しましょう!
Axrossのレシピを通して、プログラムの意味を考えながら写経(コードを実際に書き写す行為)し、実際に動くものをつくりながら学ぶことで、新たな知識の習得やスキルアップの一助になれれば幸いです。
