はじめに
よくRPA開発者の皆さんから、このような質問が聞かれました。
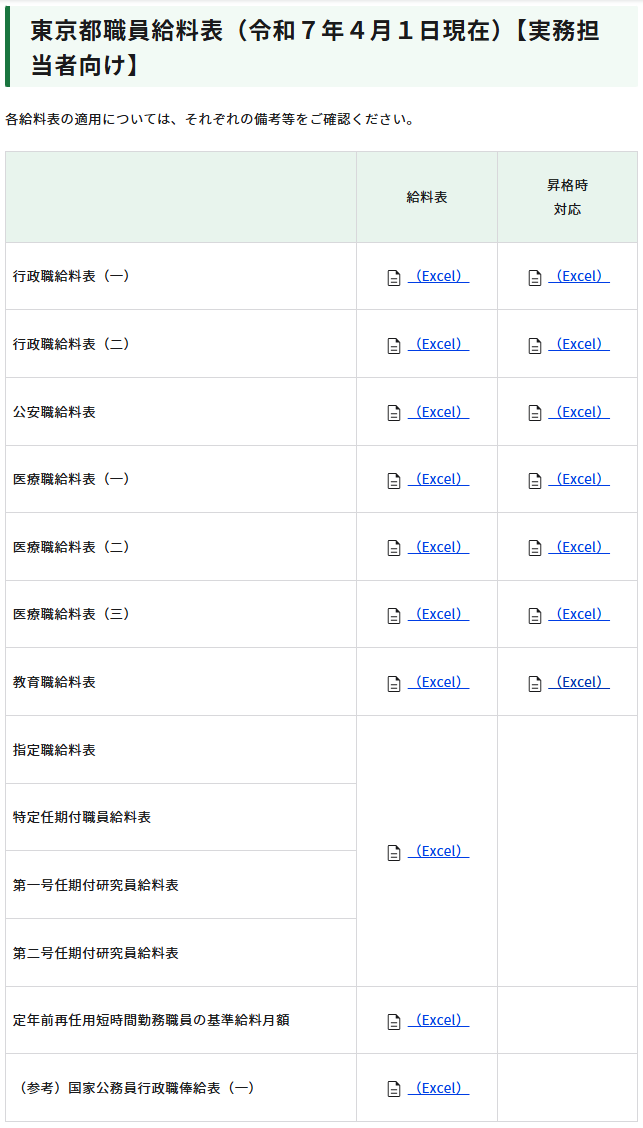
以下の表の「昇格時対応」の列で、各行のExcelをクリックしてダウンロードしたいですが、方法がわかりません。
今回は、ネットで今日公表された東京都職員給料表を例にし、ダウンロードの方法をご説明します。
実装環境について
| 項目 | バージョン |
|---|---|
| Studio | 24.10.16 |
| UiPath.UIAutomation.Activities | 24.10.13 |
| Chrome | 140.0.7339.128 |
以上は筆者の環境情報ですが、モダンアクティビティを利用するため、Studio 21.10及びUIAutomationパッケージ 20.10の環境さえあれば、開発できます。
実装ロジックの説明
まず、ロジックのまとめを説明してから、詳細な解釈をさせてください。
ロジックは以下の通りです。
①「表抽出」で「東京都職員給料表」を取得し、データテーブルとして保存します。※この段階で、表のURLが抽出できれば、より簡単なダウンロード方法がありますので、「終わりに」を参考にしていただければ幸いです。
②「繰り返し(データテーブルの各行)」で「東京都職員給料表」をループし、行Indexを取得します。
③「クリック」を「繰り返し(データテーブルの各行)」の中に配置し、厳密セレクターで「昇格時対応」のtableRow属性を取得します。
④行Indexと厳密セレクターのtableRowの差を計算します。
⑤tableRowの値を保存する変数を作成し、変数=行Index+差値で代入します。
⑥変数をセレクターのtableRowの値に代入します。
※「昇格時対応」の列に、Excelが存在しない行もあるため、それは「条件分岐(IF)」で除く必要があります。
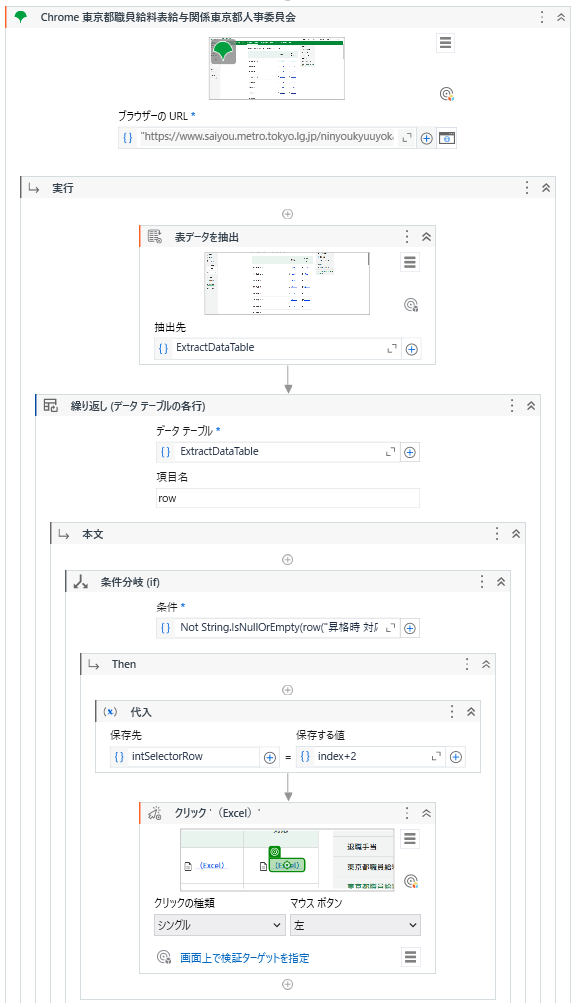
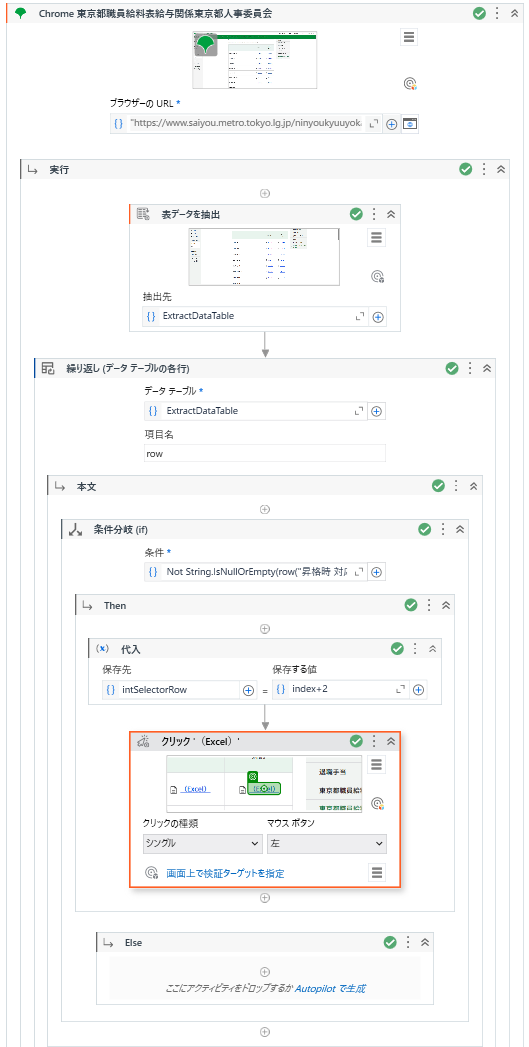
以下は、完成したワークフローのイメージです。
次に、ロジックのまとめで触れた概念を解釈いたします。
東京都職員給料表は、開くたびに更新され、A列(行政職給料表一など)の値が変わり、行も増減してあらかじめ行数がわからないものとします。「昇格時対応」の列における各行の値は、すべてExcelをなっているため、セレクターを取ると、重複な要素が複数検出されてうまくいかないのです。A列が変わらないとしたら、まだアンカーを利用して「昇格時対応」の各「Excel」を特定できますが、A列も常に変化する場合は、アンカーの利用もできないのですね。
「昇格時対応」のExcelをすべてダウンロードするために、どいった条件が必要なのかを考えましょう。
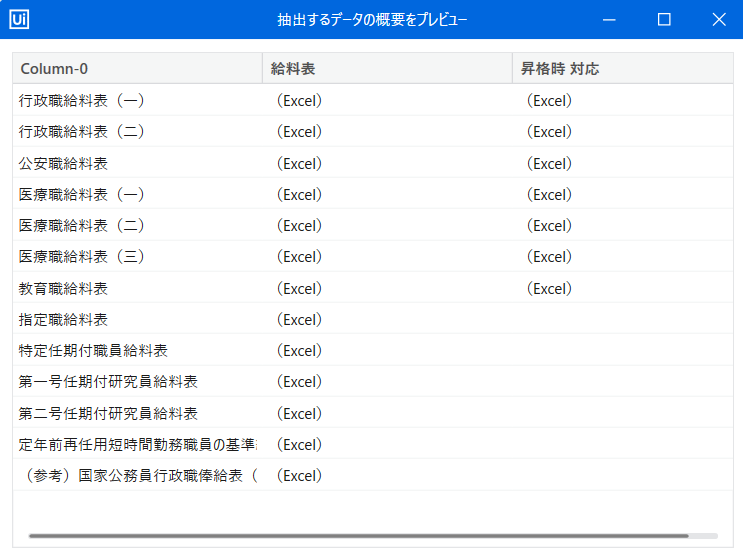
まず、表の行数がわからないと、ロボへどこまでダウンロードするかを指示できないため、どうしても行数を把握しなければなりません。行数の計算に、表の取得が前提となります。UiPath Studioは「表抽出」という機能を提供しているので、このツールを利用すれば、簡単にウェブサイトの表をスクレイピングすることができます。ただし、表の内容を抽出したとしても、取得したデータテーブル形式の「東京都職員給料表」に対し、ExcelのリンクをクリックするUI操作ができないので※、単に表抽出だけでは目標が実現できません。やはり、ウェブサイト上の「昇格時対応」列における各ExcelリンクをクリックするUI操作が必要ですね。
※以下は抽出結果です。Excelはただのペインテキストとなってしまい、クリックできなくなります。
では次に、UI操作の方法を考えましょう。アンカーが使えないため、各行のExcelを特定する属性を探すのは必要不可欠です。UiPathは、セレクターの取得で複数のターゲットメソッド(詳細は、UiPathの公式ドキュメントを参考にしてください)を提供しております。皆さんは普段、Studioの既存設定として、aanameやinnertextといった属性を使う「曖昧セレクター」を多用していますが、実は、あまり要素のテキスト情報に関心を持っていない厳密セレクターがより簡潔な属性で要素を特定できます。特に、ウェブサイト上の表形式の要素に対し、表の内容に依存せず、行と列のインデックス座標で、要素の位置を特定するため、非常にシンプルで頼りになるメソッドです。
以下は曖昧セレクターの画面です。aanameはすべて(Excel)となったため、画面上重複な要素がたくさん検出されました。
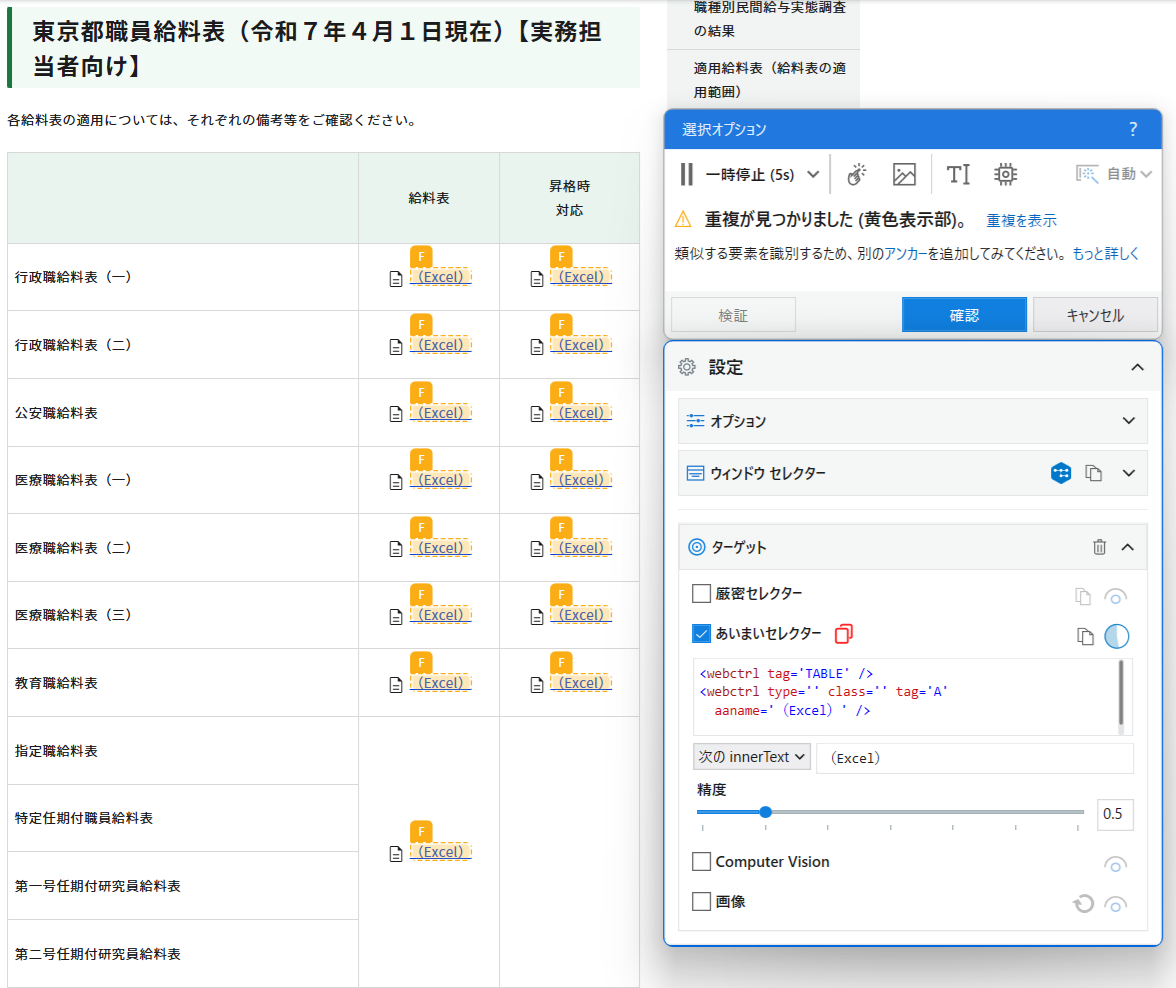
一方で、厳密セレクターの画面を見てみましょう。指定したExcelは、表の3列目(tebleCol='3')、そして表の2行目(tableRow='2')で特定されているので、表の内容がわからなくても、位置を特定することができます。
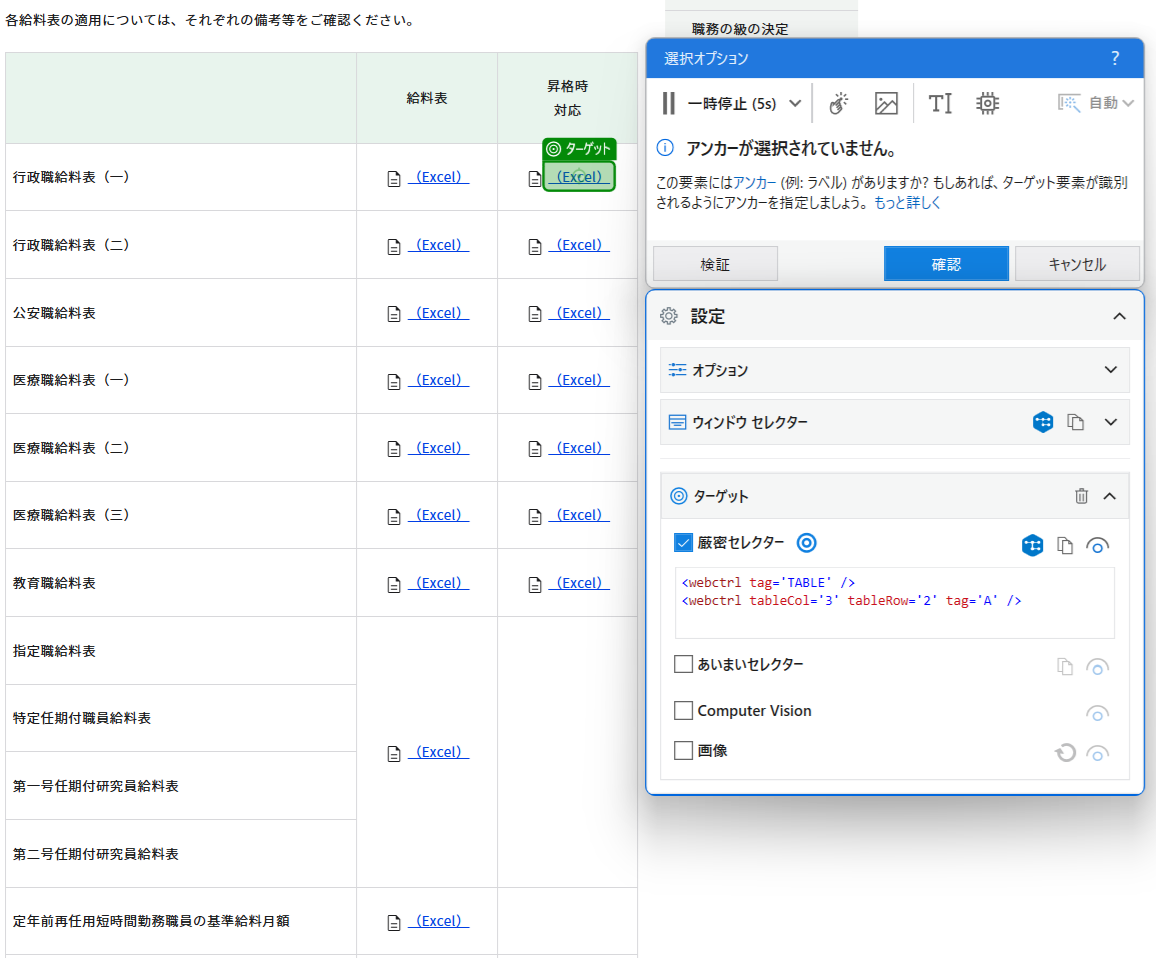
以上で、表の抽出で行数もわかりましたし、厳密セレクターでExcelの座標も取得できたため、取得のデータテーブルをループして、Excelの座標を「クリック」アクティビティの厳密セレクターに渡せば、ロボは、表の一行ずつを繰り返し、「昇格時対応」のExcelをダウンロードしてくれると思います。
実装開始
①デザインリボンバーの「表抽出」をクリックします。

要素選択画面が出たら、表データ本文の1列目の1行目を選択してください。ヘッダーを選択しないようにご注意ください。
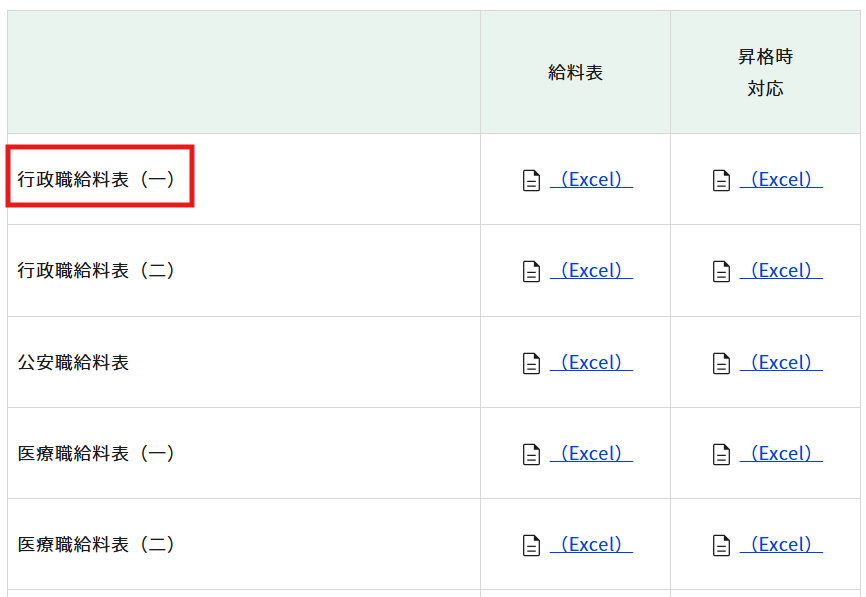
プレビューを押し、内容に間違いない場合、OKして抽出結果は自動的にExtractDataTableという変数に保存されます。
②繰り返し(データテーブルの各行)を配置し、ループ対象はExtractDataTableにします。なお、行Indexを取得したいので、プロパティパネルの「現在のインデックス」でindexというInt32型の変数を作成します。
③条件分岐を入れます。上記抽出結果のプレビューで、「昇格時対応」の列に空白行があり、そこにダウンロードリンクがないため、空白の場合はその行を飛ばす必要がありますね。下記式を「条件」に入力します。
Not String.IsNullOrEmpty(row("昇格時 対応").ToString)
④Thenの中でクリックを配置し、「昇格時対応」の1行目を指定します。厳密セレクターのTableRowの値をメモします。
indexは0から始まり、操作中の行は何行目なのかを示す値です。繰り返しでヘッダーを除いた1行目を操作する際、indexは0、2行目に入ったら、indexは1になります…一方で、Excelリンクは、1行目で厳密セレクターのtableRowは2で、2行目に入ったら、tableRowは3となります…つまり、indexとtableRowの差値は2です。そのため、Index+2を変数に代入して、その変数を厳密セレクターのtableRowに渡したら、操作中の行のExcelリンクがクリックされます。
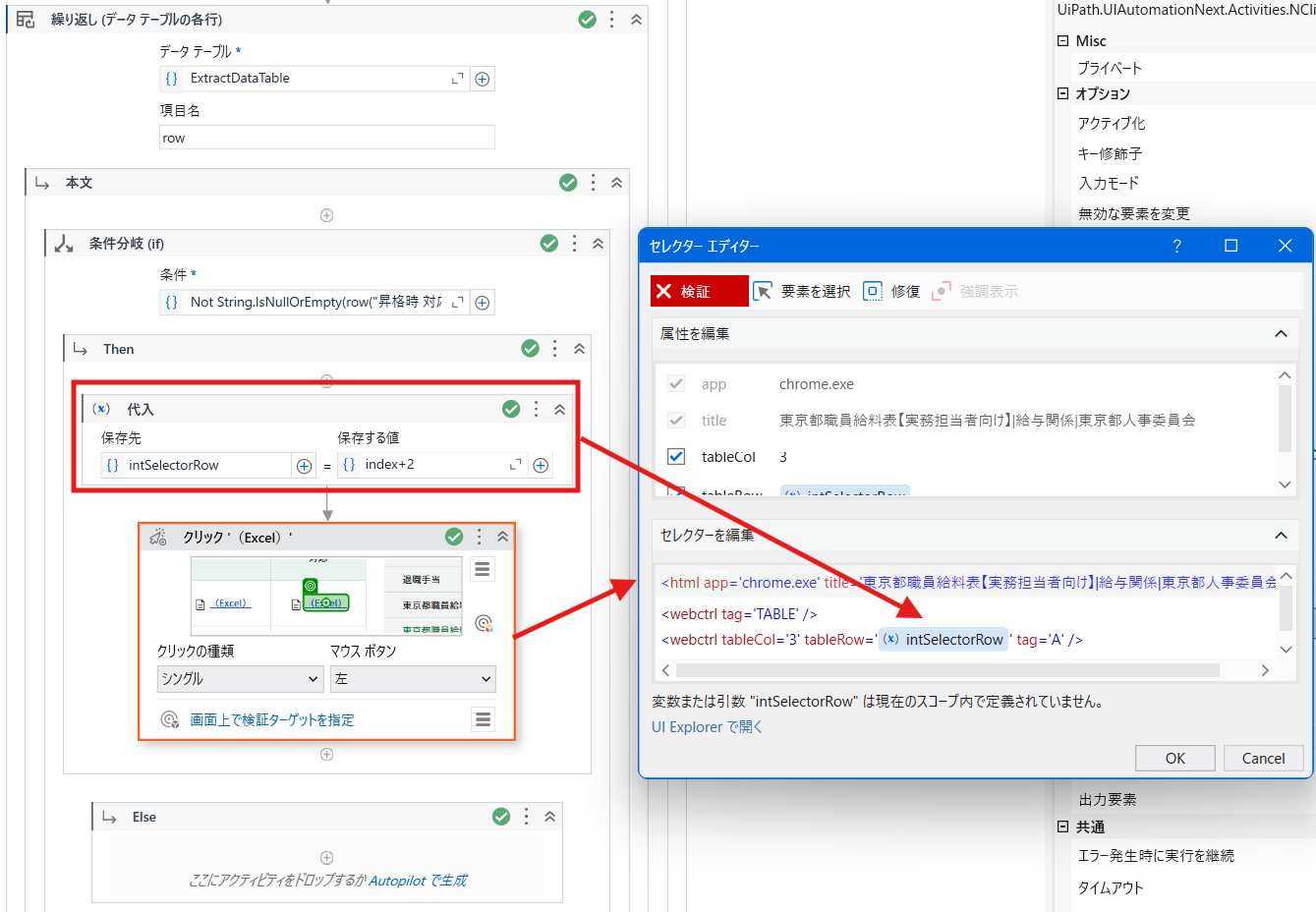
※変数をセレクターに渡す方法は以下となります。
tableRow='{{intSelectorRow}}'
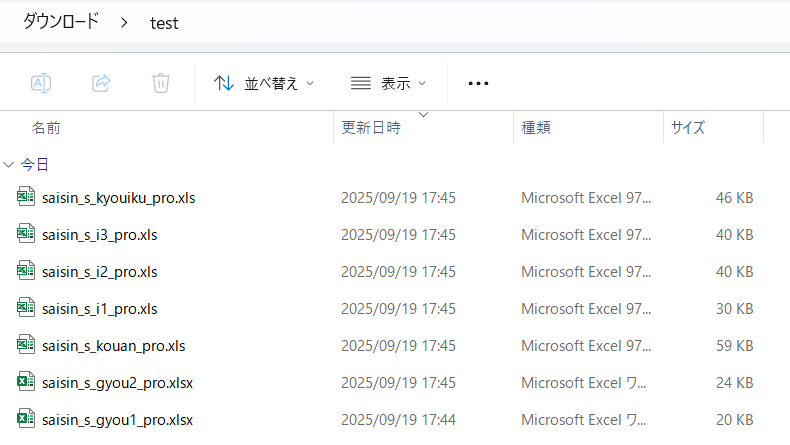
今回はChromeで「ダウンロード前に各ファイルの保存場所を確認する」をオフにしているため、クリックだけでExcelはダウンロードされます。
再度、実装完了後のワークフローの画面を共有します。
以下は実行結果です。
終わりに
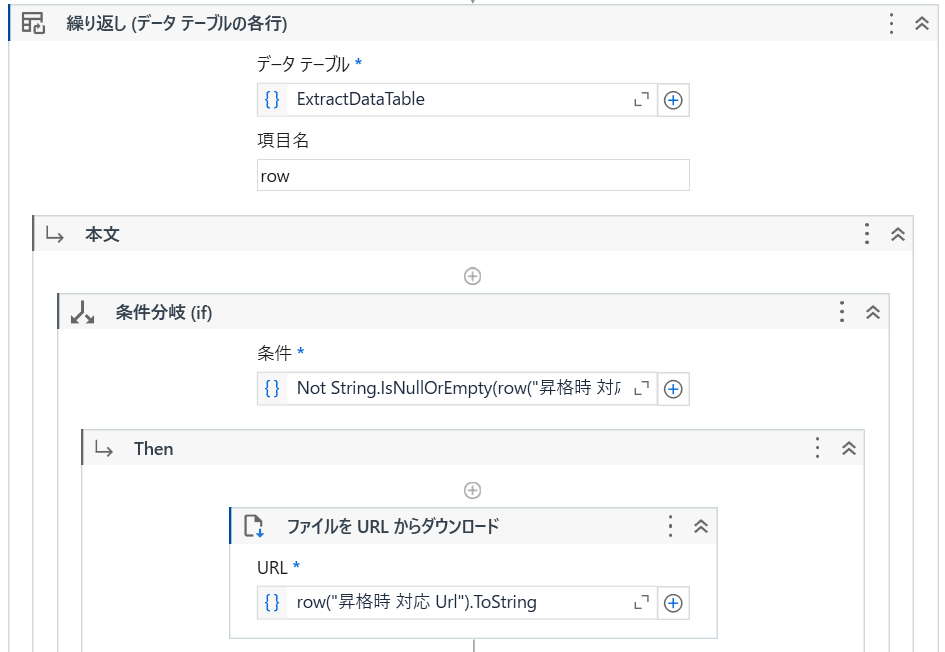
表抽出と厳密セレクターの組み合わせでウェブサイト上の表に入ったファイルをダウンロードする方法は以上となります。なお、「表抽出」の時に、ExcelのURLが取得できることもあります。それがあれば超ラッキーですね。何も複雑な実装などは要らなくて、URL列の値を「ファイルをURLからダウンロード」アクティビティに入れるだけでファイルがプロジェクトフォルダにダウンロードされますよ。
実は、今回表抽出で「昇格時対応」のURLを抽出できました。抽出できない場合は結構多く、上記の方法を案内するために、その列を削除しました。
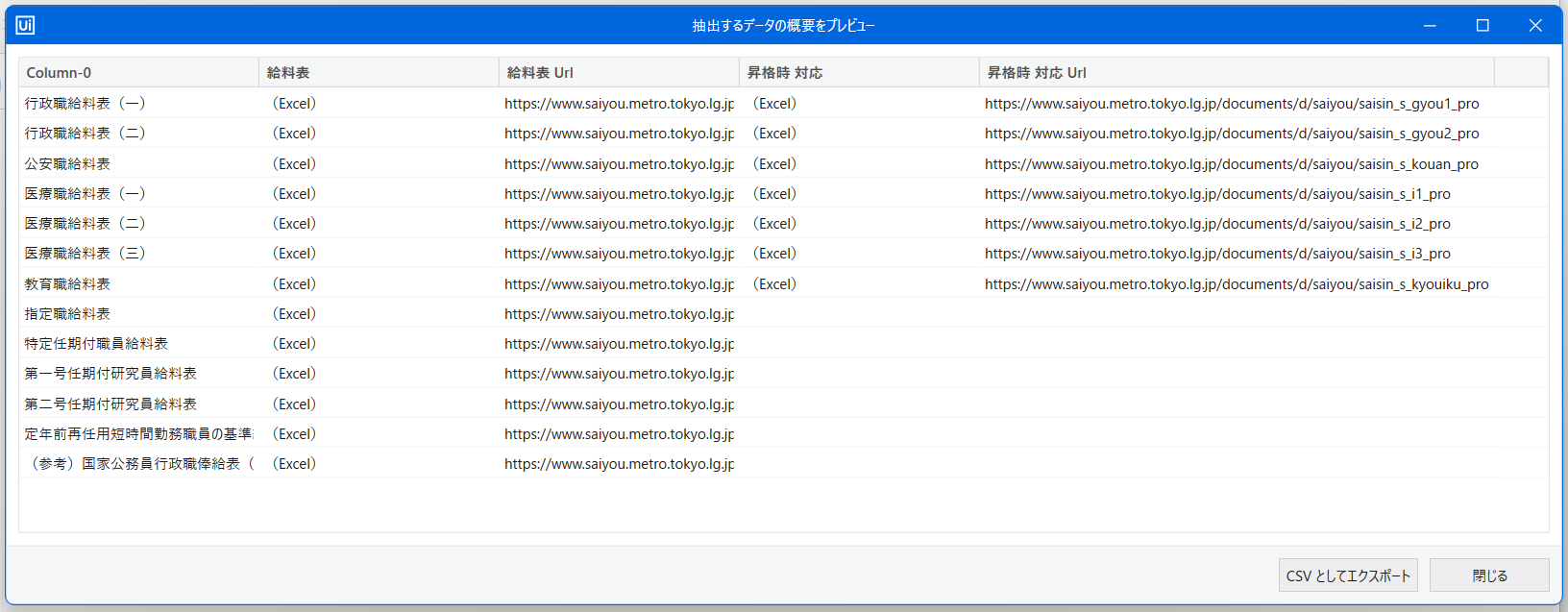
URLがわかった場合は、「ファイルをURLからダウンロード」を使ってみてください!