シリーズ
あくまで予定ですが,こんな感じで書いていこうかなーと思ってます.
- 【とりあえずやってみる】編
- 【自分好みに作りたい】編 <- (イマココ)
- 【リアルタイム可視化機能を作った背景】編 <- (未着手)
- 【技術について理解する】編 <- (未着手)
本来は背景を先に書くべきですが,都合上HowToの部分を先に示します.
背景
CanSatチームFUSiONMission-5では,「宇宙でも使えるOBCを使ったCanSat」というコンセプトのもと,開発を行い2024種子島ロケットコンテストに参加し,ベストプレゼンテーション賞をいただくことができました.
FUSiON では(一部未完成のSubSystemを除いて)GitHubにてソフトウェア等を公開しています.
目的
今回解説するのはMission-5の地上局の使い方です.
前記事では地上局のセットアップとしてとりあえずサンプルを動かすというところをやってもらいました!
と、いうことで今回は「自分なりにデータセットを作ってInfluXDBにデータをぶち込み、これを好きにGrafanaで可視化する」ということをできるようになってもらいます.
また、本記事はゆる募 Advent Calendar 2024/12/17として書いていたりしますー
※あくまで利用法の一つの記事であり,GrafanaやInfluxDBの公式記事ではありません.
対象者層
- リアルタイムでデータを可視化したい人
- センサデータの時間履歴
- ローバ等のGNCデータのリアルタイム表示
- 常微分方程式を解くようなシミュレータの結果のリアルタイム表示
元はCanSatや宇宙機の地上局の簡易版として作ったものですが,結果的に様々な用途が考えられると思うのでとりあえず動かせる環境がPCにあるといろいろ便利な気はします!
可能な限り丁寧に説明しているつもりなのでぜひご覧ください.
前提
前記事を参考に環境構築を行っていることを前提にします.
まだやっていない人は環境構築してからこれ以降を試してください!
今回可視化する時系列データ
前回はランダムデータをテキトウに可視化するという感じのことをしました.
それっぽいデータ名称を付けてもランダムデータだと味気ないので今回はPCの稼働状況を可視化していきます.
psutilというパッケージを使って可視化していきますよ~~
実装の流れ
時系列データを扱う,ということは定期的なデータの中からその長期的なトレンドを知りたかったり,文字列情報(QL)ではわかりにくいことをぱっと見でわかりやすく加工したいというような需要があるんだと思います.(たぶん)
PCのリソースデータに限らず,様々なデータをユースケースに応じで柔軟に可視化できるようになってほしいので,実装の順番に関する考え方からお伝えしようと思います.
このような分け方をすると可視化までの流れがスムーズにいくんじゃないかと思います.
ということで今回はこの流れで作っていきます.
実装
1. 時系列で知りたいデータやぱっと見で知りたいステータスを決める
今回はこんな感じの情報を可視化していきます.
| 名称 (英語) | 名称 (日本語) | 単位 |
|---|---|---|
| timestamp | タイムスタンプ | ISO 8601形式 |
| cpu_percent | CPU使用率 | % |
| cpu_freq | CPU周波数 | MHz |
| memory_percent | メモリ使用率 | % |
| swap_percent | スワップ使用率 | % |
| disk_usage_percent | ディスク使用率 | % |
| disk_read_bytes | ディスク読み込み量 | バイト |
| disk_write_bytes | ディスク書き込み量 | バイト |
| net_sent_bytes | 送信データ量 | バイト |
| net_recv_bytes | 受信データ量 | バイト |
| uptime_seconds | システム稼働時間 | 秒 |
2. とあるタイミングのデータを文字出力ベースで取得できるようにする
clientフォルダの中にget_resource_data.pyを作って以下のソースコードを実行してみてください.
今回書くソースコードは基本的にclientフォルダの中で動かす前提で書いています.
venv環境の中にpsutilが入ってないと思うので,忘れずにpip install psutilしておきましょう.
import psutil
import datetime
def get_resource_data():
"""
現在のPCリソース状態を取得し、辞書形式で返す関数。
"""
data = {
"timestamp": datetime.datetime.now().isoformat(), # データ取得時刻
"cpu_percent": psutil.cpu_percent(interval=1), # CPU使用率 (%)
"cpu_freq": psutil.cpu_freq().current if psutil.cpu_freq() else None, # CPU周波数 (MHz)
"memory_percent": psutil.virtual_memory().percent, # メモリ使用率 (%)
"swap_percent": psutil.swap_memory().percent, # スワップ使用率 (%)
"disk_usage_percent": psutil.disk_usage('/').percent, # ルートディスク使用率 (%)
"disk_read_bytes": psutil.disk_io_counters().read_bytes, # ディスク読み込み (バイト)
"disk_write_bytes": psutil.disk_io_counters().write_bytes, # ディスク書き込み (バイト)
"net_sent_bytes": psutil.net_io_counters().bytes_sent, # 送信データ量 (バイト)
"net_recv_bytes": psutil.net_io_counters().bytes_recv, # 受信データ量 (バイト)
"uptime_seconds": (datetime.datetime.now() - datetime.datetime.fromtimestamp(psutil.boot_time())).total_seconds() # システム稼働時間 (秒)
}
return data
if __name__ == "__main__":
# 関数を呼び出してデータを取得
resource_data = get_resource_data()
# データを表示
for key, value in resource_data.items():
print(f"{key}: {value}")
以下のようなデータが出力されたら成功です!
timestamp: 2024-12-16T01:44:57.878119
cpu_percent: 3.5
cpu_freq: 1400.0
memory_percent: 53.2
swap_percent: 0.8
disk_usage_percent: 60.4
disk_read_bytes: 34828913152
disk_write_bytes: 38440464896
net_sent_bytes: 76336766
net_recv_bytes: 579649076
uptime_seconds: 181395.0
3. InfluxDBにデータを送れるようにする
FUSiON Mission-5で作った地上局用InfluxDBでは時系列データをJSON形式で送信することにしています.
一部を示すとこんな感じです.
json_object = {
"fusion_core_mode":{
"mode":randint_value[0]
},
"app_bme280":{
"valid":randint_value[1],
"temperature_degC":randfloat_value[0],
"humidity_pct":randfloat_value[1],
"pressure_hPa":randfloat_value[2],
"altitude_m":randfloat_value[3]
},
"app_bno055":{
"valid":randint_value[2],
"accel_x_mss":randfloat_value[4],
"accel_y_mss":randfloat_value[5],
....
こんな感じで項目を詳細に分類できるようにしています.
こうすることで,どのドメインデータなのかを明確にすることができ設計が楽になったりします.(今回の場合は先にデータを取れることを確認したかったのでこれを後回しにしました.)
辞書型でとれるようにしているデータをMission-5地上局用のデータフォーマットに形成していきましょう.
先ほどのデータをjsonにフォーマットするのでresource_data_format_json.pyという感じでファイルを作ってください.
import time
from get_resource_data import get_resource_data # get_resource_data関数が保存されているファイルをインポート
import json
def format_to_json(resource_data):
"""
リソースデータをJSON形式にフォーマットする関数。
:param resource_data: 辞書型のリソースデータ
:return: JSON形式にフォーマットされたデータ
"""
output_data = {
"timestamp": {
"timestamp": resource_data.get("timestamp")
},
"cpu": {
"usage_percent": resource_data.get("cpu_percent"),
"frequency_mhz": resource_data.get("cpu_freq")
},
"memory": {
"usage_percent": resource_data.get("memory_percent")
},
"swap": {
"usage_percent": resource_data.get("swap_percent")
},
"disk": {
"usage_percent": resource_data.get("disk_usage_percent"),
"read_bytes": resource_data.get("disk_read_bytes"),
"write_bytes": resource_data.get("disk_write_bytes")
},
"network": {
"sent_bytes": resource_data.get("net_sent_bytes"),
"received_bytes": resource_data.get("net_recv_bytes")
},
"uptime": {
"seconds": resource_data.get("uptime_seconds")
}
}
# JSON形式に変換して返す
return json.dumps(output_data, indent=4)
if __name__ == "__main__":
# 関数を呼び出してデータを取得
resource_data = get_resource_data()
# 取得したデータをJSON形式にフォーマット
json_data = format_to_json(resource_data)
# フォーマットされたJSONデータを表示
print(json_data)
以下のようなデータが出力されてればok
{
"timestamp": "2024-12-16T02:40:55.158508",
"cpu": {
"usage_percent": 4.6,
"frequency_mhz": 1400.0
},
"memory": {
"usage_percent": 51.0
},
"swap": {
"usage_percent": 0.7
},
"disk": {
"usage_percent": 60.4,
"read_bytes": 35132150784,
"write_bytes": 40058823168
},
"network": {
"sent_bytes": 112987116,
"received_bytes": 635992536
},
"uptime": {
"seconds": 184752.0
}
}
FUSiON Mission-5では,この形式にフォーマットされたデータをCOMポートから受け取ってデータ形成してinfluxDBに流すという方式を取りました.
後はこんな感じでloop回してinfluxDBに入れ続ければOKです!
100回loopになっていてそこそこ時間かかるので,10とかに減らして実行しましょう
import psutil
import datetime
import json
from get_resource_data import get_resource_data
from resource_data_format_json import format_to_json
import write_db
if __name__ == "__main__":
database = write_db.WriteDb()
# 100回ループしてリソースデータを取得し、JSON形式にフォーマット
for i in range(100):
# リソースデータを取得
resource_data = get_resource_data()
# 取得したデータをJSON形式にフォーマット
json_data = format_to_json(resource_data)
# フォーマットされたJSONデータを表示
print(f"Data {i + 1}:")
print(json_data)
print("-" * 50) # データの区切り線
# うまくいったらInfluxDB書き込み,行かなかったらエラー表示
try:
write_data = json.loads(json_data)
database.write_bulk(write_data)
except Exception as e:
print("writing error")
print(f"エラーが発生しました: {e}")
Docker経由でInfluxDBを立ち上げていないので,try-excptでexcpt側に行くと思います.以下の感じで出力されてればOK
--------------------------------------------------
writing error
Data 10:
{
"timestamp": "2024-12-16T03:03:34.928777",
"cpu": {
"usage_percent": 2.0,
"frequency_mhz": 1400.0
},
"memory": {
"usage_percent": 50.8
},
"swap": {
"usage_percent": 1.0
},
"disk": {
"usage_percent": 60.4,
"read_bytes": 35165858304,
"write_bytes": 40549179904
},
"network": {
"sent_bytes": 126360256,
"received_bytes": 651948112
},
"uptime": {
"seconds": 186111.217238
}
}
--------------------------------------------------
次でGrafanaにぶち込まれているか,確認しに行きます.
4. Grafanaでデータが一括で可視化できることを確認する
先ほどloop回数を減らしているはずなので,100回とか多めに戻すといいかもですね
Dockerを立ち上げ(Docker Desktop開いたうえで,ローカルリポジトリでdockeer compose up -d),てresource_write_db.pyを実行してください.
そしたらhttp://localhost:8085/dashboardsにアクセスしてください.
(デフォルトであればユーザID,パスワードともにadmin)
こんな感じで一括で可視化しているのが見られるはずです.

ということで,データ生成→InfluxDBにデータ投入→可視化まで確認できました!
続いてはInfluxDBでお好みダッシュボードを作る説明をしていきます!
5. 自分好みのダッシュボードを作る
DBからデータを取ってくる命令のことをクエリ(query)と呼びます.
なんで唐突にこの話をしたかというと,今から皆さんにクエリを書いてもらうからです.
とはいっても一部を改変するだけで簡単に可視化できるのでそう身構えなくてOKです
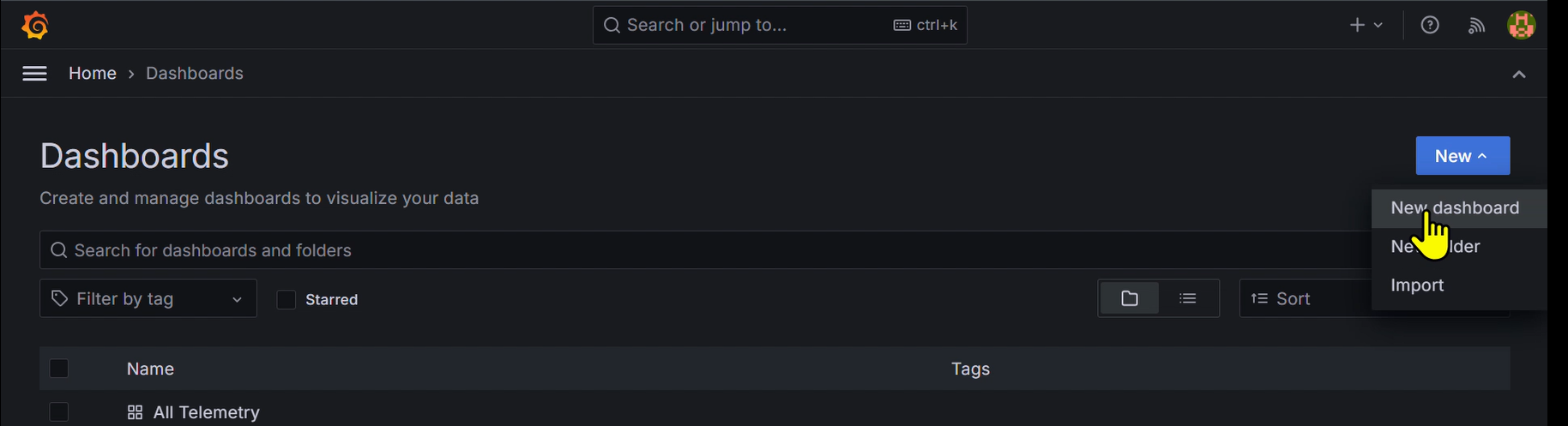
とりあえず,こんな感じで新しくダッシュボードを作ってみます.
青いnew^のところをクリック ↓参考
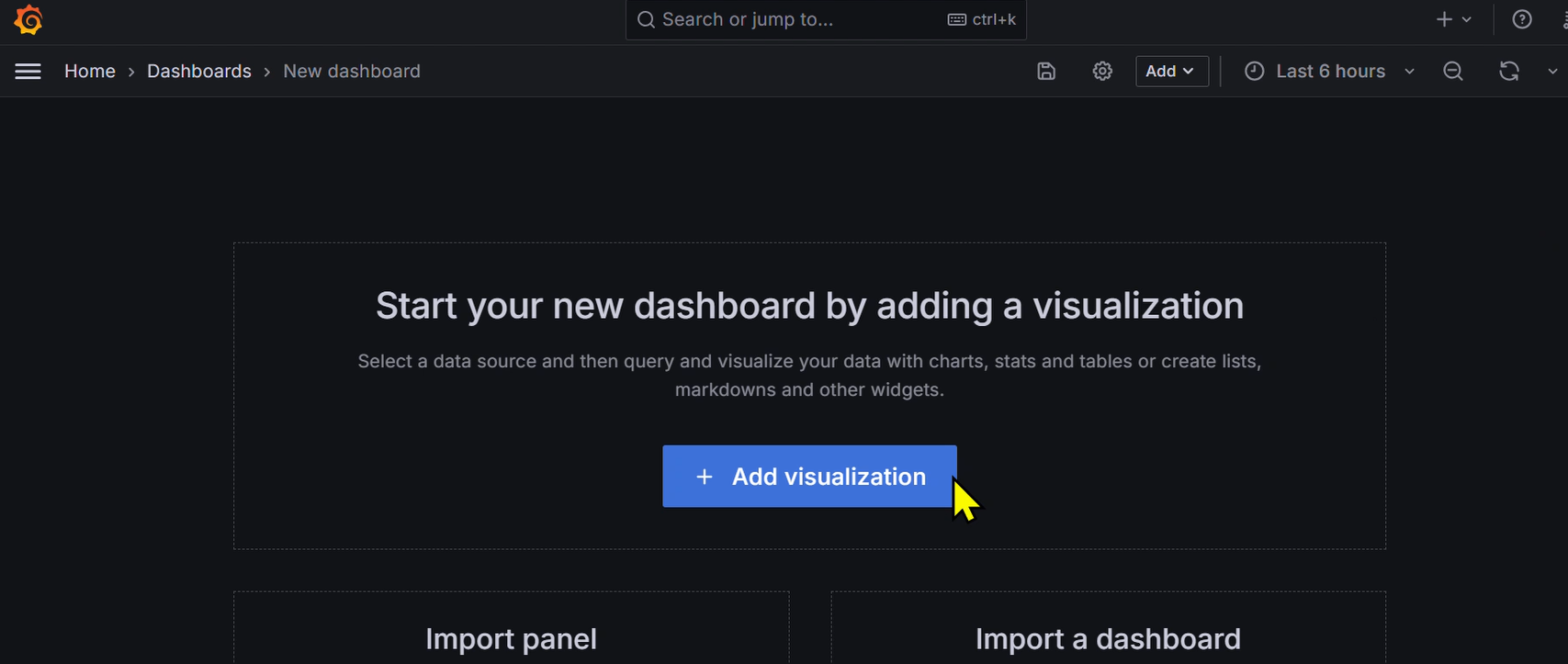
- Add visuallization のところをクリック ↓参考
InfluxDBをクリック ↓参考

1 と書いてあるところにクエリをぶち込む

ここにクエリってやつをぶち込みます.
これは,データのフィールドキー名を出してくれるクエリで,とりあえず何があるのかがはあくできます.
from(bucket: "Data")
|> range(start: -1h) // 過去1時間のデータを取得
|> filter(fn: (r) => r["_measurement"] == "FUSiON_CanSat")
|> keep(columns: ["_field"])
|> distinct(column: "_field")
こんな感じで一覧を出してくれます.

新しくグラフを追加したいときは以下のようにAdd^と書いてあるところをクリックし,Visualizationをクリックすると,例のクエリ打ち込み画面が出てきます.
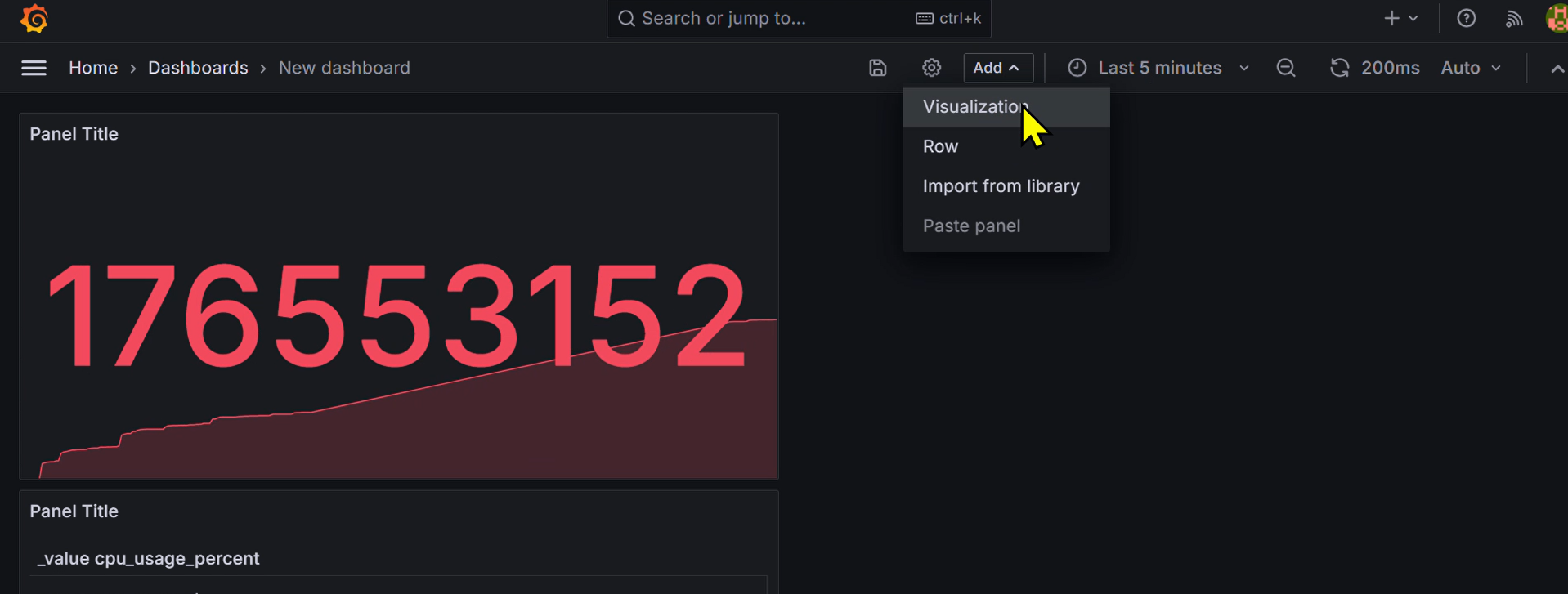
↓
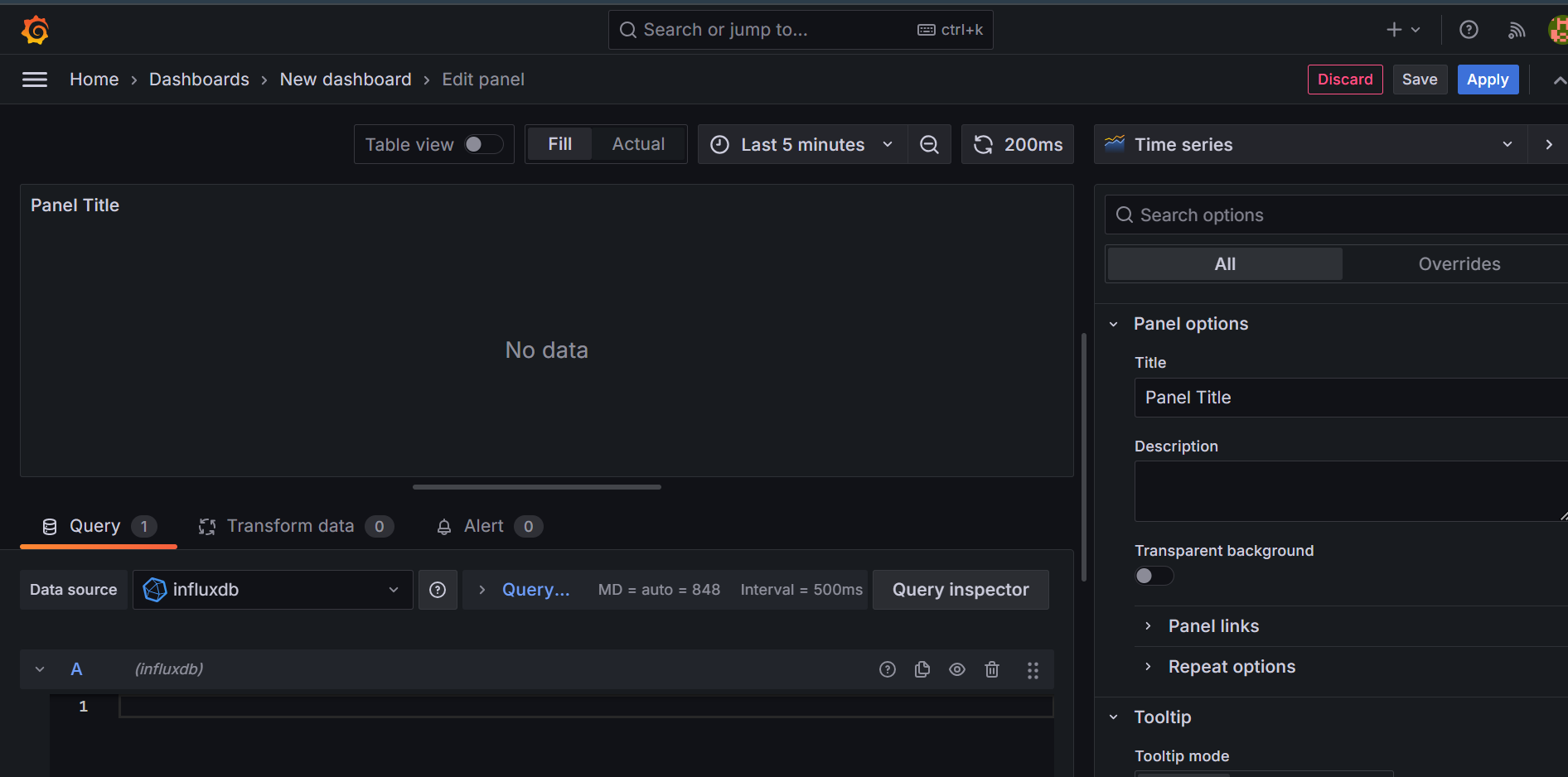
続いて,以下の[fieldkeyname]のところにさっきのフィールドキーをぶち込むといい感じに可視化してくれます.
from(bucket: "Data")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "FUSiON_CanSat")
|> filter(fn: (r) => r["_field"] == "[fieldkeyname]")
|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false)
|> yield(name: "last")
例えばcpu_usage_percentとすると ↓参考

こんな感じで可視化されます(Applyで一覧のところに戻れます.)
ということであとはごにょごにょやればこんな感じでダッシュボードを作ることができます!
(ちょっとそこまでやってる時間がなかったのですが,1分間の平均メモリ使用量とかも計算できるはず,配置のセンスないのとかはごめんなさい())

他の例
筆者は姿勢屋さんなので,シミュレーションデータの可視化とかにも使おうとしてます.
後でこっちのコードも公開するかも?

さいごに
不明点等あったらGitHubhttps://github.com/CanSat-FUSiON/mission5-ground-stationの方でissue立ててもらってもいいですし、ここに質問してくれてもいいです。
謝辞
Mission-5で「Grafana + InfluxDB」という構成で地上局を動かすことができたのは,以下のメンバーのおかげです.
https://github.com/MayaAbe
https://github.com/Ka-Sou
https://github.com/771-8bit
詳細な経緯等についてはシリーズ3番目の【リアルタイム可視化機能を作った背景】編にて書かせていただきます.