はじめに
今回はスクレイピングについての記事を投稿していこうと思います。
突然なんですが、みなさんに質問して見たいことがあります。
みなさんは初めてスクレイピングをした時の気持ちを覚えてますか?
自分個人の話をすると、初めてスクレイピングできた時、神になった気分でした。どんな情報でも取ってこられるんじゃないかとワクワクしたものです。
この記事では、Xpathというものの存在を知り、試しに使ってみることを目的としています。習うより慣れよというスタンスのため、Xpathそのものに関しては特に説明いたしません。最初のうちはXpathの記法が理解できないかもしれませんが、それでも、スクレイピングで使うことはできるので、ぜひ試して見てください。
途中でアクシデントが起こりますが、最後までお付き合い頂けると嬉しいです。
今回やること
- HTMLタグを指定した基本的なスクレイピングで取りたい情報を抜き取る。
- 同じものをxpathで指定してスクレイピングしてくる。
- Qiitaのトレンドをxpathを応用して取ってくる。
Xpathに慣れてみよう
試しにHTMLタグを使ってスクレイピングして見ましょう。
今回は練習としてこちらのサイトを使って見たいと思います。
このサイトから、上の北海道、東北etc...のようなタブを取ってきましょう。

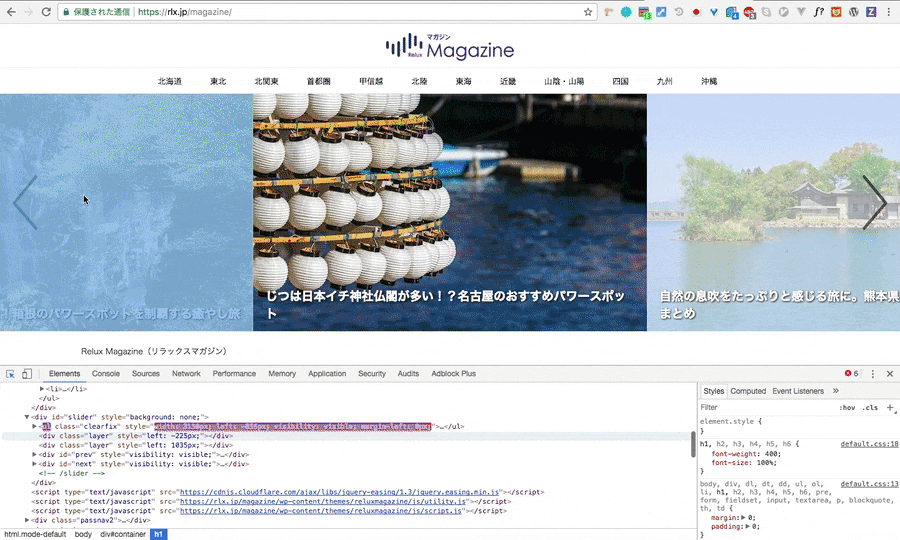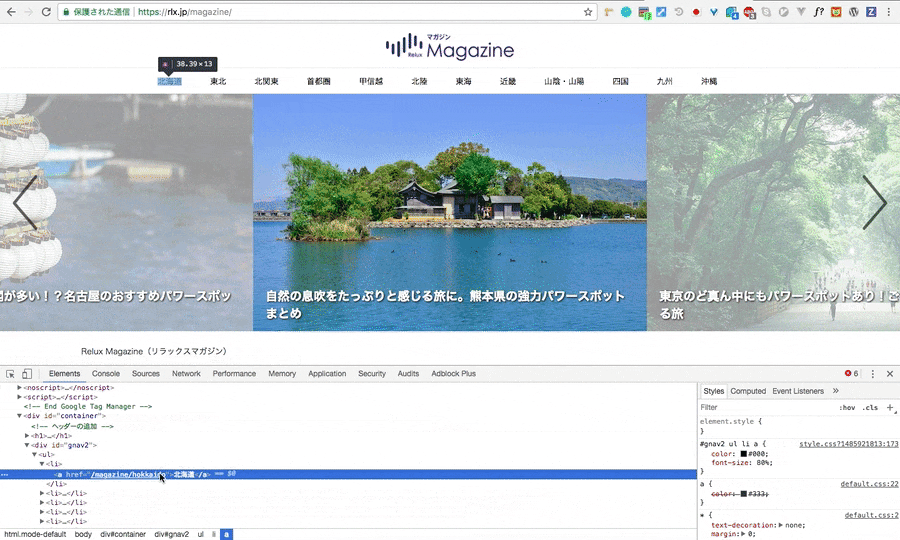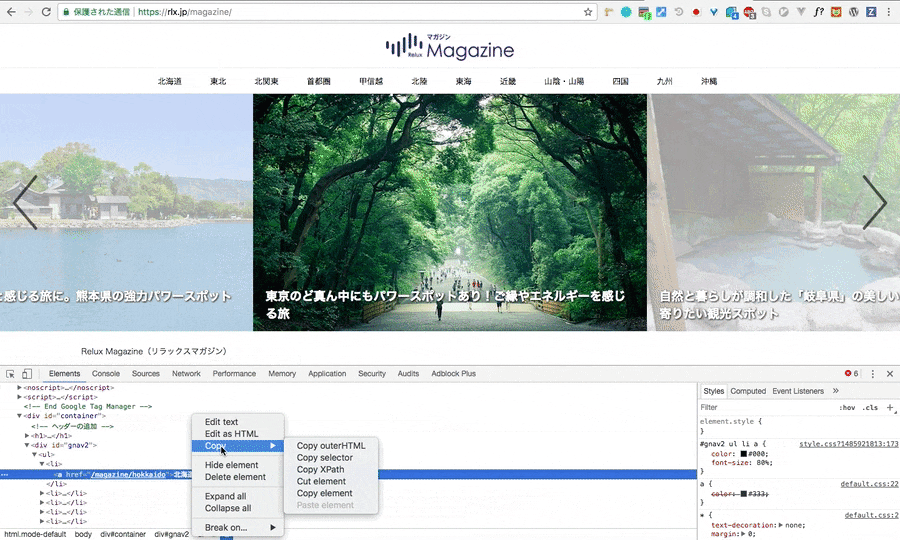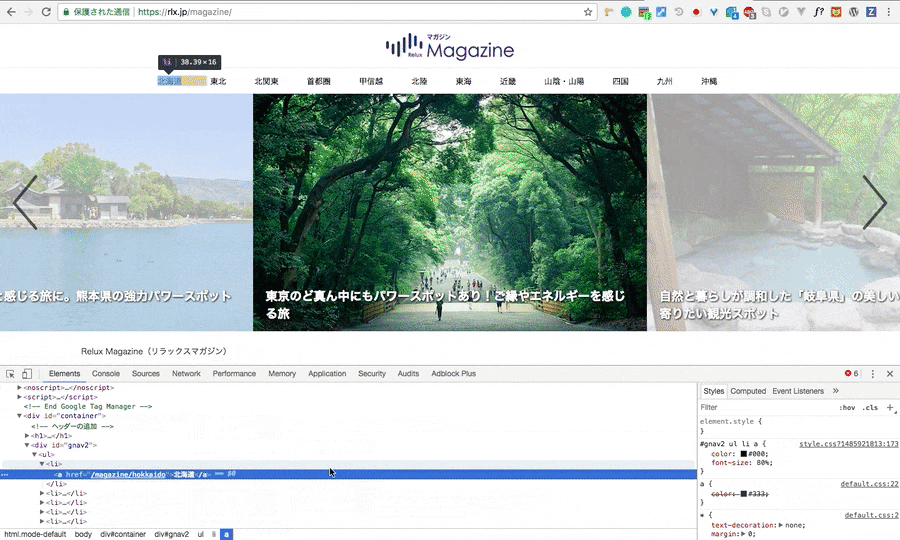
まず、ブラウザの検証機能を開き、どのようなHTMLの構造になっているのかを確認します。試しに、北海道のタブがどうなっているかを確認して見ます。下の画像を見て見ましょう。

こちらから、aタグのリンクとタイトルを取ってきます。
require 'mechanize'
agent = Mechanize.new
agent.user_agent_alias = 'Windows IE 9'
ScrapingPage = 'https://rlx.jp/magazine/'
current_page = agent.get(ScrapingPage)
areaTabs = current_page.search('li a')
areaTabs.each do | areaTab |
areaName = areaTab.inner_text
areaRelPath = areaTab[:href]
puts "#{ areaName } : #{ areaRelPath }"
end
さて、実行結果を見て見ましょう。
北海道 : /magazine/hokkaido
東北 : /magazine/tohoku
北関東 : /magazine/kitakanto
首都圏 : /magazine/shutoken
甲信越 : /magazine/koshinetsu
北陸 : /magazine/hokuriku
東海 : /magazine/tokai
近畿 : /magazine/kinki
山陰・山陽 : /magazine/sanin-sanyo
四国 : /magazine/shikoku
九州 : /magazine/kyushu
沖縄 : /magazine/okinawa
: https://rlx.jp/magazine/shutoken/51849.html
東京のど真ん中にもパワースポットあり!ご縁やエネルギーを感じる旅 : https://rlx.jp/magazine/shutoken/51849.html
: https://rlx.jp/magazine/tokai/50831.html
自然と暮らしが調和した「岐阜県」の美しい温泉地と、一緒に立ち寄りたい観光スポット : https://rlx.jp/magazine/tokai/50831.
: https://rlx.jp/magazine/shutoken/49735.html
都心から1.5時間で到着!箱根のパワースポットを制覇する癒やし旅 : https://rlx.jp/magazine/shutoken/49735.html
: https://rlx.jp/magazine/kyushu/50805.html
自然の息吹をたっぷりと感じる旅に。熊本県の強力パワースポットまとめ : https://rlx.jp/magazine/kyushu/50805.html
: https://rlx.jp/magazine/tokai/49872.html
じつは日本イチ神社仏閣が多い!?名古屋のおすすめパワースポット : https://rlx.jp/magazine/tokai/49872.html
歴史スポット : https://rlx.jp/magazine/tag/%e6%ad%b4%e5%8f%b2%e3%82%b9%e3%83%9d%e3%83%83%e3%83%88
散策・探訪 : https://rlx.jp/magazine/tag/%e6%95%a3%e7%ad%96%e3%83%bb%e6%8e%a2%e8%a8%aa
おすすめ : https://rlx.jp/magazine/tag/%e3%81%8a%e3%81%99%e3%81%99%e3%82%81
癒し・リラックス : https://rlx.jp/magazine/tag/%e7%99%92%e3%81%97%e3%83%bb%e3%83%aa%e3%83%a9%e3%83%83%e3%82%af%e3%82%b9
景色・鑑賞 : https://rlx.jp/magazine/tag/%e6%99%af%e8%89%b2%e3%83%bb%e9%91%91%e8%b3%9e
料理・グルメ : https://rlx.jp/magazine/tag/gourmet
絶景 : https://rlx.jp/magazine/tag/%e7%b5%b6%e6%99%af
高級ホテル : https://rlx.jp/magazine/tag/%e9%ab%98%e7%b4%9a%e3%83%9b%e3%83%86%e3%83%ab
高級旅館 : https://rlx.jp/magazine/tag/%e9%ab%98%e7%b4%9a%e6%97%85%e9%a4%a8
温泉 : https://rlx.jp/magazine/tag/onsen
旅館 : https://rlx.jp/magazine/tag/ryokan
ホテル : https://rlx.jp/magazine/tag/hotel
自然 : https://rlx.jp/magazine/tag/%e8%87%aa%e7%84%b6
宿・宿泊 : https://rlx.jp/magazine/tag/%e5%ae%bf%e3%83%bb%e5%ae%bf%e6%b3%8a
観光 : https://rlx.jp/magazine/tag/sightseeing
: https://itunes.apple.com/jp/app/id843104033
: https://play.google.com/store/apps/details?id=com.loco_partners.relux&hl=ja
: https://www.facebook.com/rlx.jp
: https://twitter.com/relux_jp
: https://plus.google.com/+RlxJp/posts
: http://instagram.com/relux_jp
ナンジャコリャ!!!
いらない要素まで含まれてしまいました。原因は明らかですね。
li a って要素がたくさんあったのです。例えば、該当部分のHTMLをもう一度見てみると、取りたい要素を取ってくるためには、 #gnav2 ul li a としてあげれば良さそうです。
その部分を修正したコードがこちらになります。
require 'mechanize'
agent = Mechanize.new
agent.user_agent_alias = 'Windows IE 9'
ScrapingPage = 'https://rlx.jp/magazine/'
current_page = agent.get(ScrapingPage)
areaTabs = current_page.search('#gnav2 ul li a')
areaTabs.each do | areaTab |
areaName = areaTab.inner_text
areaRelPath = areaTab[:href]
puts "#{ areaName } : #{ areaRelPath }"
end
こうすると、
北海道 : /magazine/hokkaido
東北 : /magazine/tohoku
北関東 : /magazine/kitakanto
首都圏 : /magazine/shutoken
甲信越 : /magazine/koshinetsu
北陸 : /magazine/hokuriku
東海 : /magazine/tokai
近畿 : /magazine/kinki
山陰・山陽 : /magazine/sanin-sanyo
四国 : /magazine/shikoku
九州 : /magazine/kyushu
沖縄 : /magazine/okinawa
取ってきたい要素が取れました!
でも、 全然スマートじゃない!!!
もし、今回のようにdivタグに対して、class名が与えられていない場合にはどうするのかや、もっとスマートにスクレイピングしたい。そんなときに役に立つのがXpathなんです!!!
Xpathでスクレイピングしてみよう
上と同じサイトを Xpath を用いてスクレイピングしてみようと思います。
まず、Xpathを使用するために、スクレイピングしてきたい要素のXpathを取得しましょう。
ブラウザの検証機能(gif画像はchromeの物です)を開き、スクレイピングをしたい要素のHTMLを指定。その要素上で右クリックをし、Copyを選択、その後CopyXpathで完了です。
どうです?簡単でしょう?
詳しくは下の動画を参照してください。
コピーしてきたXpathはこちらになります。
//*[@id="gnav2"]/ul/li[1]/a
そして、スクレイピングをするためのコードを記述していこうと思います。
require 'mechanize'
agent = Mechanize.new
agent.user_agent_alias = 'Windows IE 9'
ScrapingPage = 'https://rlx.jp/magazine/'
current_page = agent.get(ScrapingPage)
areaTabs = current_page.search('//*[@id="gnav2"]/ul/li[1]/a') #この部分だけ編集しています。
areaTabs.each do | areaTab |
areaName = areaTab.inner_text
areaRelPath = areaTab[:href]
puts "#{ areaName } : #{ areaRelPath }"
end
実行結果は次のようになります。
北海道 : /magazine/hokkaido
北海道だけが取ってこれました。
何かおかしいなと思うかもしれませんが、これはこれで正しいのです。XpathはHTML要素一つ一つに与えられていて、どの要素かを特定することができます。今回の場合だと、
'//*[@id="gnav2"]/ul/li[1]/a'
**li[1]**に注目して見ます。Xpathの特徴として、同じタグで複数要素あるものに対しては、配列のように順番を与え、どの要素かを特定しております。配列と異なる点としましては、配列は0番から要素に番号が与えられるのに対し、Xpathでは1番から順番から与えられます。
北海道ではなく、東北を取得してこようとすると、**li[1]の部分がli[2]**というふうになるわけです。
では、全てのタブを取得するように拡張するにはどうしたらいいのでしょうか?
liの番号でどのタブかを指定しているということは、li全てを取ってきたらいいことになります。そのようにコードを変更して見ましょう。
require 'mechanize'
agent = Mechanize.new
agent.user_agent_alias = 'Windows IE 9'
ScrapingPage = 'https://rlx.jp/magazine/'
current_page = agent.get(ScrapingPage)
areaTabs = current_page.search('//*[@id="gnav2"]/ul/li/a') #この部分だけ編集しています。
areaTabs.each do | areaTab |
areaName = areaTab.inner_text
areaRelPath = areaTab[:href]
puts "#{ areaName } : #{ areaRelPath }"
end
実行結果はもちろんエリアのタブの全ての名前とリンクが取ってこれています。
北海道 : /magazine/hokkaido
東北 : /magazine/tohoku
北関東 : /magazine/kitakanto
首都圏 : /magazine/shutoken
甲信越 : /magazine/koshinetsu
北陸 : /magazine/hokuriku
東海 : /magazine/tokai
近畿 : /magazine/kinki
山陰・山陽 : /magazine/sanin-sanyo
四国 : /magazine/shikoku
九州 : /magazine/kyushu
沖縄 : /magazine/okinawa
Xpathのメリット
- コピペで使えるので要素をHTMLの階層構造を考えなくていい! これに尽きます!!!
- 並列要素は番号を削除するだけで、並列要素全てを取ってこれるので楽。
- 自分が想定していない要素を取ってくる心配がなくなる。
これらになるかなと思います。
実際にQiitaのトレンドを取得しよう。
さて、それでは、本題に入りたいと思います。QiitaのトレンドをXpathを用いて取得してみようと思います。
先ほどのように、検証画面を開き、一番上の投稿のXpathをcopyしてこようと思います。
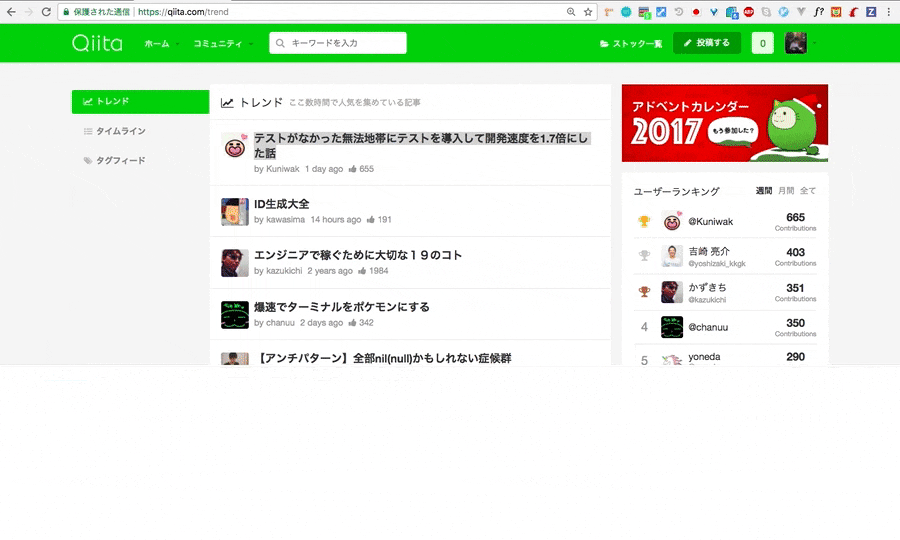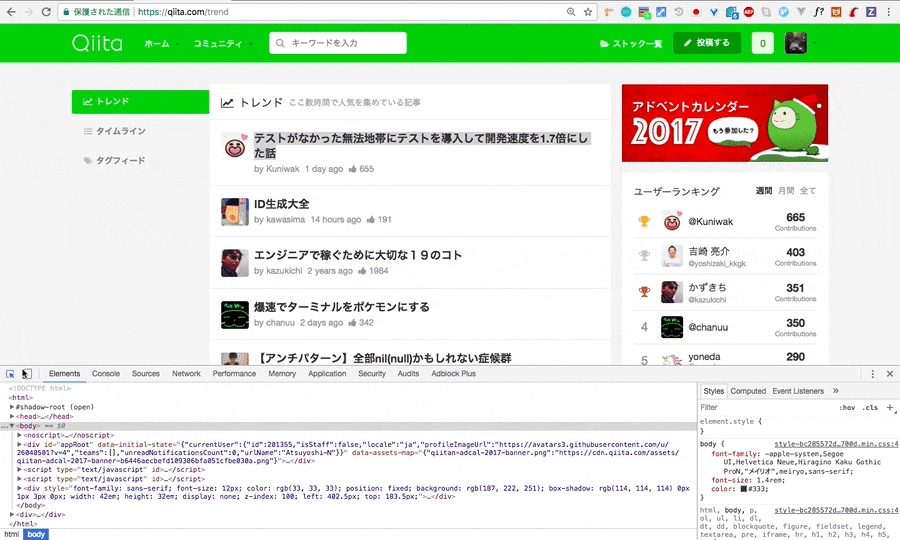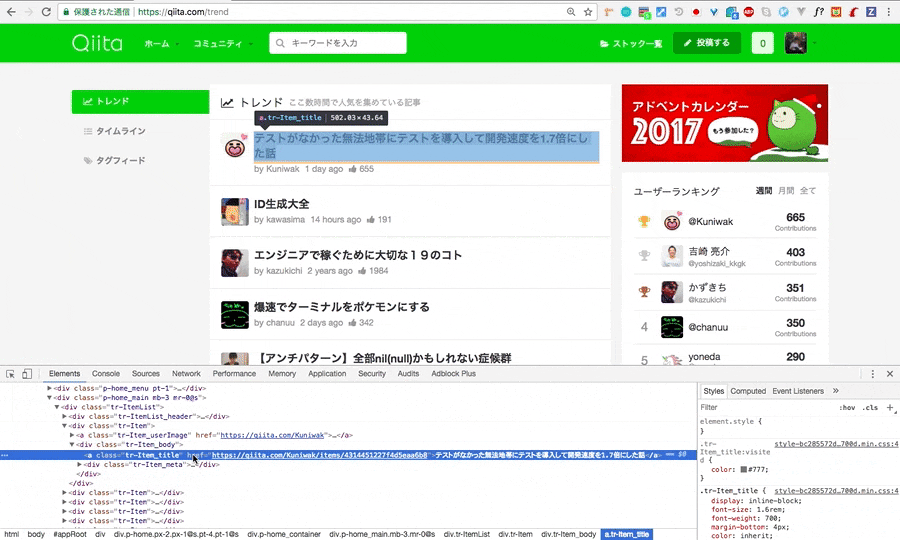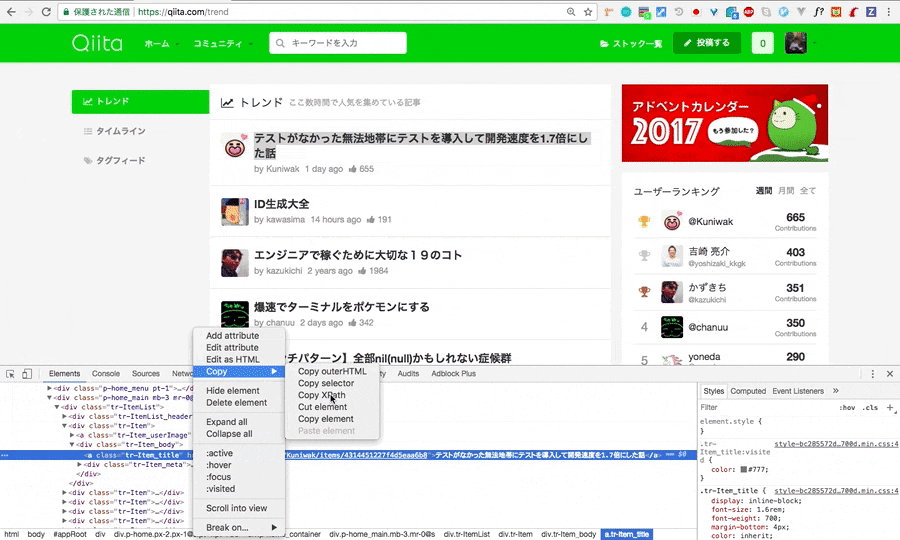
今回はわかりやすくするために、上から二個のXpathをコピーしました。
下に、比較しやすいように取ってきた2つを並べて見ました。
//*[@id="appRoot"]/div/div[2]/div/div[2]/div/div[2]/div/a
//*[@id="appRoot"]/div/div[2]/div/div[2]/div/div[3]/div/a
どこが違うかは一目瞭然ですね。それでは、違う数字が入っているところの数字部分を消去し、スクレイピングをして見ます。
require 'mechanize'
agent = Mechanize.new
agent.user_agent_alias = 'Windows IE 9'
QiitaTrendURL = 'https://qiita.com/trend'
QiitaTrendPage = agent.get(QiitaTrendURL)
todaysTrends = QiitaTrendPage.search('//*[@id="appRoot"]/div/div[2]/div/div[2]/div/div/div/a')
todaysTrends.each do | trend |
puts "#{trend.inner_text}: #{trend[:href]\n"
end
これで取れるだろう!と思い試してみると、何も表示されない!!!
どうしてだろうと思い、ChromeのシークレットモードでqiitaのトレンドURLにアクセスしてみる。
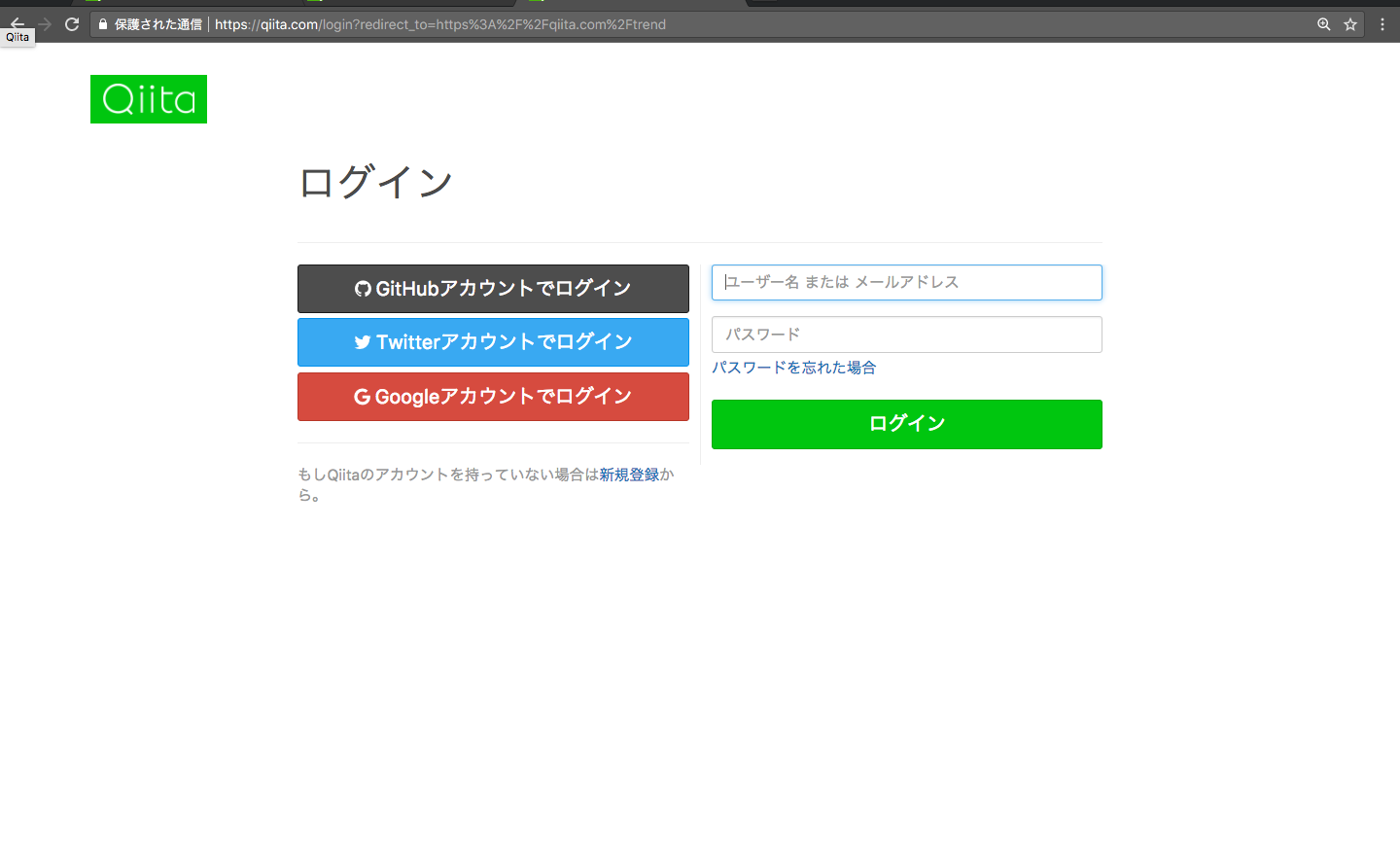
なぜだぁぁぁ!!!12月入ってからいつのまにかセキュリティが強化されていました。11月までは、ログインしなくても取れたのに、、、
メールアドレスでログインしているならそのままMechanizeでログイン処理はかけるけど、、、GitHubアカウントでログインしちゃっているし、Seleniumを使ってGitHubアカウントでログインしようとしたけど、2段階認証がかかっていたため、それもできませんでした。突然の仕様変更なので仕方ないですね。
解決したら、またQiitaを書こうと思います。
Xpathの威力を感じてみる。
このままでは、終わるに終われないので、違うサイトを探して見ました。CodeZineという開発者向けのWebサービスから情報を抜き取ってこようと思います。
このページの右側にある人気ランキングを取得してくるスクリプトを書きましょう。
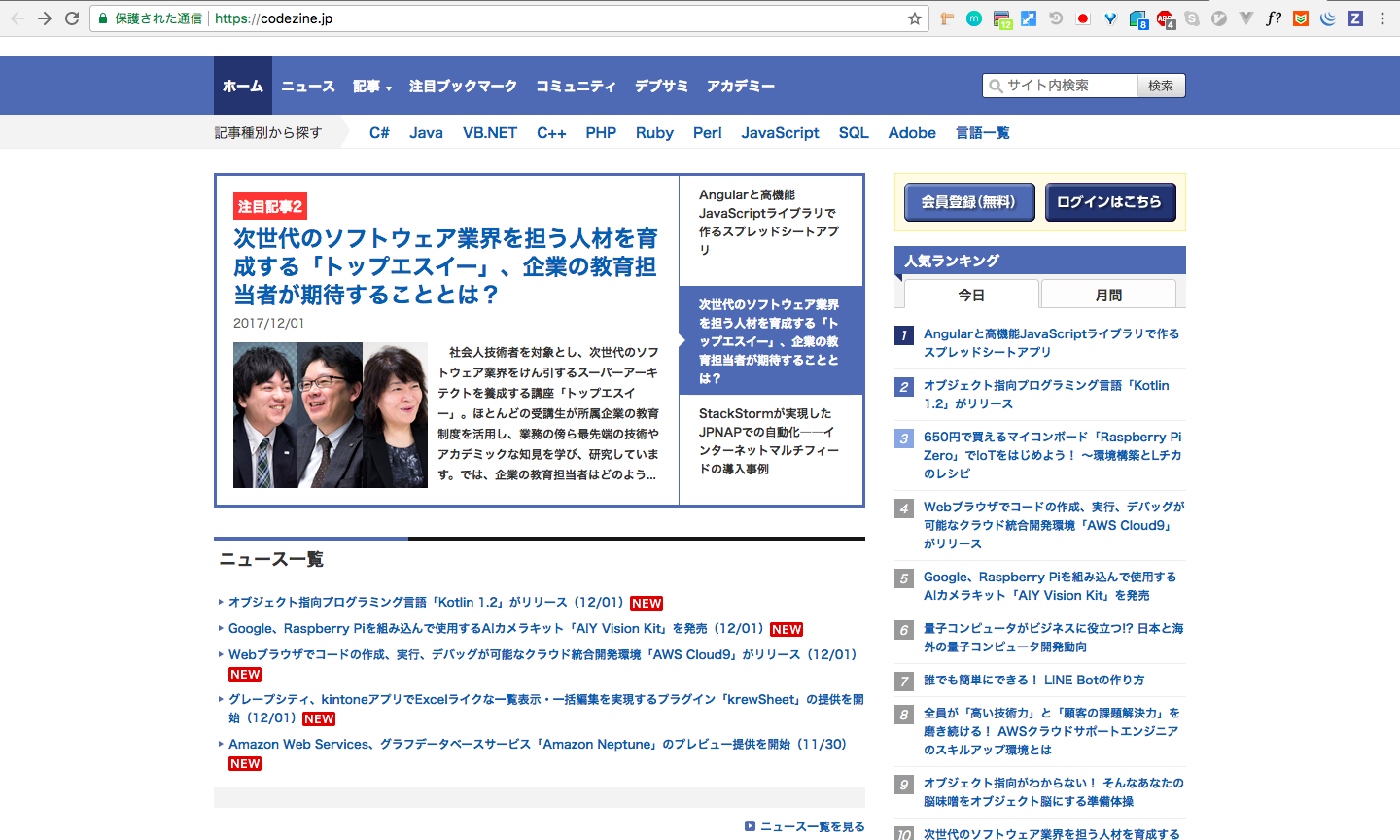
例のごとく、検証をし、Xpathをコピーしてきます。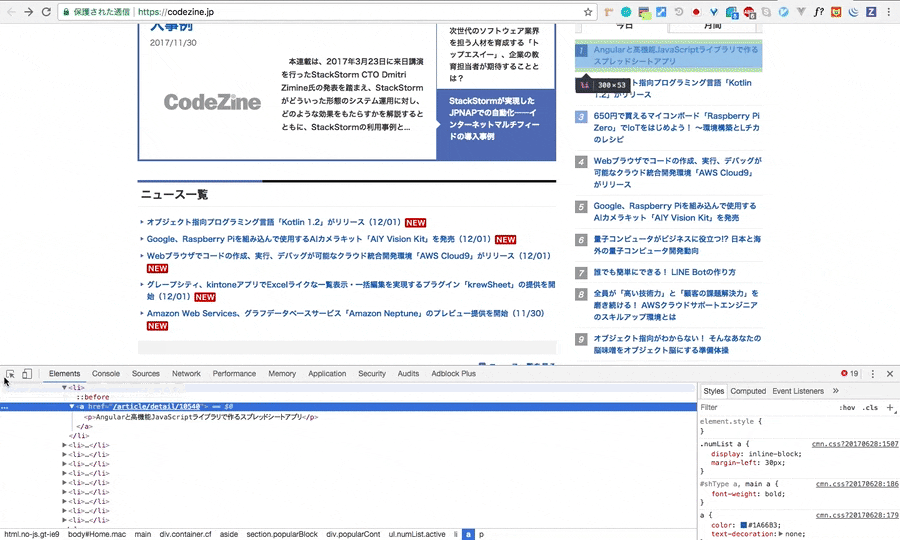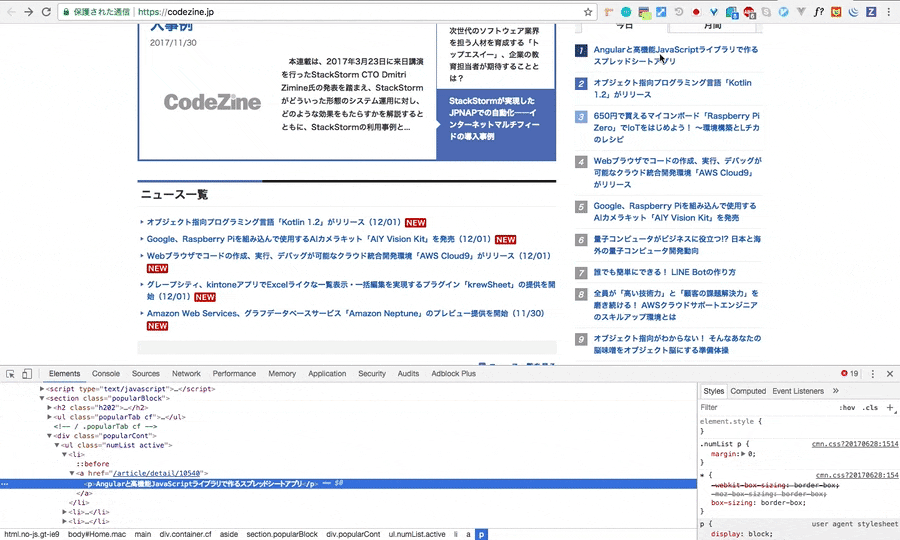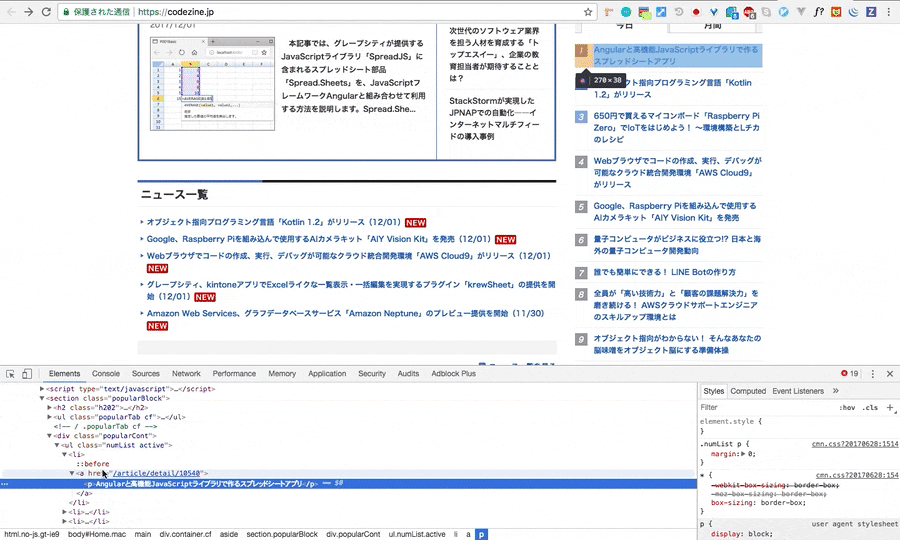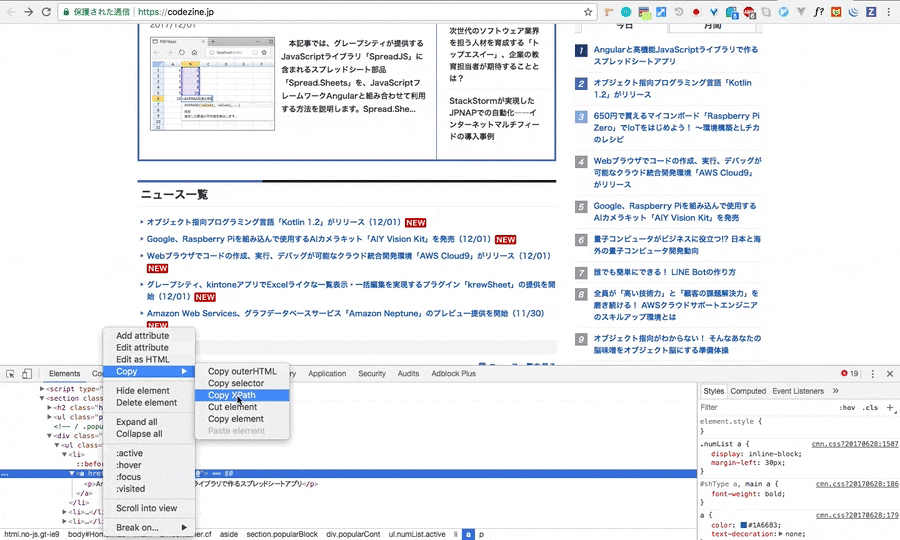
取ってきたXpathは今回は次のようになります。
//*[@id="Home"]/main/div/aside/section[3]/div/ul[1]/li[1]/a
明らかにliが並列されていることが、gif画像から確認できるので、**li[1]の[1]**の部分を削除し、コードを記述すると良さそうです。
require 'mechanize'
agent = Mechanize.new
agent.user_agent_alias = 'Windows IE 9'
CodeZineTopURL = 'https://codezine.jp'
current_page = agent.get(CodeZineTopURL)
latestArticles = current_page.search('//*[@id="Home"]/main/div/aside/section[3]/div/ul[1]/li/a')
latestArticles.each do | article |
puts "#{ article.inner_text }: #{ CodeZineTopURL + article[:href] }\n"
end
たったこれだけで、人気ランキング全てを取ってくることができます。
終わりに
Xpathはliなどの並列に要素が並ぶものなどでかなり、その力を発揮してくれます。普段の自分のスクレイピングに1アレンジを加えて見てはいかがでしょう?
慣れてしまうと病みつきになりますよ!!!