はじめに
強化学習に取り組む予定が生まれ、入門として下記の講座に取り組みました。
本記事では講座を受けてみての所感と、講座内で紹介されていたOpenAI Gymを使ったCartPoleの実装について述べます。
講座概要
5セクションから構成され、動画時間は計4.5時間ありました。
1セクションに1日1時間くらい費やして5日間かけて受講しました。
講座の内容は以下の通りです。
- 強化学習の概要
- シンプルな強化学習(Q学習の実装)
- 強化学習の原理(数式の解説、SARSAの実装)
- 深層強化学習(DQNの解説、Fixed Target Q-Networkの実装)
- 強化学習の応用(深層強化学習の実装(OpenAI Gym))
所感
入門書の解説を一冊まるまる聞いているような感覚でした。
全体を俯瞰してからシンプルなQ学習に始まり、数式の解説をして流行りのディープを解説、という流れ。
動画での学習の場合、一度始めるとキリの良いところまでやろうという気に自分はなれたので意外と良かったです。
Google Colaboratoryのコードの穴埋めや改変を行う形の演習が各セクションに用意されています。
コードをじっくり読むという意味では良いですが、いかんせん自分で書く量が少なすぎるので物足りないと思う人もいるかもしれません。
本での学習と比べてここが大きな差別化点だと思っていましたが、最近の書籍はgithubでコードを公開しているものも多いので、内容というよりどちらが自分に合っているかの方が重要だと感じました。
コースの金額は通常9600円となかなかのお値段ですが、この記事を執筆しているタイミング(2021.11.30)で88%オフで1200円と驚きのセールをやっていました。こういったセールのタイミングに巡り合えれば買う価値はあると思います。(私は会社のお金で受講させてもらいました。弊社最高!)
OpenAI Gym
講座内で使用されているコードは特別なライブラリやプラットフォームを使わずに実装されています。
今回は講座内で存在を紹介されるにとどまっていた強化学習プラットフォームのOpenAI Gymを使ってみました。
学習したことを活かし、Q学習を使ってCatpole問題を学習させてみました。
CartPole
左右に動くカートの上にポールを立て、一定の幅の中で倒れたり壁にぶつからないように上手くバランスを取る問題です。
学習が不十分だと下のように画面端に倒れかかっていってしまいます。

インストール
pip install gym
このコマンドではベースの問題についてしか入らないため、Atariなどの発展的な内容のゲームについては
pip install gym[all]
としてやることで扱うことができるようになります。
実装
ライブラリ
gymと描画用のmatplotlibを使います。
import gym
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
ENV = "CartPole-v0" # 使用する課題名
NUM_DIZITIZED = 6 # 各状態の離散値への分割数
GAMMA = 0.99 # 時間割引率
ETA = 0.5 # 学習係数
MAX_STEPS = 200 # 1試行のstep数
NUM_EPISODES = 1000 # 最大試行回数
描画用関数
matplotlibのanimationを使うとGIFの生成から保存まで簡単に行うことができます。
def display_frames_as_gif(frames):
plt.figure(figsize=(frames[0].shape[1] / 72.0, frames[0].shape[0] / 72.0), dpi=72)
patch = plt.imshow(frames[0])
plt.axis("off")
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=50)
anim.save("movie_cartpole.gif")
エージェント
環境に働きかけるエージェントを定義します。
CartPoleの場合、取る行動の選択肢は左右移動の2つです。
class Agent:
def __init__(self, num_states, num_actions):
# 課題の状態と行動の数を設定
self.num_states = num_states
self.num_actions = num_actions
self.brain = Brain(num_states, num_actions) # エージェントが行動を決定するためのBrainを生成
def update_q_function(self, observation, action, reward, observation_next):
# Q関数の更新
self.brain.update_Qtable(observation, action, reward, observation_next)
def get_action(self, observation, step):
# 行動の決定
action = self.brain.decide_action(observation, step)
return action
Brain
観測された状態を元にQテーブルを更新していきます。
class Brain:
def __init__(self, num_states, num_actions):
self.num_states = num_states
self.num_actions = num_actions
# Qテーブルの作成
self.q_table = np.random.uniform(
low=0, high=1, size=(NUM_DIZITIZED ** self.num_states, self.num_actions)
)
def bins(self, clip_min, clip_max, num):
# 観測した状態(連続値)を離散値にデジタル変換
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
def digitize_state(self, observation):
# 観測した状態を離散値に変換
cart_pos, cart_v, pole_angle, pole_v = observation
digitized = [
np.digitize(cart_pos, bins=self.bins(-2.4, 2.4, NUM_DIZITIZED)),
np.digitize(cart_v, bins=self.bins(-3.0, 3.0, NUM_DIZITIZED)),
np.digitize(pole_angle, bins=self.bins(-0.5, 0.5, NUM_DIZITIZED)),
np.digitize(pole_v, bins=self.bins(-2.0, 2.0, NUM_DIZITIZED)),
]
return sum([x * (NUM_DIZITIZED ** i) for i, x in enumerate(digitized)])
def update_Qtable(self, observation, action, reward, observation_next):
# QテーブルをQ学習により更新
# 観測を離散化
state = self.digitize_state(observation)
state_next = self.digitize_state(observation_next)
Max_Q_next = max(self.q_table[state_next][:])
self.q_table[state, action] = self.q_table[state, action] + ETA * (
reward + GAMMA * Max_Q_next - self.q_table[state, action]
)
def decide_action(self, observation, episode):
# 徐々に最適行動を採用
state = self.digitize_state(observation)
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
action = np.argmax(self.q_table[state][:])
else:
action = np.random.choice(self.num_actions) # 0,1の行動をランダムに返す
return action
環境
CartPole問題を設定し、報酬の与え方を定義します。
今回は10回連続で200stepの間倒れなければ学習が十分完了したものと見なして終了します。
class Environment:
def __init__(self):
self.env = gym.make(ENV) # 課題としてCartPoleを設定
self.num_states = self.env.observation_space.shape[0]
self.num_actions = self.env.action_space.n
self.agent = Agent(self.num_states, self.num_actions) # 環境内で行動するエージェントを生成
def run(self):
# 実行
self.complete_episodes = 0
episode_final = False # 最後の試行フラグ
for episode in range(NUM_EPISODES):
# 試行数分繰り返す
observation = self.env.reset() # 環境の初期化
episode_reward = 0 # エピソードでの報酬
# 1エピソードのループ
for step in range(MAX_STEPS):
if episode_final is True:
# framesに各時刻の画像を追加
frames.append(self.env.render(mode="rgb_array"))
action = self.agent.get_action(observation, episode) # 行動を求める
# 行動a_tの実行により、s_{t+1}, r_{t+1}を求める
observation_next, reward_notuse, done, info_notuse = self.env.step(
action
)
# 報酬を与える
if done:
if step < 190:
reward = -1 # 45度傾くか両壁に到達したらペナルティとして報酬-1を与える
self.complete_episodes = 0
else:
reward = 1 # 立ったまま終了時は報酬1を与える
self.complete_episodes = self.complete_episodes + 1
else:
reward = 0
episode_reward += reward # 報酬を追加
# Q関数を更新
self.agent.update_q_function(
observation, action, reward, observation_next
)
# 観測の更新
observation = observation_next
# 終了時の処理
if done:
print(
"{0} Episode: Finished after {1} time steps".format(
episode, step + 1
)
)
break
if episode_final is True:
# GIFを保存と描画
display_frames_as_gif(frames)
break
if self.complete_episodes >= 10:
print("10回連続成功")
frames = []
episode_final = True # 次の試行を描画を行う最終試行とする
実行
cartpole_env = Environment()
cartpole_env.run()
結果
左右の壁に到達したり、倒れたりすることなくバランスを取れていることが分かります。
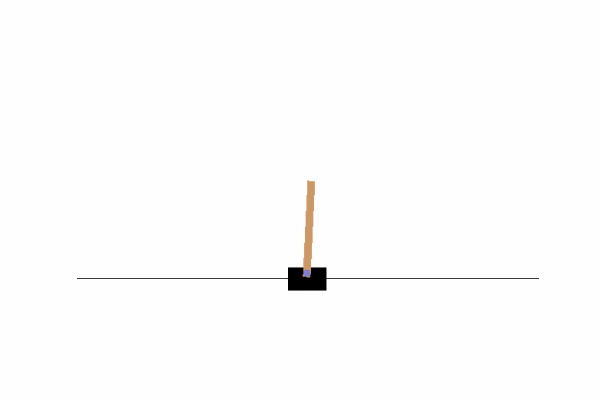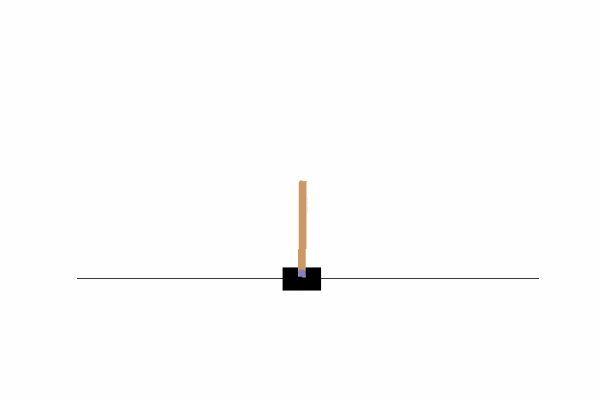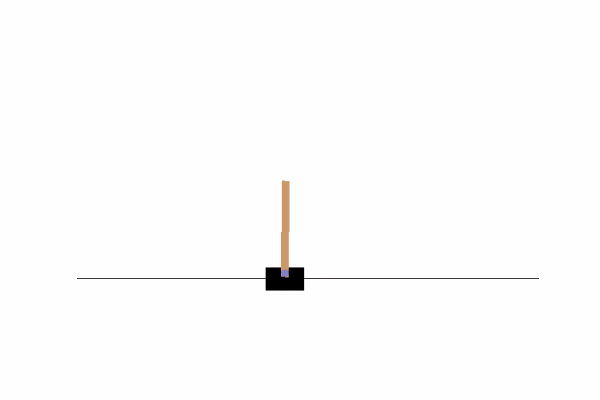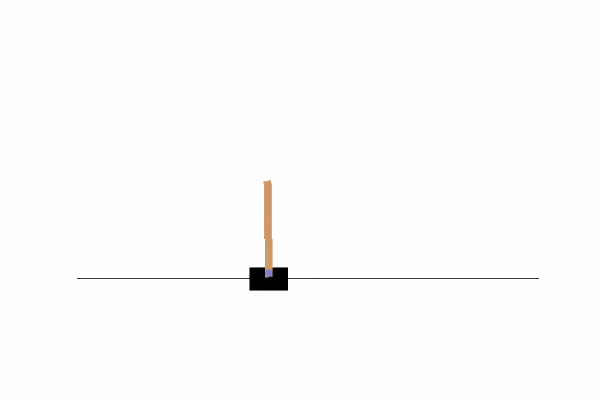
何度か実行してみると学習が完了するまでのエピソード数に思ったよりバラつきがあって面白かったです。
最後に
今年中に技術記事デビューをしようと決めており、ある程度形になっていたところを会社のAdvent Calendarに乗っからせてもらいました。
ブログの類をこれまで全くと言っていいほど書いたことがなく、思いつくままに書き進めたので構成もこんなんで良かったのかなという思いしかないですが、とりあえず書き上げることが出来て良かったです。