はじめに
AWSクラウドデザインパターンとは、AWSを用いたシステムアーキテクチャの設計を行う際に発生する、典型的な問題とそれに対する解決策・設計方法を分類し、ノウハウとして利用できるように整理したものである。
今回は、長期的にサービスを継続していく上で欠かせない、可用性を高めるための5つのパターンをまとめた。
尚、本文中のAWSクラウドコンポーネントの説明は割愛する。
※AWSクラウドコンポーネントに関してはここを参照。
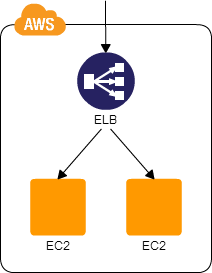
Multi-Server
ロードバランサーを用いて、複数の仮想サーバにトラフィックを分散させる。
特徴
- いずれかのEC2インスタンスに障害が発生しても、システム全体として稼働し続けられる
- 最低稼働台数を設定しておけば仮想サーバに障害が起きても、不足台数を補うように自動的にEC2インスタンスを起動する
注意点
- ELBと複数のEC2インスタンスを利用するため、単一構成よりも費用がかかる
- セッション情報などは複数のEC2インスタンス間で共有できないため、State Sharingパターンを利用する
- 障害時を想定して必要台数+1(1台の予備)構成とする
- データベースの冗長化にはDB Replicationパターンを利用する
- VPC内でもELBを利用できるため、同様に複数の仮想サーバに処理を分散できる
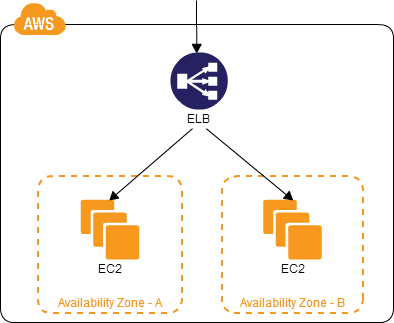
Multi-Datacenter
複数のAZにシステムを構築する。
特徴
- AZレベルの障害が起きても、サービスを継続できる
- ディザスターリカバリー構成を比較的安価で迅速に構築できる
- 単一のAZを利用しても、複数のAZを利用しても費用は変わらない
注意点
- AZ間の通信速度はAZ内よりも遅くなるため、マスタースレーブ構成のDBなどの一方のAZにマスターを配置する場合は注意
- より高い耐障害性の達成には、必要な台数のサーバを各AZに冗長的に配置しなければならない
- リージョンをまたいだ冗長構成はサポートしていない
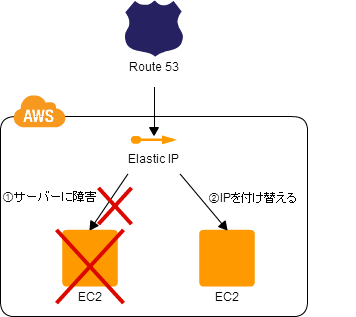
Floating IP
IPアドレスを動的に付け替える。
特徴
- EIPを付け替えるだけなので、DNSのTTLに影響されない
- 切り替え先のサーバでエラーが起きても、即座に元のサーバにEIPを付けることでフォールバックできる
- EIPは複数のAZ間で適応できる
注意点
- EIPの付け替えには数秒程度の時間がかかる
- VPCではサブネットを超えてアドレスを付け替えられない
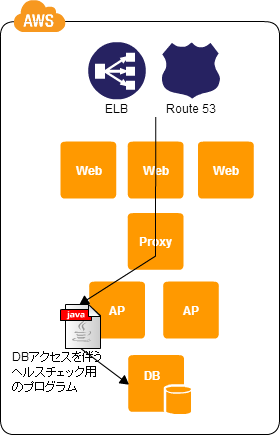
Deep Health Check
システム全体の健全性を確認する。
特徴
- システムの動作に必要なすべてのサーバの状態を確認できる
- ヘルスチェックの応答プログラムによっては閉局処理を行ったり、障害内容によって表示するエラー情報を変更できる
注意点
- ロードバランサー下でオートスケールと組み合わせたAPサーバを配置した場合、APサーバに問題はないのにAPサーバが延々と切り替わってしまうため、Deep Health CheckとAuto Scalingの併用は禁忌事項である
- サーバ台数が多いとヘルスチェック自体が負荷になることがあるので、ヘルスチェックの時間間隔を考慮する
- DBサーバがSPOF(単一障害点)で、そこがダウンするとすべてのサーバが停止するケースがあるため、DB Replicationパターンを併用する
Routing-Based HA
ルーティングによる接続先の切り替え。
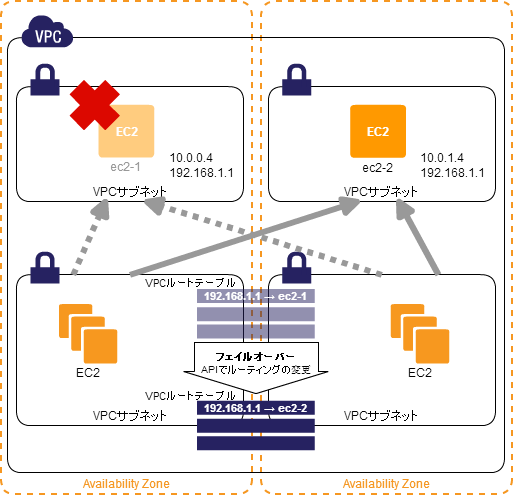
特徴
- AZをまたいだEC2のフェイルオーバーができる
- フェイルオーバーにかかる時間が非常に短い
注意点
- VPCのネットワーク範囲外のIPアドレスを利用するため、VPC/DirectConnect経由/VPCPeeringによるVPC間通信の場合はアクセスできない
- APIを利用するので、インターネットへのアウトバウンド通信が必要になる
- AWSコンソール情報で表示されない、仮想IPアドレスの管理を別途しなければならない
ひとこと
次回は動的コンテンツ処理パターンについてまとめます。
参考
- Amazon Web Services クラウドデザインパターン設計ガイド 改訂版 ( http://amzn.asia/d/flWZUTC )
- AWSクラウドデザインパターン( http://aws.clouddesignpattern.org/ )