論文情報:Hu et al., arXiv, 2024.
リンク:https://arxiv.org/abs/2409.03420
※ 本ページの図は特筆がない限り全て本論文から引用しています。
執筆担当:JINGSエンジニア兼データサイエンティスト 長屋篤典
はじめに
ご覧いただきありがとうございます。
今回は、「mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding」という論文を紹介していきたいと思います。
この論文は、OCRを使わずに複数ページの文書を理解する新しいマルチモーダル大規模言語モデル(MLLM)、『mPLUG-DocOwl2』について説明しています。OCR とは、画像から文字を読み取る技術のことですが、OCR-freeとは、この技術を使わずに画像から直接意味を理解するということです。つまり、この MLLMモデルは、紙の書類をスキャンした画像や、写真に写っている書類などを、人間のように理解することができるのです。
従来の AI モデルでは、高解像度の画像を処理するために、画像を小さな部分に分けて処理していました。しかし、この方法だと、処理に時間がかかったり、多くのコンピュータ資源が必要となったりという問題がありました。
そこで、mPLUG-DocOwl2 では、高解像度DocCompressor という新しい技術が使われています。この技術は、画像を圧縮することで、処理を高速化し、必要なコンピュータ資源を減らすことができます。しかも、画像を圧縮しても、重要な情報が失われないように工夫されています。
mPLUG-DocOwl2 は、従来の AI モデルよりも高い精度と速度で、複数ページの文書を理解することができます。例えば、論文や契約書、請求書などを理解して、必要な情報を抽出したり、質問に答えたりすることができるのです。
この技術は、今後、様々な分野で応用されることが期待されます。例えば、弊社での取り組みが多い製造業では、設計図の作成支援や日報管理に役立てることができます。また、医療機関では、電子カルテの解析やレセプトデータのチェックなどに利用することができます。
このように、mPLUG-DocOwl2 は、私たちの生活をより便利にする可能性を秘めた、画期的な MLLMモデルと言えるでしょう。
高解像度文書画像の処理における課題:従来のMLLMの限界を超えて
近年、マルチモーダル大規模言語モデル (MLLM) は、OCRフリーの文書理解において有望な成果を上げてきました。特に、高解像度文書画像を扱う能力は大きく進歩しています。従来のMLLMは、高解像度画像を多数の小さなサブ画像に分割して処理することで、計算量を抑えていました。しかし、この方法では、膨大な数のビジュアルトークンが生成され、GPU メモリ消費の増加と推論時間の遅延を引き起こすという課題がありました。これは、特に複数ページの文書や動画を扱う場合に深刻な問題となっていました。
従来のMLLMが抱える限界
従来のMLLMにおける高解像度文書画像処理の課題は、以下の点に要約できます。
●ビジュアルトークンの増加による計算コストの増大: 高解像度画像を多数のサブ画像に分割することで、ビジュアルトークンの数が増加し、計算コストが増大します。これは、GPU メモリの使用量増加と処理時間の遅延につながります。
●レイアウト情報の欠損: サブ画像に分割することで、文書全体のレイアウト情報が失われ、テキスト間の関係性を理解することが困難になります。これは、文書理解の精度を低下させる要因となります。
これらの課題を克服するために、mPLUG-DocOwl2と呼ばれる新しいMLLMが提案されました。
mPLUG-DocOwl2:高精度かつ高速なOCRフリー文書理解を実現する革新的なアーキテクチャ
mPLUG-DocOwl2による解決策:高解像度DocCompressorモジュールの導入
mPLUG-DocOwl2は、これらの課題を解決するために、高解像度DocCompressorモジュールを導入しました。このモジュールは、以下の特徴を持ちます。
●レイアウト情報の活用: 低解像度のグローバルな視覚的特徴をガイダンスとして、高解像度文書画像を圧縮します。グローバルな特徴は、文書全体のレイアウト情報を保持しており、DocCompressorはこれを参照することで、テキストの意味的なまとまりを維持しながら圧縮を行います。
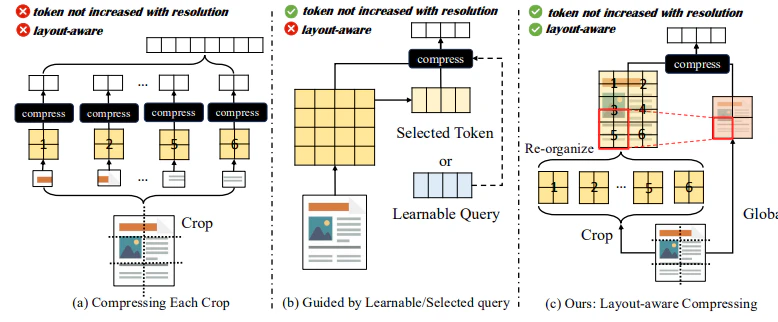
論文Figure2より引用。(c)が提案されている手法であり、ビジュアルトークンの数を削減しながらも、テキスト間の関係性を維持することができます。
●クロスアテンションによる効率的な圧縮: グローバルな特徴をクエリとして、サブ画像の特徴をキーとバリューとして用いるクロスアテンション機構により、高解像度画像を効率的に圧縮します。これにより、ビジュアルトークンの数を大幅に削減することが可能になります。
●324トークンへの圧縮: DocCompressorは、高解像度文書画像をわずか324トークンに圧縮します。これは、一般的なA4サイズの文書ページの詳細なテキスト情報を符号化するのに十分な数であり、GPUメモリ消費と推論時間を大幅に削減します。

論文Figure4から引用。
(a) 性能: DocOwl2と他の最先端マルチモーダル大規模言語モデル (MLLM) を、OCRフリーの性能 (精度) で比較しています。DocOwl2は、ほとんどのベンチマークにおいて、他のモデルと同等以上の精度を達成しています。
(b) 平均ビジュアルトークン数: DocOwl2と他のMLLMを、単一画像あたりの平均ビジュアルトークン数で比較しています。DocOwl2は、他のモデルと比較して、大幅に少ないビジュアルトークン数で高精度を実現しています。
3段階のトレーニングフレームワークによる高精度な文書理解の実現
mPLUG-DocOwl2は、高精度な文書理解を実現するために、以下の3段階のトレーニングフレームワークを採用しています。
1.単一画像事前学習: 大規模な文書画像データセットDocStruct4Mを用いて、画像からテキスト情報やレイアウト情報を抽出する能力を学習します。
2.複数画像継続事前学習: 複数ページの文書を理解するために必要な、ページ間の関係性を学習します。複数ページの文書データセットMP-DocStruct1Mを用いて、指定されたページのテキスト解析や、指定されたテキストを含むページの特定などを行います。
3.複数タスクファインチューニング: DocVQA, InfoVQAなどの単一画像質問応答データセットと、MP-DocVQA, DUDEなどの複数ページ文書質問応答データセットを用いて、質問応答や情報抽出などの様々なタスクを学習します。これにより、汎用的な文書理解能力を獲得します。
DocOwl2の優れたパフォーマンス:様々なベンチマークで最先端の成果を達成
DocOwl2は、様々なベンチマークにおいて、最先端の成果を達成し、OCRフリー文書理解分野に新たな可能性を提示しました。
DocOwl2が達成した具体的な成果
単一画像文書理解ベンチマーク
DocOwl2は、DocVQA、InfoVQA、DeepForm、KLC、WTQ、TabFact、ChartQA、TextVQA、TextCaps、VisualMRCなど、10種類の単一画像文書理解ベンチマークにおいて、従来のMLLMに匹敵するパフォーマンスを達成しました。特筆すべきは、DocOwl2が、従来のモデルと比較して、視覚トークンの数を大幅に削減しながらも、高い精度を維持している点です。これは、高解像度DocCompressorモジュールによる効率的な画像圧縮が、精度の低下を招くことなく、処理速度の向上に貢献していることを示しています。

単一画像文書理解ベンチマークにおけるOCRフリーマルチモーダル大規模言語モデルとの比較:論文Table3より引用。
複数ページ文書理解ベンチマーク
DocOwl2は、MP-DocVQAとDUDEという2つの複数ページ文書理解ベンチマークにおいて、最先端のOCRフリーパフォーマンスを達成しました。さらに、ファーストトークンレイテンシーを50%以上削減することに成功しました。これは、DocOwl2が、複数ページにわたる複雑な文書構造を効率的に理解できることを示しています。
テキストリッチな動画理解ベンチマーク
DocOwl2は、NewsVideoQAベンチマークにおいても、高精度なテキストリッチな動画理解を実現しました。これは、DocOwl2が静止画だけでなく、動画内のテキスト情報も正確に捉え、理解できることを示しています。

複数画像/動画文書理解ベンチマークにおけるOCRフリーマルチモーダル大規模言語モデルとの比較: 論文Table4より引用。
DocOwl2の優れたパフォーマンスの要因
DocOwl2の優れたパフォーマンスは、以下の要因によって実現されています。
●高解像度DocCompressorモジュール: 高解像度文書画像を効率的に圧縮し、ビジュアルトークンの数を大幅に削減することで、高速な処理を可能にします。
●レイアウト重視の圧縮アーキテクチャ: グローバルな低解像度画像からレイアウト情報を取得し、テキストのセマンティックなまとまりを維持しながら圧縮を行うことで、高い精度を維持します。
●3段階のトレーニングフレームワーク: 単一画像と複数画像の両方の理解能力を高め、様々な文書理解タスクに柔軟に対応できるようにします。
今後の将来性:高精度な業務効率化
mPLUG-DocOwl2は、高精度かつ高速なOCRフリー文書理解を実現する革新的なモデルであり、その優れたパフォーマンスは、OCRフリー文書理解分野の進展に大きく貢献すると期待されます。高解像度DocCompressorモジュールと3段階のトレーニングフレームワークの組み合わせは、高解像度文書画像の効率的な処理と高精度な理解を両立させるための、重要なブレークスルーと言えるでしょう。
DocOwl2の登場は、OCRフリー文書理解分野に新たな可能性を拓き、今後、様々な分野での応用が期待されます。はじめに述べたように、製造業や医療業界における業務効率化において文書処理の自動化、情報アクセスの向上など、DocOwl2の技術が社会に広く貢献していく未来が楽しみです。