こんにちは!IBMでSPSS ModelerのTechnical Salesをしている斉藤です。
トランザクションテーブルのデータなどからマスタのデータを参照したい時があります。
しかし双方のデータに結合キーがなく、トランザクションデータのフィールド名がマスタでは値の場合、参照が少々厄介です。
例
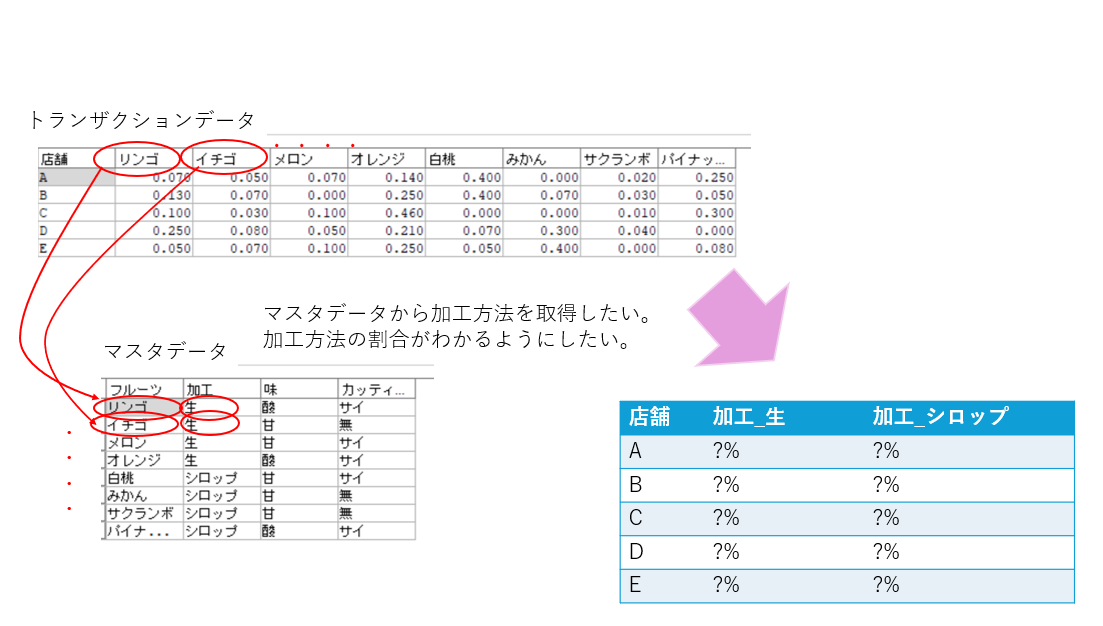
今日はトランザクションデータにマスタのデータをフィールドとして追加する方法をご紹介します。(その後割合まで計算します。)
シナリオ1 フルーツの割合を調べる
全国展開の喫茶店があります。
店舗A~Eは季節ごとに自由にフルーツポンチのフルーツの構成を決めることができます。本店はこの度、レシピを統一すべく、各店舗のフルーツの構成を確認することにしました。
確認したい内容
・フルーツの生、シロップ漬けのバランス
・フルーツの味(酸味と甘み)のバランス
・フルーツのカッティング(カット無し、サイの目)のバランス
データ
・使用率.csv(トランザクションデータ)
・加工マスタ.csv(マスタデータ)
ストリーム解説
使用率.csvには、フルーツの味、加工などの情報が含まれていません。今回はどのようなフルーツでフルーツポンチを構成しているか割合を調べたいので、使用率と加工マスタを結合します。
使用率.csvは店舗がキーになっており、フルーツの名称がフィールドになっているため、このままだとデータの結合が難しい状態です。そこで、「行列入替」ノードを使います。
1. csvをそれぞれ読み込み、行列入替ノードを配置します。使用率.csvを行列入替ノードに接続します。行列入替ノードの行列入替方法は「フィールドからレコードへ」を選択します。

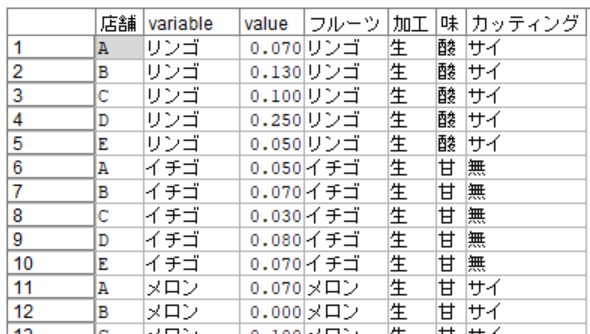
行列入替された結果をテーブルノードで見てみると以下のようにvariableフィールドにフルーツ名が配置されています。

2. 使用率.csvと加工マスタ.csvを接続する
レコード結合ノードを配置し、行列入替した使用率のデータと加工マスタ.csvを接続します。レコード結合方法を「条件」にして「variable =フルーツ」と記載します。これで使用率.csvのレコードに、加工マスタ.csvの情報が結合されます。

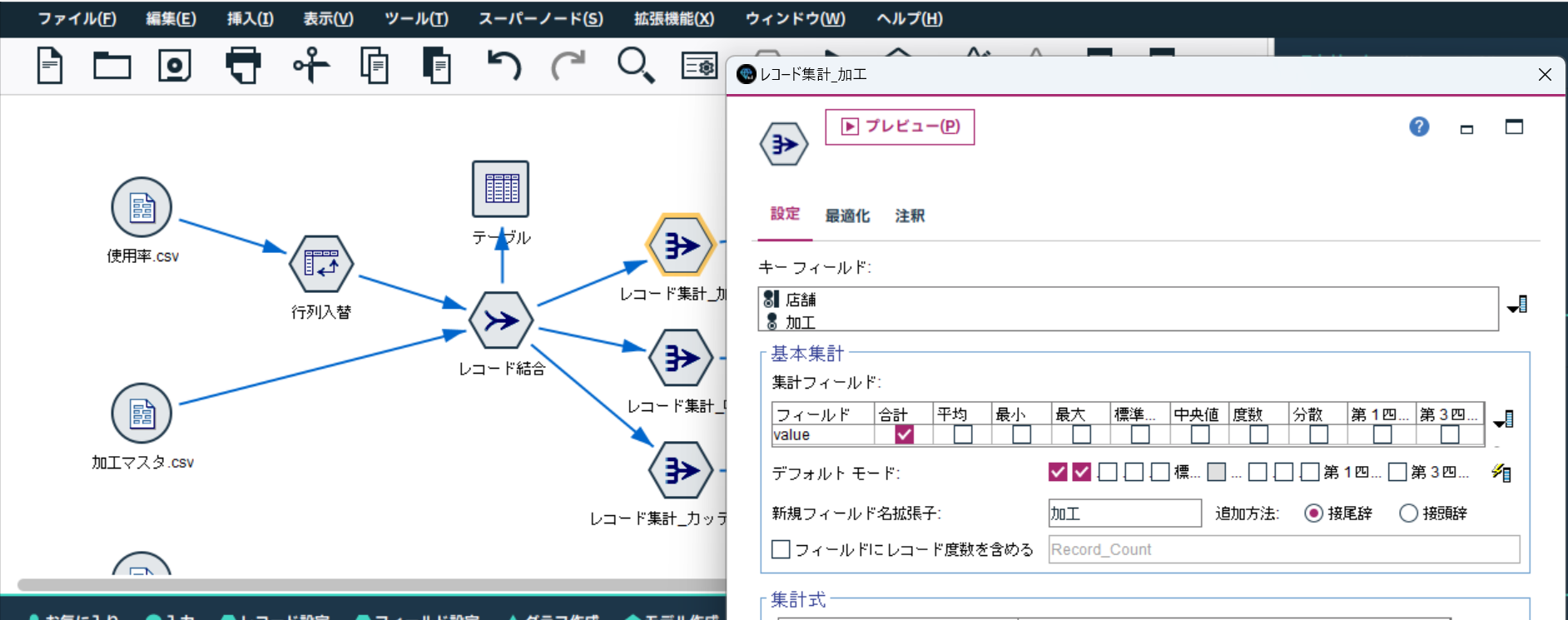
3. 加工の構成割合を確認する
レコード集計ノードを配置し、レコード結合と接続します。レコード集計ノードのキーフィールドは「店舗」と「加工」を選択します。集計フィールド「value」は「合計」を選択します。
この段階で中身を確認してみると以下のように加工(生、シロップ)の割合を確認できます。
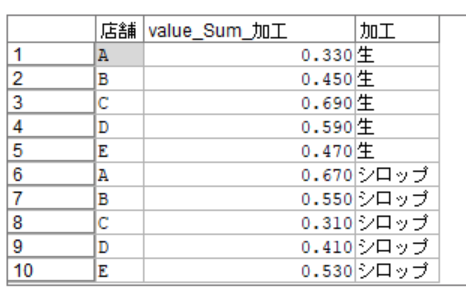
ただこれだと見にくいので、店舗ごと1レコードにしたいと思います。これも行列入替ノードを使います。索引に「店舗」、フィールドに「加工」、値にレコード集計の集計結果をセットします。

このように加工(生、シロップ)の割合を1レコードに表現することができました。

加工の他に味やカッティングも同様の方法で割合を求め、1レコードに表現することができます。

以上「トランザクションデータにマスタのデータをフィールドとして追加する」でした。