OvertureMapsのGERSIDが25年6月よりGA ということで、公式チュートリアルを使ってデータを見てみました。
Overture Maps Foundation が提供する公式チュートリアルに沿って、ローカルの施設データと Overture の places データをマッチングしてみました。SQL(DuckDB)だけで処理が完結するうえ、最終的には QGIS で視覚的に結果を確認するところまでできたので、その過程を簡単にまとめます。
この記事は、Overture Maps が提供する 公式チュートリアル の実施記録です。
✅ チュートリアルの流れ(ざっくり)
チュートリアルは大きく分けて以下の3ステップで構成されていました:
- Overture のデータとローカル施設データのマッチング
inspectionsテーブルへの GERS ID の付与- 施設の変更情報(削除・編集など)の可視化
すべて DuckDB と SQL だけで完結します。
🔧 データの準備とマッチング
1. ローカル施設データ(California)の読み込み
チュートリアルでは、California の施設サンプルデータとして以下のデータを利用します。
Alameda County’s restaurant inspection reports
GeoJsonのデータを利用し、データセットをDuckDBでステージングします。
$ duckdb inspection_match.ddb
DuckDBの空間プラグインとhttpfsプラグインをロードし、ローカルテーブルにロードします。
D install spatial;
D load spatial;
D install httpfs;
D load httpfs;
CREATE TABLE IF NOT EXISTS inspections AS SELECT * FROM ST_Read('inspection_records.geojson');
地点ごとに複数のデータがあり、各地点をOvertureのPlaceに合わせたいので、施設ごとに別のテーブルを作成します。
CREATE TABLE IF NOT EXISTS facilities AS
SELECT Facility_ID, Facility_Name, Address, City, State, Zip, geom
FROM inspections
GROUP BY Facility_ID, Facility_Name, Address, City, State, Zip, geom;
ここから後のマッチングプロセスは複雑になる可能性があるため、結合の前に、必要なOvertureデータをローカルテーブルにロードします。(次項)
2. Overture の Place データの取得
次に、Overture Maps の Place データ(Parquet形式)を読み込みます。ローカル施設の緯度経度からバウンディングボックスを作成し、対象エリアだけを読み込む形にしています。
CREATE TABLE IF NOT EXISTS places AS
WITH bounding_box AS (
SELECT max(ST_Y(geom)) as max_lat,
min(ST_Y(geom)) as min_lat,
max(ST_X(geom)) as max_lon,
min(ST_X(geom)) as min_lon
FROM facilities
)
SELECT
id,
upper(names['primary']) as Facility_Name,
upper(addresses[1]['freeform']) as Address,
upper(addresses[1]['locality']) as City,
upper(addresses[1]['region']) as State,
left(addresses[1]['postcode'], 5) as Zip,
geometry as geom,
categories,
confidence
FROM (
SELECT *
FROM read_parquet('s3://overturemaps-us-west-2/release/2025-04-23.0/theme=places/type=place/*', filename=true, hive_partitioning=1),
bounding_box
WHERE addresses[1] IS NOT NULL
AND bbox.xmin BETWEEN (bounding_box.min_lon - 0.01) AND (bounding_box.max_lon + 0.01)
AND bbox.ymin BETWEEN (bounding_box.min_lat - 0.01) AND (bounding_box.max_lat + 0.01)
);
今後の処理のため空間INDEXを追加しておきます
CREATE INDEX IF NOT EXISTS idx_places_geometry ON places USING RTREE (geom);
CREATE INDEX IF NOT EXISTS idx_facilities_geometry ON facilities USING RTREE (geom);
3. 類似施設とのマッチングと GERS ID の付与
- 文字列類似度には
jaro_winkler_similarityを使用 - 距離は
ST_DWithinとST_Distance_Sphereで制限 - 類似スコアの高い施設を
ROW_NUMBER()でランク付けし、最もスコアが高いものを 1 件だけ採用
まず、非常に緩いしきい値を持つ3つの条件を使用して結合を作成します
SELECT
f.Facility_ID as input_id,
f.Facility_Name as input_name,
f.Address as input_address,
p.id as match_id,
p.Facility_Name as match_name,
p.Address as match_address,
p.confidence as overture_confidence,
ST_Distance_Sphere(f.geom, p.geom) as distance,
jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) as name_similarity,
jaro_winkler_similarity(f.Address, p.Address) as address_similarity
FROM facilities f
JOIN places p
ON ST_DWithin(f.geom, p.geom, 0.001)
AND jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) > 0.7
AND jaro_winkler_similarity(f.Address, p.Address) > 0.8
ORDER BY f.Facility_ID, distance;
チュートリアルでは距離と名前、住所の一致性を一定基準設けてマッチングをかけます。
WITH ranked_matches AS (
SELECT
f.Facility_ID as input_id,
f.Facility_Name as input_name,
f.Address as input_address,
p.id as match_id,
p.Facility_Name as match_name,
p.Address as match_address,
p.confidence as overture_confidence,
ST_Distance_Sphere(f.geom, p.geom) as distance,
jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) as name_similarity,
jaro_winkler_similarity(f.Address, p.Address) as address_similarity,
ROW_NUMBER() OVER (
PARTITION BY f.Facility_ID
ORDER BY jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) DESC
) as rank
FROM facilities f
JOIN places p
ON ST_DWithin(f.geom, p.geom, 0.001)
AND jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) > 0.89
AND jaro_winkler_similarity(f.Address, p.Address) > 0.75
)
SELECT * FROM ranked_matches WHERE rank = 1
ここまで調整した状態で、gers_idという名前のfacilitiesテーブルに列を追加し、結合クエリを実行します。
ALTER TABLE inspections ADD COLUMN geometry VARCHAR;
ALTER TABLE inspections ADD COLUMN gers_id VARCHAR;
WITH ranked_matches AS (
SELECT
f.Facility_ID as input_id,
f.Facility_Name as input_name,
f.Address as input_address,
p.id as match_id,
p.Facility_Name as match_name,
p.Address as match_address,
p.confidence as overture_confidence,
ST_Distance_Sphere(f.geom, p.geom) as distance,
jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) as name_similarity,
jaro_winkler_similarity(f.Address, p.Address) as address_similarity,
ROW_NUMBER() OVER (
PARTITION BY f.Facility_ID
ORDER BY jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) DESC
) as rank
FROM facilities f
JOIN places p
ON ST_DWithin(f.geom, p.geom, 0.001)
AND jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) > 0.89
AND jaro_winkler_similarity(f.Address, p.Address) > 0.75
),
selected_matches AS (
SELECT input_id, match_id FROM ranked_matches WHERE rank = 1
)
UPDATE inspections i SET gers_id = sm.match_id FROM selected_matches sm WHERE i.Facility_ID = sm.input_id;
ここでマッチングが完成しました。
チュートリアルでは、さらに以下クエリで中間テーブルを作成しています。
SELECT Facility_ID, gers_id FROM inspections WHERE gers_id IS NOT NULL GROUP BY Facility_ID, gers_id;
Facility_ID,gers_id
FA0319719,08f28346e8ca018503160340e65ac7b6
FA0319719,08f28346e8ca018503160340e65ac7b6
FA0319719,08f28346e8ca018503160340e65ac7b6
FA0002404,08f283098d6527200394e5ac0b19dbf5
FA0002404,08f283098d6527200394e5ac0b19dbf5
📊 マッチングの成果
チュートリアルでは「907件の施設がマッチし、結果的に2,358件の GERS ID が付与された」と紹介されています。自分の環境でもほぼ同様の結果となりました。(ちょっとだけ違った・・・)
SELECT COUNT(DISTINCT Facility_ID)
FROM inspections
WHERE gers_id IS NOT NULL;
┌───────────────┐
│ total_matched │
│ int64 │
├───────────────┤
│ 2360 │
└───────────────┘
🔄 施設の変更情報を取得する
差分データをテーブルにキャッシュし、バウンディングボックスで(同様に)取得します
CREATE TABLE IF NOT EXISTS changes AS
WITH bounding_box AS (
SELECT max(ST_Y(geom)) as max_lat, min(ST_Y(geom)) as min_lat, max(ST_X(geom)) as max_lon, min(ST_X(geom)) as min_lon
FROM facilities
)
SELECT
*
FROM (
SELECT id, bbox, filename, change_type, theme
FROM read_parquet('s3://overturemaps-us-west-2/changelog/2025-03-19.1/theme=places/type=place/change_type=*/*', filename=true, hive_partitioning=1),
bounding_box
WHERE
bbox.xmin BETWEEN (bounding_box.min_lon - 0.01) AND (bounding_box.max_lon + 0.01) AND
bbox.ymin BETWEEN (bounding_box.min_lat - 0.01) AND (bounding_box.max_lat + 0.01)
);
リリース日付により変わる可能性があるので取得先は調整してください。
既存テーブルとJOINすることでIDベースでの変化情報をテーブルに取り込めます。
SELECT Facility_ID, gers_id, change_type FROM inspections i
JOIN changes c
ON i.gers_id = c.id
GROUP BY Facility_ID, gers_id, change_type;
さらに一致しないレコードを最新のリリースに照合します。
DROP TABLE places;
CREATE TABLE places AS
WITH bounding_box AS (
SELECT max(ST_Y(geom)) as max_lat, min(ST_Y(geom)) as min_lat, max(ST_X(geom)) as max_lon, min(ST_X(geom)) as min_lon
FROM facilities
)
SELECT
id,
upper(names['primary']) as Facility_Name,
upper(addresses[1]['freeform']) as Address,
upper(addresses[1]['locality']) as City,
upper(addresses[1]['region']) as State,
left(addresses[1]['postcode'], 5) as Zip,
geometry as geom,
confidence,
categories
FROM (
SELECT *
FROM read_parquet('s3://overturemaps-us-west-2/release/2025-04-23.0/theme=places/type=place/*', filename=true, hive_partitioning=1),
bounding_box
WHERE addresses[1] IS NOT NULL AND
bbox.xmin BETWEEN (bounding_box.min_lon - 0.01) AND (bounding_box.max_lon + 0.01) AND
bbox.ymin BETWEEN (bounding_box.min_lat - 0.01) AND (bounding_box.max_lat + 0.01) AND
confidence > 0.3
);
CREATE INDEX IF NOT EXISTS idx_places_geometry ON places USING RTREE (geom);
最後にmatchilitiesfacilities_to_matchの施設のみに制限して、マッチクエリを再度実行します。
WITH ranked_matches AS (
SELECT
f.Facility_ID as input_id,
f.Facility_Name as input_name,
f.Address as input_address,
p.id as match_id,
p.Facility_Name as match_name,
p.Address as match_address,
p.confidence as overture_confidence,
ST_Distance_Sphere(f.geom, p.geom) as distance,
jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) as name_similarity,
jaro_winkler_similarity(f.Address, p.Address) as address_similarity,
ROW_NUMBER() OVER (
PARTITION BY f.Facility_ID
ORDER BY jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) DESC
) as rank
FROM facilities f
JOIN places p
ON ST_DWithin(f.geom, p.geom, 0.001)
AND jaro_winkler_similarity(f.Facility_Name, p.Facility_Name) > 0.89
AND jaro_winkler_similarity(f.Address, p.Address) > 0.75
WHERE f.Facility_ID IN (SELECT Facility_ID FROM facilities_to_match)
),
selected_matches AS (
SELECT input_id, match_id FROM ranked_matches WHERE rank = 1
)
UPDATE inspections i SET gers_id = sm.match_id FROM selected_matches sm WHERE i.Facility_ID = sm.input_id;
ここまでくると、Overture の差分データセット(changes)を使って、削除・変更された施設の情報を GERS ID 経由で特定できます。
SELECT Facility_ID, gers_id, change_type FROM inspections i
LEFT JOIN changes c
ON i.gers_id = c.id
WHERE change_type IS NULL OR change_type IN ['removed', 'data_changed']
GROUP BY Facility_ID, gers_id, change_type;
🗺 QGISでの表示例
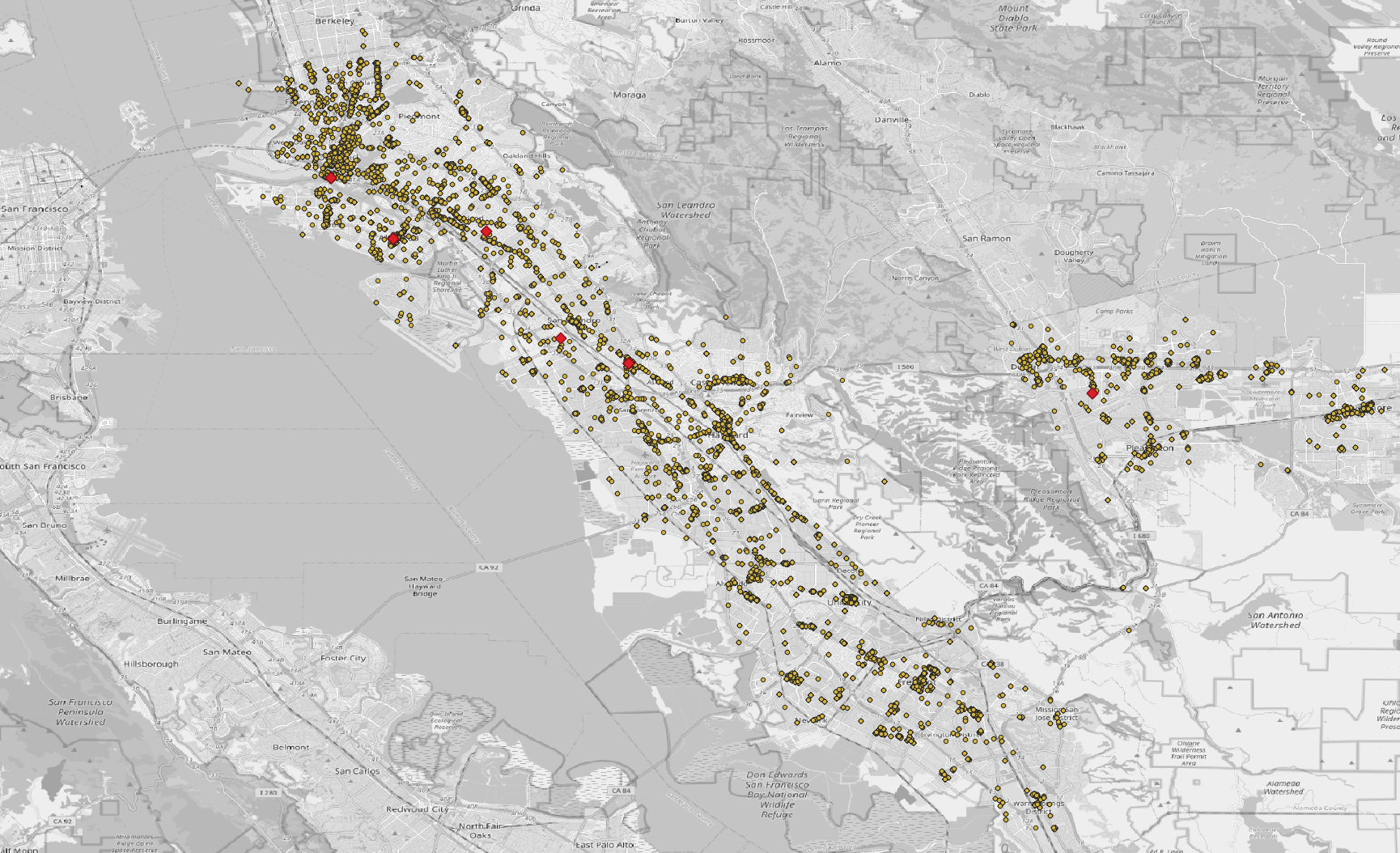
例えば、このデータを CSV にして QGIS に読み込めば、変化のあった施設を地図上で視覚的に確認できます。
以下は QGIS で表示した例です。削除された施設を赤で重ねており、データの差分が視覚的に確認できます。
背景地図: OpenStreetMap
🧭 GERS ID の意義(チュートリアルより)
GERS ID(Global Entity Reference System ID) は、Overture Maps が提唱するグローバル一意識別子です。
チュートリアル内でも、以下のようなメリットが示されています:
- 異なるデータソース間での施設の一意な照合が可能
- 長期的な施設の追跡(変化、移転、削除など)ができる
- 安定した ID によって更新データの統合が容易
地理空間データを ID ベースで結び付けられることで、より柔軟な分析やアプリケーション連携が期待できます。
✍ 感想とまとめ
- DuckDB の空間関数と文字列類似度の組み合わせだけで施設マッチングが完結するのは便利
- GERS ID によるデータ統合は、今後の差分管理やマルチソース連携に非常に役立ちそう
- 今回は Place データでの検証だが、道路など他のテーマでも応用可能なはず
- Overture の公開データ自体の精度・カバレッジの検証も必要そう
SQL+QGIS の軽量ワークフローで完結できる点がとても印象的で、プロトタイピングや実証実験のベースとして参考になると感じました。