この記事では Confident Learning についてかんたんな解説を書きます。後日リライトされたバージョンがきっと別の場所に投稿されると思います。
スライドはこちらにあります。
要約
- Confident Learning はデータの分類エラーを発見するための手法
- MNIST や ImageNet などのデータセットに適用し、実際に誤りを発見
- 実際のデータセットに適用し、誤りを発見できた
背景
かつてヒントン先生 (Geoffrey Hinton)は盟友ルカン先生にこう宣言しました。「いつか君のデータセットのミスを見つけてやる」と。
そしてそれは実際に実行されました。ミスを見つけたヒントン先生はとても喜んでいたようです。
そしてそれを見ていた一人のインターン生(当時)がいました。彼はこう考えたそうです。
「ヒントン先生ほどの方がたった1件見つけただけでこんなに喜ぶのなら、データの誤りを見つけることは大きな価値があるんじゃないか?」
その結果できあがったのがデータの誤りを見つけるためのアルゴリズムである Confident Learning とその実装である Cleanlab です。
Confident Learning の結果
Confident Learning はいくつかのアルゴリズムを含んでいます。
- ラベルが誤っていそうなデータの抽出
- ラベルの擬似的な修正と、修正したデータに基づく機械学習モデルの作成
この記事では前者のみを扱います。というのも、実用上は前者が重要であることと、後者は興味深い話題ではあるのですが、実用上、解決が非情に困難な問題を含んでいるためです。
仮にデータの誤りが含まれていることが既知だったとしましょう。そして、それを擬似的に修正した結果、モデルの精度指標が向上したとしましょう。しかし、その精度は妥当なのでしょうか?
精度を測定するための基本的な方法は、ラベルと推論結果の比較です。ラベルのつけられたテスト用のデータセットを用意し、そのデータセットに対してモデルが推論した結果と比較するのですが、ラベルは正しくないことがわかっています。誤りが含まれるラベルに一致している度合いを議論することは不毛です。
また、この場合に「誤りが含まれないテストデータセット」の存在を仮定することも現実的ではありません。もしそのようなデータセットが作成可能であれば、ラベルの誤りが含まれないようにデータセットを再作成すればよいでしょう。しかし、アノテーションを人手で行っている場合には「誤りのない」というのを保証するのは困難ですし、もしそのようなアノテーション作業が効率的に行われるのならば、機械学習の出番はないでしょう。
少し前置きが長くなりましたが、Confident Learning で発見されたラベルのエラーを集めたサイトが公開されています。
Dataset を変えることで MNIST や ImageNet などさまざまなデータセットに含まれるラベルの誤りを閲覧できます。パット見てわかりやすいのは MNIST でしょう。
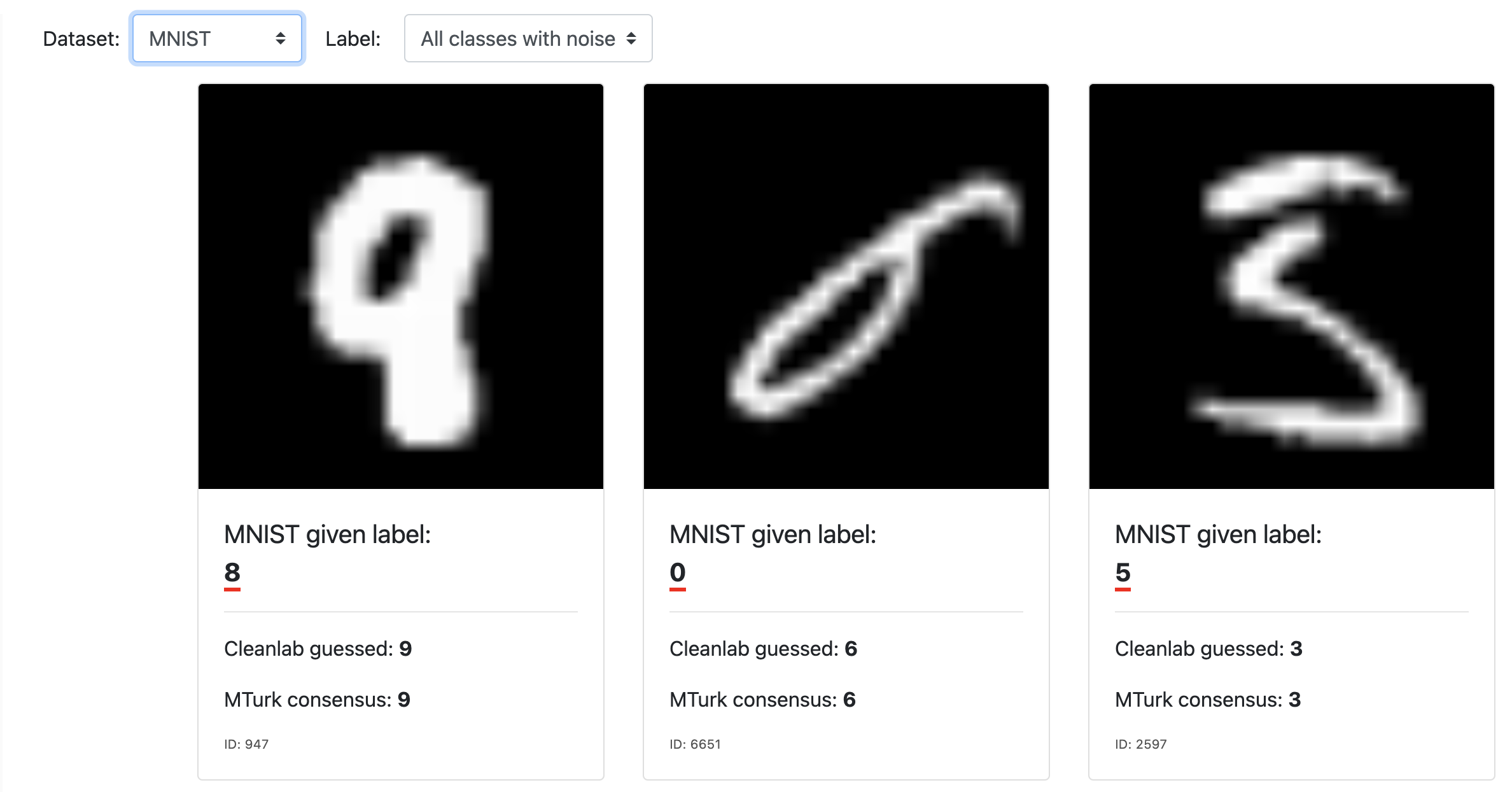
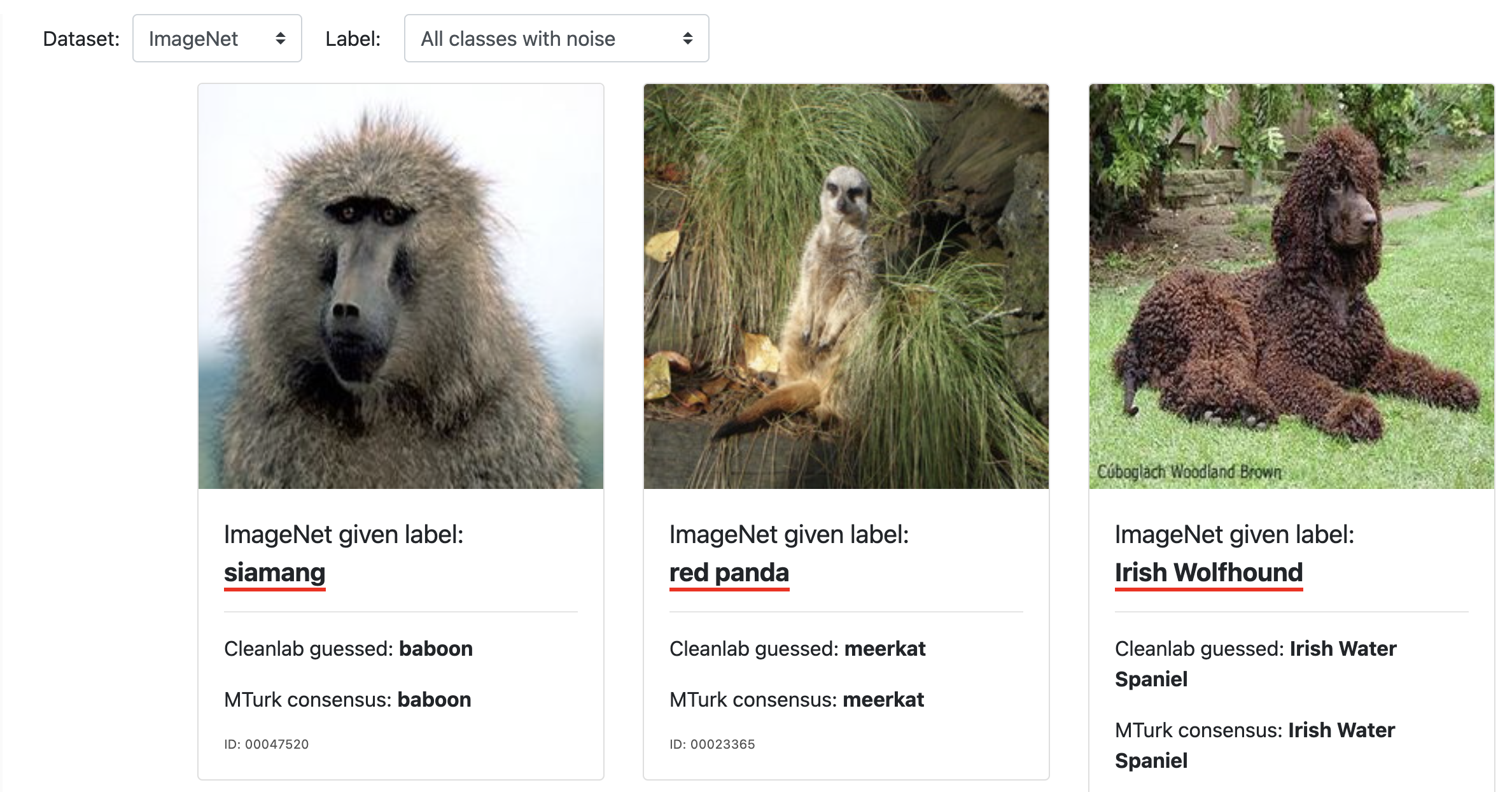
一方、表示を ImageNet に切り替えるとぱっと見ただけでは真偽がわかりませんぱっと見てわかる誤りも含まれていますが (バブーンをシャーマンと誤っている) 右側の犬種は何が正しいのかは筆者にはわかりませんでした。
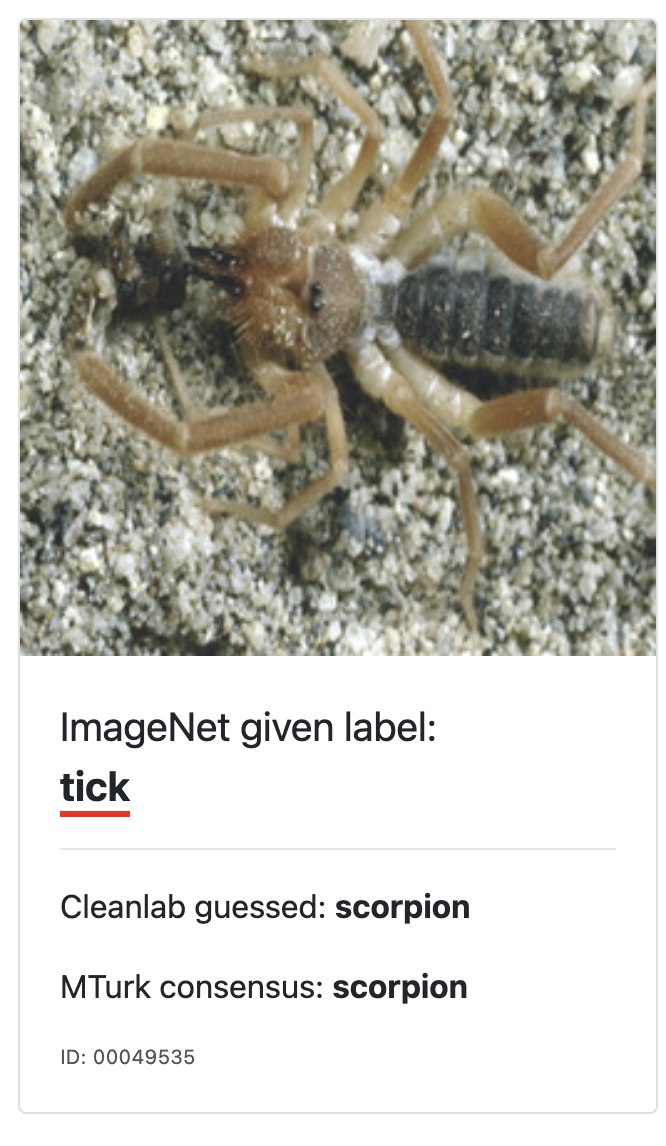
また、この中には修正後のラベルですら誤っているものも含まれています。これは tick (ダニ) とラベル付けされた画像で、scorpion (サソリ) と修正されていますが、実際は Solifugae (ヒヨケムシ) でありどちらも誤っています。
ではこのデータセットはどのように作られたのでしょうか。次はそれを見ていきましょう。
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
データのラベルの修正については論文 Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks で詳細が述べられています。
ここではアルゴリズムの詳細には立ち入りませんが、次のようにして修正がなされています。
- Confident Learning を用いたラベルの誤りの候補の抽出
- Amazon Mechanical Turk を用いて再ラベリング
- 2つのラベルが一致した/一致していないを再度精査し、誤りの率を算出
このワークフローにより MNIST では 0.15 % のデータのエラーが、ImageNet では 5.83 % のデータのエラーが検出されました。
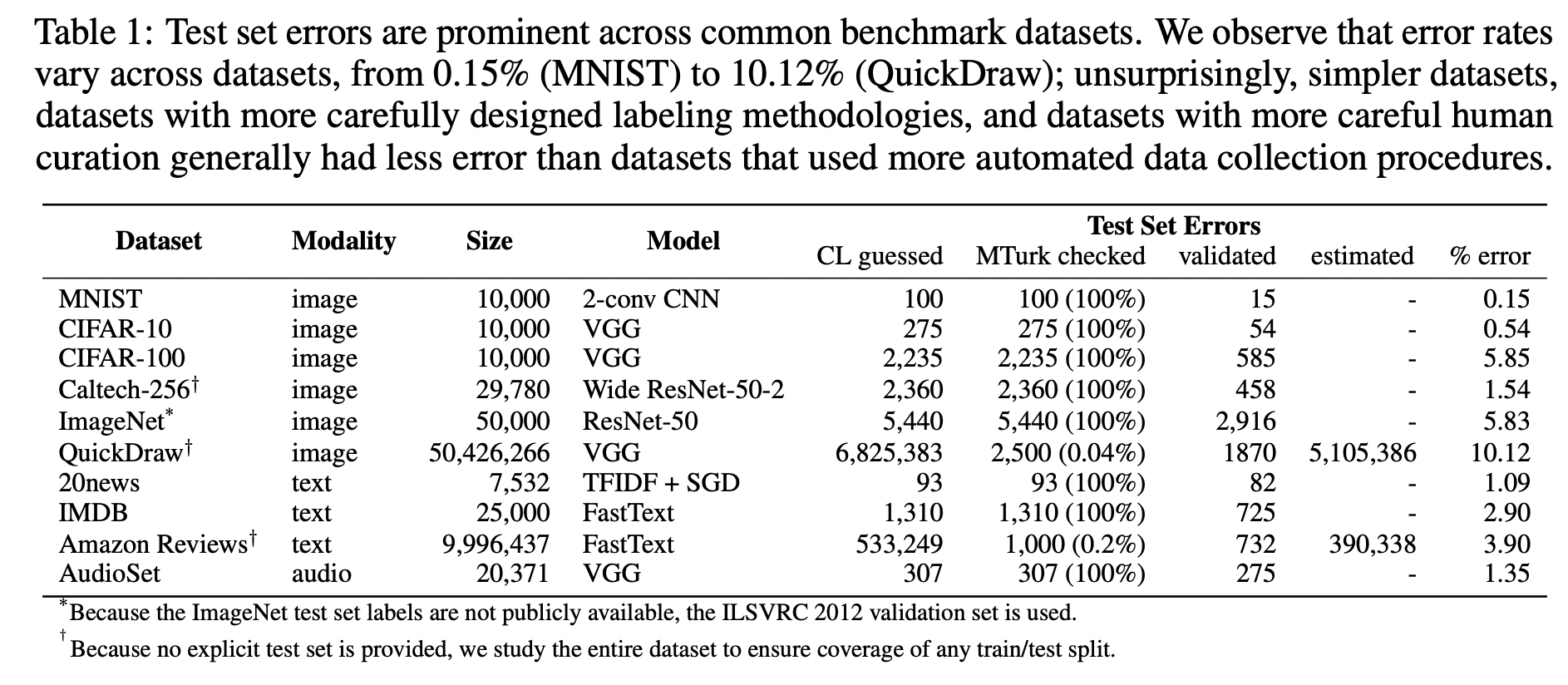
アルゴリズムの詳細の解説はまた別の機会にしたいと思います。
実際に使ってみた感想
この Confident Learning について実際に使ってみる機会に恵まれたので、現在開示できる範囲で結果について記します。
問題設定
医療画像の分類 (疾病の有無を判定するタスク) において、次のような状況が生じました。
- 専門家が画像を分類 (異常なし or 疾病あり)
- 分類結果に基づき、画像認識モデルを作成
- 作製した画像認識モデルの評価結果を専門家がレビュー
- モデルが誤ったテストデータを専門家が再確認したところ、ラベルが間違っていたケースが発見された
このデータセットについては医療分野であったことから、高い品質が求められます。このため、データセットに含まれている誤りはできる限り修正すべきです。また、完全な修正がこんなんだとしても、誤りの割合が許容可能かどうか見積もりが必要です。
また、疾病の有無について判断するためには高い専門性が必要です。機械学習モデルを作製したエンジニアが画像を確認したのですが、疾病の有無を判断することは困難でした。加えて、専門的なトレーニングを受けていない人間が疾病の有無を判断すること自体がまた問題となります。
上記の課題で困っているという相談を受けたので、その解決のために Confident Learning を適用しました。
結果
利用した結果は次のとおりです。
| 種別 | 枚数 | 割合 |
|---|---|---|
| 全画像 | 4,000枚 | 100% |
| Confident Learning により抽出した画像 | 250 枚 | 6.25 % |
| 再レビューの結果、修正された件数 | 40 枚 | 1 % |
もともとは「どれだけの誤りが含まれているのかまったく見積もりができない」という状況でしたが、概ね 1 % 程度だと見積もられました。
考察
最後に、Confident Learning の試行を通じて見えてきたデータの品質に関する話題についていくつか述べます。
まず、アノテーション作業の専門性の高さについて述べます。ImageNet の例を見るだけでもわかりますが、「画像を分類する」というタスクは予想以上に複雑なタスクです。対象領域についての深い知識が必要とされるため、アノテーターはその領域の専門家が行う他ないでしょう。アノテーションはクラウドソーシングが有名ですが、今後内製化が進むと思われます。
次に、アノテーションをスケールさせることの困難さについて述べます。そもそもルールでの記述が難しい領域について取り組んでいるため、判断に迷うデータについてもアノテーションを行う必要があります。
ひとりで取り組んでいるなら一貫した判断を下せるかもしれませんが、要求されるデータセットの件数は数万件になることも珍しくありません。必然的に作業を行うためのチームの編成が必要です。チームの全員が一貫したアノテーションを行えるようにチームを運営することは大きなチャレンジでしょう。
最後に、効率的にアノテーションを行うためのツールはまだまだ不足しています。OSS や大手クラウドサービスプロバイダーが提供しているツールもありますが、まだまだ未開拓な部分は大きいと感じています。
最後に
機械学習の適用事例は枚挙にいとまがないありません。アルゴリズム部分については華々しい成果が喧伝されますが、データセットの作成におけるさまざまな課題についてはまだまだ共有がされていないように感じています。
3年前の記事ですが「失敗から学ぶ機械学習応用~Another Story~」から得られることは依然として大きいように思います。このような事例の収集と共有について今後数年書けて取り組んでいきたいと思います。