tl;dr
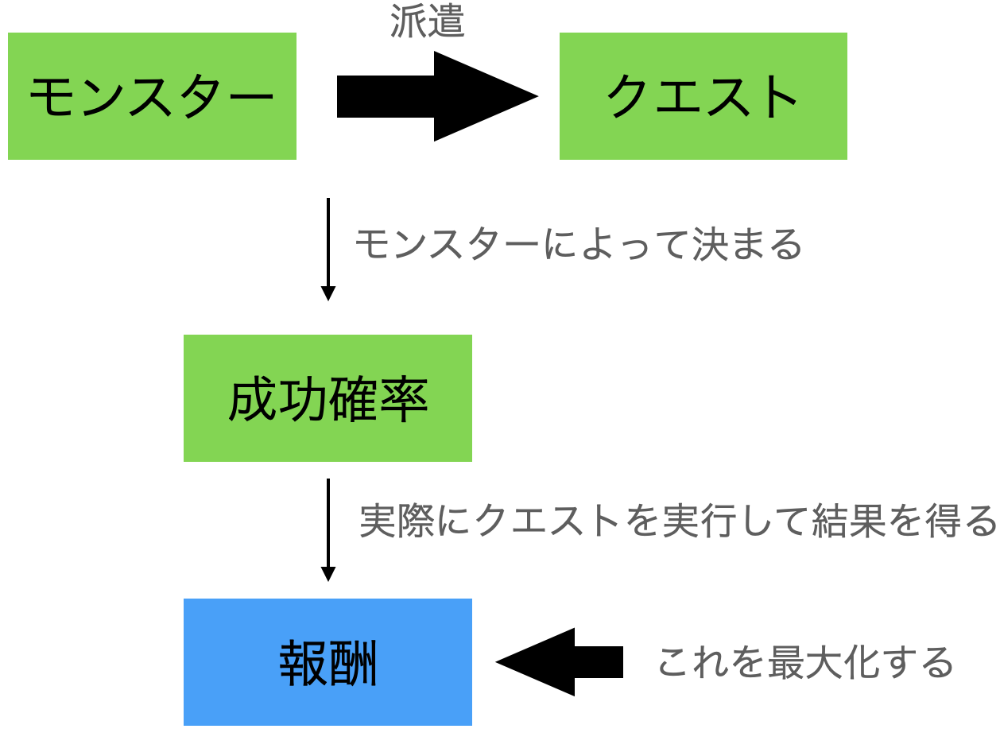
Sdoricaのモンスター探索のクイック編成機能が最良ではなさそうなので自分で最適化のスクリプトを作って検証しました。
クエスト成功確率の計算を目的関数として再現し、貪欲法+乱択で最適化をおこないました。その結果、クイック編成を用いて得られるアイテムの利得を上回る結果が得られました。
あとGurobiを用いた検証も行いましたが、クエスト成功確率の計算を入れ込むことに挫折しました。
execuse
この記事はソルバーを貶めるためのものではないのでご理解ください。
間違った記述や理解をしているところはありますが、そこはひとえに記事主の不勉強が原因なので、
何か参考にされる場合はこの記事の内容を鵜呑みにせず、しっかりと調べた上で検証してください。
初めに
Sdoricaについて
詳しくはWikipedia見てください。
モンスター探索の位置付け
メインのストーリーなどもあるのですが、モンスター探索はメイン部分に特に大きな影響を及ぼすことはありません。
探索の中の一機能として存在し、探索の中で使用できるアイテムと、ガチャのための石やゲーム内通貨が得られます。
なので、面倒ですがガチャ石のために頑張った方が得であり、それを効率化したいというわけです。
モンスター探索の仕組み

この中でたき火を選ぶと

このようにモンスターを派遣できるクエストの一覧が表示されます。
1日ごとに17種類のクエストを実行することができ、それぞれのクエストは3~6種類の似たような内容のクエストからランダムで選ばれます。
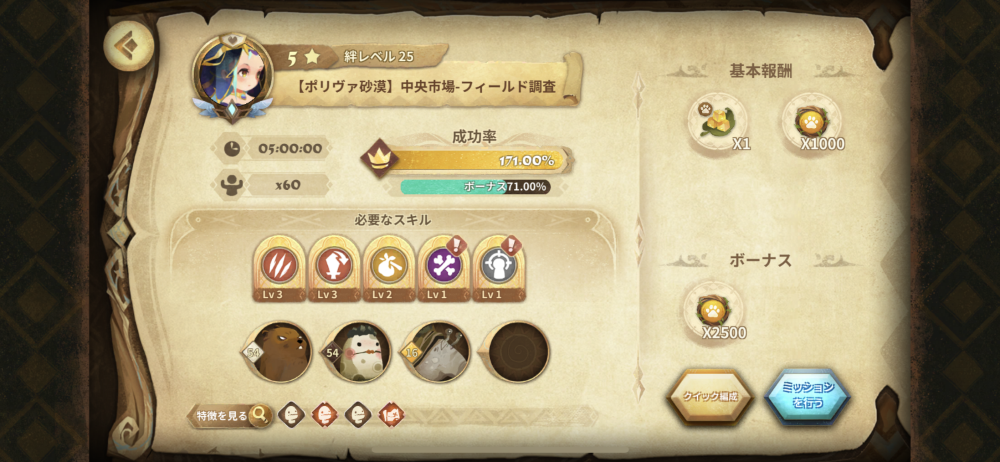
クエストの詳細からどのモンスターと、どのキャラクターを派遣するかを選んでミッションを行うを実行します。

モンスターにはこのようにステータスが存在し、以下の要素があります。
- 赤: レベル。モンスターをクエストに派遣し、経験値アイテムを入手することによって上昇する
- 紫: 種族。これにより色、スキル1,2の内容が決まる。スキル3,4にもモンスターによって大まかな法則がある
- 水: ランク。1~9まで現状存在し、スキルのレベルに影響する
- 青: 色。金、黒、白があり、スキルによるクエスト成功率に影響する
- 黄: スキル。4種類あり、前半二つはクエスト派遣のために必要なスキル。後半二つは成功率上昇や、クエストにかかる時間の短縮などサブの役目がある
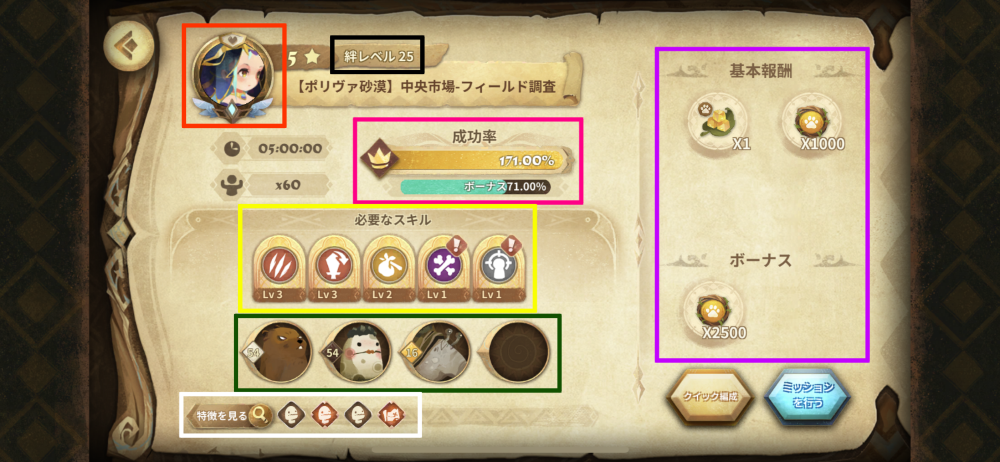
一方クエスト画面の意味はこんな感じ
- 赤: 派遣されるキャラクター。キャラクター自体よりもキャラの色が重要。金、黒、白があり、クエストごとに色は固定なのであまり考慮する必要がない
- 黒: 絆レベル。派遣されるモンスターがこのレベルに達していないと成功率が下がる
- 紫: 成功率。モンスターを派遣した時のスキルによってこの値が上昇する
- 青: 報酬。基本報酬が
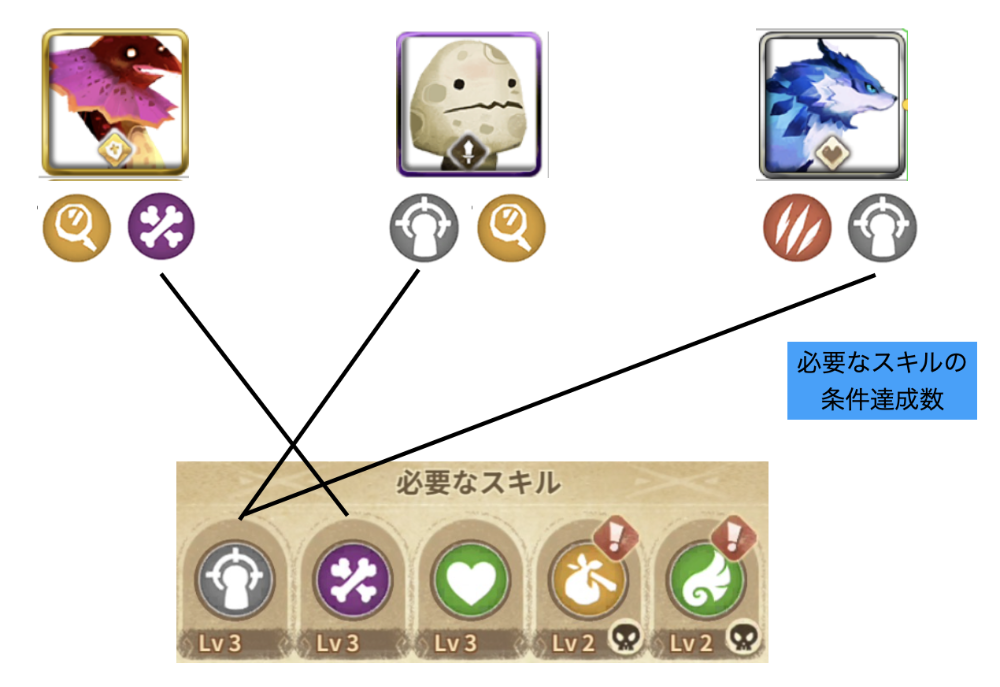
min(100,[成功率])%で入手でき、ボーナスがmin(100,[成功率]-100)%で入手できる。2本あるゲージの上が基本報酬の確率、下がボーナスの確率と考えるとわかりやすい - 黄: 必要なスキル。モンスターが対応するアイコンのスキルを持っていると明るくなり、レベルに対応した成功率が追加される。全てを埋める必要はないが、右上に
!がついているスキルは必須スキルであり、これを埋めていないと必ず成功率が0%になる - 緑: モンスター。派遣されるモンスターであり、4体まで選べる
- 白: スキル
今回の目的である報酬の最大化のためには、うまいことクエスト成功率を上げてやる必要があります。要素としては
- スキル1,2での確率上昇
- クエスト、レベルである程度上昇量が決まっている
- スキル3,4での確率上昇
- [前中後]衞: 参加 キャラクター(画像上の方にあるハート)に対応して上昇
- [前中後]衞小隊: 参加 モンスター(画面下部にある4つ)の色に対応して上昇
- フィールド: 【ポリヴァ砂漠】などのようにクエストのフィールドに対応して上昇
- いぶし銀: 無条件に確率上昇
- モンスターのレベル
- 絆レベルに足りていない場合、足りなかった分のレベル%だけ成功率が低下する
今回行うこと
クイック編成という自動で派遣するモンスターを選ぶ機能もあるが、選択できるモンスターを用いた時の最大の成功率にならず、
精度がイマイチなので総合的に最適な組み合わせを見つけ、最終的に得られる報酬の価値を最大化すること。
用語の定義
- クエスト: モンスターを派遣して報酬を得るもの。ゲーム内ではミッションと書かれていますが紛らわしいのでクエストにします
- モンスター: 派遣されるもの
- キャラクター: ゲーム本編で出てくる知的生命体。クエストに対して十分な数おり、キャラクターのレベルも十分であればあまり問題にならないので今回はほぼ無視する
- 技能: スキル1,2のこと。長いので略します
- スキル: スキル3,4のこと。
- 地域: 6種類あり、モンスターのフィールド関係のスキルに影響してきます
- アイテム: クエストで得られる報酬です
- (クエスト)成功確率: クエストで得られる報酬に影響する数値
- アイテムの重み: プレイヤーがどれだけそれぞれのアイテムを重要に思っているか(例: ガチャ石は大きく、探索用アイテムは低い)
- 期待値: 得られるアイテムに成功確率を掛けたもの
- 価値: アイテムの量または期待値ににアイテムの重みをかけたもの。これを最大化したい
- 目的関数: アイテム、成功確率、アイテムの重みを用いて最終的に得られるものの数値的価値を計算する関数
- レベル: モンスターのレベル。クエストをこなすことで上がる
- ランク: モンスターのランク。昇級(モンスター合成)により上がる。持っている技能のレベルに影響する
- 技能レベル: モンスターが持っている技能のレベル。モンスターのランクで解放されたり上がったりする。スキル1とスキル2のレベルは別々に上昇し、ランクで決まっている
- スキルレベル: モンスターが持っているスキルのレベル。モンスターを生成した段階でレベルは決まっており、レベルが高い程よく、高いほどレア
過程を書くので結果だけ欲しい人はヒューリスティックを用いた最適化に飛んでください。
Gurobiを用いた最適化
今回の最適化はGurobiという最適化ソルバーでどこまでやれるかという検証を含んでいるため、
まずはそれを使って段階的にモデルを作っていくことにしました。
用意したデータ
csvでデータを用意して、それをロードする形で使用します。用意したものは以下
- モンスターデータ: 所持しているモンスター個別の情報。同じ種類のモンスターが複数いることもある。下のデータを全てマージ
- 各モンスターまとめ: 以下の情報をもつ。ここは新しいモンスターを入手したり昇級したりすることで変化することがある
- モンスター種族
- レベル
- ランク
- スキル名
- スキルのレベル
- モンスタークラス: 以下の情報をもつ。モンスター種族を主キーとしてマージ
- モンスター種族
- モンスターの色
- 技能名
- ランクと技能レベル: 以下の情報をもつ。ランクを主キーとしてマージ
- ランク
- 技能レベル
- 各モンスターまとめ: 以下の情報をもつ。ここは新しいモンスターを入手したり昇級したりすることで変化することがある
- クエストデータ: 出現する可能性のあるクエストと報酬及び必要な技能のレベルなど
- クエスト一覧: 以下の情報をもつ。
- 必要モンスターレベル
- 必要キャラクターレベル(使用しない)
- フィールド
- クエスト名
- 各技能の必要レベル(必要ないスキルは
nan) - 必須技能
- キャラクターの色
- 技能の条件を満たすことで上昇するクエスト成功確率の値
- 報酬(成功確率0~100%で得られるもの)
- ボーナス(成功確率100~200%で得られるもの)
- 資材価値: 重みをつけるために各アイテムがどれだけプレイヤーにとって重要かまとめた表。プレイヤーによって違う
- exp関係(低い)
- ガチャ石やゲーム内通貨(超高い)
- モンスター召喚アイテム(高め)
- モンスターの体力回復アイテム(ほぼ0)
- 資材(一部以外ほぼ0)
- クエスト一覧: 以下の情報をもつ。
正直クエストで技能の条件を満たすことで上昇するクエスト成功確率の調査が一番面倒だった。
仕様がまだ完全に理解できてないし。
モデル想定
まず考えたのは2部マッチングの応用。
各モンスターがどのクエストに派遣されるかを$x_{i,j}$という変数で管理し、これを最適化します。
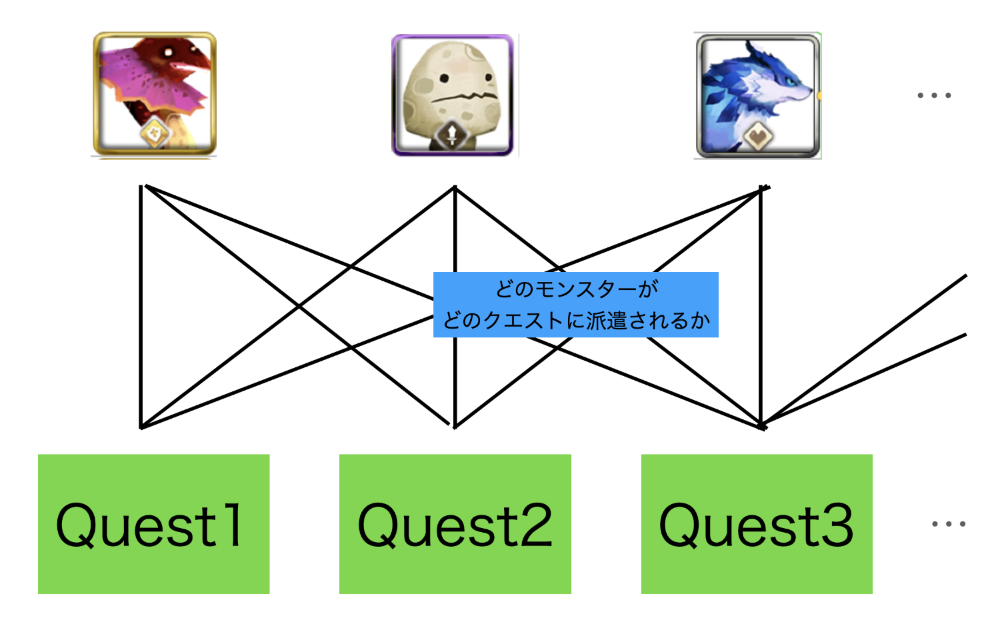
ただし、通常の2部マッチングとは違い、単にクエストとモンスターのマッチング回数が多ければいいというわけではありません。そもそも全てのモンスターは全てのクエストに派遣できますし・・・
最適化したいものは以下のように、クエストの必要技能をいくつ満たしているか(レベルも含め)になります
最低限の式
最大化したいもの
$$
\sum_i \sum_j \sum_k c_{i,j,k} \times x_{i,j}
$$
制約
$$
x_{i,j} \in {0,1}
$$
$$
\sum_i x_{i,j} \leq 4
$$
$$
\sum_j x_{i,j} \leq 1
$$
変数の説明
$x_{i,j}$ : モンスター$i$ をクエスト$j$に派遣するかどうか
$c_{i,j,k}$ : モンスター$i$がクエスト$j$に属している必要技能$k$を持っているかどうか
$c$と$x$は単純な行列の積では多分表せませんがイメージで書いてます
関数の作成
上の考え方をもとpythonでスクリプトを組みました。
データのロードとクエストの選択
def Load_csv():
datFld = "./dat/Sdoricaモンスター探索まとめ/"
#モンスターデータ本体
df_monsters = pd.read_csv(datFld+"モンスター詳細-所持モンスター.csv", header=1)
#モンスターに対応する色
df_monsters_color_skill = pd.read_csv(
datFld+"モンスター詳細-モンスタークラス.csv", header=1)
#モンスターのランクに対応するスキルレベル
df_monsters_skillLv = pd.read_csv(datFld+"モンスター詳細-ランクとレベル.csv", header=1)
#3つの表をマージ
df_monsters = pd.merge(
left=df_monsters, right=df_monsters_color_skill, on="species")
df_monsters = pd.merge(left=df_monsters, right=df_monsters_skillLv, on="rank")
#クエスト一覧
df_quests = pd.read_csv(datFld+"クエスト-クエスト.csv", header=1)
#クエストで得られた資材の価値
df_quantity = pd.read_csv(datFld+"クエスト-資材価値.csv", header=1)
return df_monsters,df_quests,df_quantity
def Select_quest(df_quests):
random.seed(20)
df_quests_selected = pd.DataFrame()
selected_index = []
for sub in df_quests["種別"].unique().tolist():
idx = df_quests.loc[df_quests["種別"] == sub,:].index.tolist()
selected_index.append(idx[random.randint(0, len(idx)-1)])
#ランダム選択されたインデックスをもとに選択
for sel in selected_index:
df_quests_selected = df_quests_selected.append(df_quests.iloc[sel,:])
return df_quests_selected.reset_index(drop=True)
クエストの選択はプレイヤーが行うべきですが、検証用なのでとりあえずランダム選択しています。
最適化部分
if __name__ == "__main__":
#データのロード
df_monsters, df_quests, df_quantity = Load_csv()
#クエストの選択(ランダム選択)
df_quests_selected = Select_quest(df_quests)
#選ばれたクエストの列挙
"""
for name in df_quests_selected.quest_name_unique.tolist():
print(name)
print("が選ばれました")
"""
#モデル定義
model = gurobipy.Model("MonsterJob")
# モンスターiがクエストjに取り組むかどうかを表す変数の定義
x={}
I = len(df_monsters)
J = len(df_quests_selected)
for i in range(I):
for j in range(J):
#離散的な値で、0<=x[i,j]<=1
x[i,j] = model.addVar(vtype="I",ub=1,lb=0)
# モンスターiが、クエストjの各スキルについてどのくらいの重みを持つか
# とりあえず該当するスキルがあれば重みを1にする
skills = {"傷": 0, "弱化": 1, "めまい": 2, "運搬": 3,
"挑発": 4, "サーチ": 5, "毒撃": 6, "再生": 7, "回避": 8}
skills_list=list(skills.keys())
bet_mons_skill = {}
for i in range(I):
for j in range(J):
for skill in skills_list:
#モンスターiがskillを持っていて、ジョブjがskillを必要としていたら1,そうでなければ0
for sk in ["skill1_name","skill2_name"]:
#モンスターが持っているか
if df_monsters.iloc[i][sk] == skill:
#クエストが持っているか
if df_quests_selected.iloc[j][skill] > 0:
bet_mons_skill[(i, j, skills[skill])] = 1
break
else:
#クエストが持っていないか、クエストとモンスターが一致していない
bet_mons_skill[(i, j, skills[skill])] = 0
model.update()
#制約、各クエストに対して入ってくるxの合計は4以下(クエストが増えると制約が変わる可能性がある)
for j in range(J):
model.addConstr(gurobipy.quicksum(x[i,j] for i in range(I)) <= 4)
#制約、各モンスターは1個のクエストにしか出られない
for i in range(I):
model.addConstr(gurobipy.quicksum(x[i,j] for j in range(J)) <= 1)
#レベルは無視して、必要なクエストに対する重みを決定し、それを最大化する
model.setObjective(gurobipy.quicksum(sum([bet_mons_skill[i,j,k] for k in range(len(skills_list))])*x[i,j] for (i,j) in x), gurobipy.GRB.MAXIMIZE)
#結果の出力
print("Optimal value:{}".format(model.ObjVal))
EPS = 1.e-6
quest={df_quests_selected.iloc[j]["quest_name_unique"]:[] for j in range(J)}
for (i,j) in x:
if x[i,j].X > EPS:
quest[df_quests_selected.iloc[j]
["quest_name_unique"]].append(df_monsters.loc[i]["species"])
for k in quest:
print("{}に出動するモンスター:{}".format(k, quest[k]))
クエスト内で必要な技能のレベルまでは考慮していません。
プログラム全体
長いので省略しています
import gurobipy
import pandas as pd
import os
import random
import numpy as np
def Load_csv():
datFld = "./dat/Sdoricaモンスター探索まとめ/"
#モンスターデータ本体
df_monsters = pd.read_csv(datFld+"モンスター詳細-所持モンスター.csv", header=1)
#モンスターに対応する色
df_monsters_color_skill = pd.read_csv(
datFld+"モンスター詳細-モンスタークラス.csv", header=1)
#モンスターのランクに対応するスキルレベル
df_monsters_skillLv = pd.read_csv(datFld+"モンスター詳細-ランクとレベル.csv", header=1)
#3つの表をマージ
df_monsters = pd.merge(
left=df_monsters, right=df_monsters_color_skill, on="species")
df_monsters = pd.merge(left=df_monsters, right=df_monsters_skillLv, on="rank")
#クエスト一覧
df_quests = pd.read_csv(datFld+"クエスト-クエスト.csv", header=1)
#数値はintにすると思ったけどnanのあるものは変換できなかった
#for col in df_quests.columns.tolist():
# print(df_quests[col].dtype)
# if df_quests[col].dtype =="float64":
# df_quests[col] = df_quests[col].astype("int64")
#クエストで得られた資材の価値
df_quantity = pd.read_csv(datFld+"クエスト-資材価値.csv", header=1)
return df_monsters,df_quests,df_quantity
def Select_quest(df_quests):
random.seed(20)
df_quests_selected = pd.DataFrame()
selected_index = []
for sub in df_quests["種別"].unique().tolist():
idx = df_quests.loc[df_quests["種別"] == sub,:].index.tolist()
selected_index.append(idx[random.randint(0, len(idx)-1)])
#ランダム選択されたインデックスをもとに選択
for sel in selected_index:
df_quests_selected = df_quests_selected.append(df_quests.iloc[sel,:])
#quest_nameだとuniqueじゃないので新しい列を作成
df_quests_selected["quest_name_unique"] = df_quests_selected.field.astype(str) + "_"+df_quests_selected.quest_name.astype(str)
df_quests_selected["quest_name_unique"] = df_quests_selected.quest_name_unique.str.replace("nan_","")
return df_quests_selected.reset_index(drop=True)
def collate_mons_skill(i,j,k,mons,quests):
"""
モンスターiがクエストjのk番目のスキルについて適合しているかを判断する
"""
skills = ["傷", "弱化", "めまい", "運搬","挑発", "サーチ", "毒撃", "再生", "回避"]
#値が入っていない場合判定不要
if quests.iloc[j][skills[k]] != quests.iloc[j][skills[k]]:
return 0
#スキル条件を満たしているかを判定
if mons.iloc[i]["skill1_name"] == skills[k] and mons.iloc[i]["skill1_level"] >= quests.iloc[j][skills[k]]:
return 1
elif mons.iloc[i]["skill2_name"] == skills[k] and mons.iloc[i]["skill2_level"] >= quests.iloc[j][skills[k]]:
return 1
else:
return 0
if __name__ == "__main__":
#データのロード
df_monsters, df_quests, df_quantity = Load_csv()
#クエストの選択(ランダム選択)
df_quests_selected = Select_quest(df_quests)
#選ばれたクエストの列挙
"""
for name in df_quests_selected.quest_name_unique.tolist():
print(name)
print("が選ばれました")
"""
#モデル定義
model = gurobipy.Model("MonsterJob")
# モンスターiがクエストjに取り組むかどうかを表す変数の定義
x={}
I = len(df_monsters)
J = len(df_quests_selected)
for i in range(I):
for j in range(J):
#離散的な値で、0<=x[i,j]<=1
x[i,j] = model.addVar(vtype="I",ub=1,lb=0)
# モンスターiが、クエストjの各スキルについてどのくらいの重みを持つか
# とりあえず該当するスキルがあれば重みを1にする
skills = {"傷": 0, "弱化": 1, "めまい": 2, "運搬": 3,
"挑発": 4, "サーチ": 5, "毒撃": 6, "再生": 7, "回避": 8}
skills_list=list(skills.keys())
bet_mons_skill = {}
for i in range(I):
for j in range(J):
for skill in skills_list:
#モンスターiがskillを持っていて、ジョブjがskillを必要としていたら1,そうでなければ0
for sk in ["skill1_name","skill2_name"]:
#モンスターが持っているか
if df_monsters.iloc[i][sk] == skill:
#クエストが持っているか
if df_quests_selected.iloc[j][skill] > 0:
bet_mons_skill[(i, j, skills[skill])] = 1
break
else:
#クエストが持っていないか、クエストとモンスターが一致していない
bet_mons_skill[(i, j, skills[skill])] = 0
model.update()
#制約、各クエストに対して入ってくるxの合計は4以下(クエストが増えると制約が変わる可能性がある)
for j in range(J):
model.addConstr(gurobipy.quicksum(x[i,j] for i in range(I)) <= 4)
#制約、各モンスターは1個のクエストにしか出られない
for i in range(I):
model.addConstr(gurobipy.quicksum(x[i,j] for j in range(J)) <= 1)
#レベルは無視して、必要なクエストに対する重みを決定し、それを最大化する
model.setObjective(gurobipy.quicksum(sum([bet_mons_skill[i,j,k] for k in range(len(skills_list))])*x[i,j] for (i,j) in x), gurobipy.GRB.MAXIMIZE)
model.optimize()
#結果の出力
print("Optimal value:{}".format(model.ObjVal))
EPS = 1.e-6
quest={df_quests_selected.iloc[j]["quest_name_unique"]:[] for j in range(J)}
for (i,j) in x:
if x[i,j].X > EPS:
quest[df_quests_selected.iloc[j]
["quest_name_unique"]].append(df_monsters.loc[i]["species"])
for k in quest:
print("{}に出動するモンスター:{}".format(k, quest[k]))
結果
各クエストにどのモンスターが派遣されるかを表しています
Optimal value:134.0
青空草原_秘境の宝さがしに出動するモンスター:['ノミクサ', 'パック', 'ビーバー・つー坊', '剣士ガンボル']
熾烈なバトル訓練6に出動するモンスター:['碧狼', 'クスメット', 'ワニエル', 'ハサメット']
熾烈なキャンプ巡回1に出動するモンスター:['狂犬', 'ピョコノコママ', 'カモノソ', 'サンタガンボル']
トーテムタフ_トーテムタフの端-フィールド調査に出動するモンスター:['アカクタス', '小グル獣', '野生の子ワニエル', 'オバネムシ']
特級材料収集1に出動するモンスター:['サーパン', 'はらぺこ湖ドロリ', '魔物ガンボル', '剣士ガンボル']
トーテムタフ_エリア探査に出動するモンスター:['コケマル', 'トパス', 'ウキウミクラゲ', 'アテナガンボル', 'かじり草', '巨大サソリ', '吸血スライム', 'グライピオン']
高級食料貯蔵3に出動するモンスター:['グラスグース', 'カタ獣', 'ワタネズミ', 'カタ獣']
さえずり峡谷_変異点-フィールド調査に出動するモンスター:['ビーバー・あー坊', 'トゲミミザル', 'ノミクサ', '吸血スライム']
アトラス_秘境の奥へに出動するモンスター:['ブタバナ', 'アクダマ', 'ブタバナ', 'サンタガンボル']
ハードなバトル訓練5に出動するモンスター:['ドングリコ', 'カタ獣', 'カタ獣', '乙女ガンボル']
ポリヴァ砂漠_聖骨の谷-フィールド調査に出動するモンスター:['トラガンボル', 'ピョコノコママ', '炎尾トカゲ']
高級材料収集1に出動するモンスター:['ドングリコ', 'ハダカワタネズミ', '赤ずきんガンボル', 'ハダカワタネズミ']
ハードなキャンプ巡回1に出動するモンスター:['緋狼', 'ピョコノコ', 'トラ柄トゲミミザル', '赤ずきんガンボル']
さえずり峡谷_迷路の森-フィールド調査に出動するモンスター:['ホネバット', '茶狼', 'ハキダシリュー', 'かじり草']
中級食料貯蔵2に出動するモンスター:['アカイッカク', '乙女ガンボル', 'クロワッサンガンボル', '冒険者ガンボル']
メイプル湖畔_湖の中心-フィールド調査に出動するモンスター:['ポブ', 'ビーバー・たー坊', 'ノミカレハ', '冒険者ガンボル']
見づらいですが結果はこのようになりました。
例えば、
アトラス_秘境の奥へに出動するモンスター:['ブタバナ', 'アクダマ', 'ブタバナ', 'サンタガンボル']
の部分では同じモンスターが2体派遣されています。スキルの影響で同じモンスターを出しても確率が上昇することはありますが今回はスキルを考慮に入れていません。
つまり片方は全く仕事をしていないので効率が悪いです。
ここで、技能が一致しているかどうかの判断を論理値や、上界を取ることが考えられます。つまり下式
$$
\sum_j \sum_k \bigoplus_ic_{i,j,k} \times x_{i,j}
$$
このように計算を行えば、あるクエストで複数の同種モンスターが派遣されても1体分になって無駄がありません。
・・・しかし、gurobipyのsetObjective(maximizeするものの記述)関数内では論理和などはおそらく使えません。制約としては使えます。
通常のorなどを使えばいいと思われるかもしれませんが、そもそも$x_{i,j}$は単なる数値として取り出せません(gurobipy.optimize()内で初めて解釈されます)
>>>print(x[i,j])
<gurobi.Var C1138>
ならば、$k$を総和のままで、総和した結果をシグモイド関数あたりを使って0 or 1にしてしまえばいいと思われるかもしれません
$$
\sum_j \sum_k \frac{1}{1+e^{-(\sum_i c_{i,j,k} \times x_{i,j})}}
$$
これはエラーになります。x[i,j]及びgurobipy.quicksum()の計算結果を用いた除算はできないようです。加減乗はできます。
そもそも、まだ要素の1つしか含んでいないのに、setObjective関数が長くなり過ぎています。
課題
触っているうちに気づいた課題が以下です。
- ifなどを用いた複雑なモデルは定義が難しい
- 最適化する変数($x$)しか定義できず、中間の変数のようなものが使えない(黒色のモンスターが存在するかどうかのフラグなど)
- 目的関数部分に一行で利得の式を全て書かなくてはいけない
- quicksumなどの機能が不勉強のためわからない
なので自分で目的関数などを定義してヒューリスティック的に最適化を行うことにしました。
ヒューリスティックを用いた最適化
Gurobiが厳しいのでゲームでの確率計算を再現し、確率を元にアイテムが得られる期待値と重み付けをした価値を算出。
算出した価値を最大となるようにモンスターの組み合わせを決めることにしました。
前のと変わってない部分
用意するデータとデータのロード、クエスト選択の関数は変わりません
計算内容
成功確率probabilityを計算し、そこから報酬の期待値を計算。それに各アイテムの重み(重要性)をかけて得られる価値valueかprofitを出します。
目的関数
成功確率計算と、報酬の期待値計算を分けています。
確率計算
モンスター情報とクエスト情報ののcsvを総動員して計算します。
def calc_probability(monsNo,jobNo,df_monsters,df_quests_selected):
"""
確率計算目的関数
Input:
monsNo: list(int)
モンスター番号
jobNo: int
ジョブ番号
df_quests_selectedから選択
Output:
resp: float
確率[0,200]
Note:
計算内容は
- 各モンスターがジョブのスキル1,2の条件を満たしているか
- スキル3,4の合計レベルを全て求める
- 参加しているモンスターの色情報をまとめる
- キャラクターの色を調べる
- キャラ色、モンスター色、フィールド情報、いぶし銀情報をもとに確率加算する
- モンスターレベルが足りていなければその分マイナスする
- 必須スキルが全て含まれていなければ0をかける
- 確率をもとにどのアイテムがどれくらい得られるかを計算
- 重みをつけて価値を算出
#nanの判定はこれで行う
#np.isnan(df_quests_selected.iloc[1].傷)
"""
#スキル1,2がジョブの条件を満たしていたら1にする
skill12={"傷": 0, "弱化": 0, "めまい": 0, "運搬": 0,
"挑発": 0, "サーチ": 0, "毒撃": 0, "再生": 0, "回避": 0}
#必須スキル判定
neededSkill = 1
#合計何レベル分あるかをカウントする
skill34={"いぶし銀":0, "前衛小隊":0, "中衛小隊":0, "後衛小隊":0, "前衛":0, "中衛":0, "後衛":0,
"アトラス":0, "さえずり峡谷":0, "トーテムタフ":0, "ポリヴァ砂漠":0, "メイプル湖畔":0, "青空草原":0,
"チームワーク":0, "時計のやつ":0}
mons_color={"yellow":0,"black":0,"white":0}
chara_color = {"yellow":0,"black":0,"white":0}
#キャラクター色の判定
chara_color[df_quests_selected.iloc[jobNo]["character_color"]]=1
diffmonsLv=0
for m in monsNo:
#print("モンスター:{}".format(df_monsters.iloc[m].species))
#スキル3,4のカウント
skill34[df_monsters.iloc[m]["skill3_name"]]+=df_monsters.iloc[m]["skill3_level"]
skill34[df_monsters.iloc[m]["skill4_name"]]+=df_monsters.iloc[m]["skill4_level"]
#スキル1,2の検証
for k in skill12:
if np.isnan(df_quests_selected.iloc[jobNo][k]):
continue
if df_monsters.iloc[m]["skill1_name"] == k:
skill12[k] |= (df_monsters.iloc[m]["skill1_level"]>=df_quests_selected.iloc[jobNo][k])
if df_monsters.iloc[m]["skill2_name"] == k:
skill12[k] |= (df_monsters.iloc[m]["skill2_level"]>=df_quests_selected.iloc[jobNo][k])
#モンスター色のカウント
mons_color[df_monsters.iloc[m]["color"]] |= 1
#レベルによる確率低下
diffmonsLv += max(df_quests_selected.iloc[jobNo].need_monster_level-df_monsters.iloc[m].level,0)
#必須スキル判定。全て持っていれば1。持っていなければ0
neededSkill &= skill12[df_quests_selected.iloc[jobNo]["required_skill1"]] & skill12[df_quests_selected.iloc[jobNo]["required_skill2"]]
#スキル1,2を使った基礎確率を求める
basep = 0
for k in skill12:
if np.isnan(df_quests_selected.iloc[jobNo][k]):
continue
lv = int(df_quests_selected.iloc[jobNo][k])
basep += skill12[k]*df_quests_selected.iloc[jobNo]["lv"+str(lv)]
#スキル3,4による確率上昇
addp = 0
if type(df_quests_selected.iloc[jobNo]["field"])==str: # npだとstrに対してisnanが使えないので
addp += skill34[df_quests_selected.iloc[jobNo]["field"]]*5
addp += skill34["いぶし銀"]*5
addp += skill34["前衛"]*5*chara_color["yellow"]
addp += skill34["中衛"]*5*chara_color["black"]
addp += skill34["後衛"]*5*chara_color["white"]
addp += skill34["前衛小隊"]*5*mons_color["yellow"]
addp += skill34["中衛小隊"]*5*mons_color["black"]
addp += skill34["後衛小隊"]*5*mons_color["white"]
if DEBUG:
print("クエスト名:{}".format(df_quests_selected.iloc[jobNo]["quest_name_unique"]))
print("basep:{}, addp:{}, diffmonsLv:{}, neededSkill:{}".format(basep,addp,diffmonsLv,neededSkill))
print()
resp = (basep+addp-diffmonsLv)*neededSkill
return max(min(200,resp),0)
得られるアイテムの期待値と価値の計算
def Obj_func_profit(probablity,jobNo,df_quests_selected,value_of_items):
"""
利得を含めた目的関数
"""
items = {"exp":0,"exp_home":0, #exp関係
"gem":0,"crystal":0, #Sdorica本編に関わるアイテム関係
"apple":0,"jerry":0,"egg":0,"croissant":0,"cheese":0,"cupcake":0, #モンスター召喚アイテム
"dango":0,"band":0,"syrup":0, #モンスターの体力回復アイテム
"material":0,"fence":0,"straw":0,"cloth":0 #資材
}
prob_upto100 = min(100,probablity)/100
prob_upto200 = max(0,min(100,probablity-100))/100
#各アイテムがprobabilityを持つときにどれくらい得られるかを求める
for k in items:
if not np.isnan(df_quests_selected.iloc[jobNo][k+"_upto100"]):
items[k] += df_quests_selected.iloc[jobNo][k+"_upto100"]*prob_upto100
if not np.isnan(df_quests_selected.iloc[jobNo][k+"_upto200"]):
items[k] += df_quests_selected.iloc[jobNo][k+"_upto200"]*prob_upto200
#アイテムごとの貴重さ(重み)をかける
itemValue=0
for k in items:
itemValue += items[k]*value_of_items.loc[value_of_items.item==k,"value_multiply"].tolist()[0]
return itemValue
価値を最大化するアルゴリズム
main部分
if __name__ == "__main__":
#DEBUG
DEBUG = False
#データのロード
df_monsters, df_quests, df_quantity, df_value_items = Load_csv()
#ランダムの設定
random.seed(20)
#クエストの選択(ランダム選択)
select=[]
#検証用select
select = [0, 7, 12, 17, 23, 28, 32, 37, 46, 49, 57, 58, 63, 66, 72, 78, 82]
#ランダムにクエスト選択
#df_quests_selected = Select_quest(df_quests,S=select)
#マニュアルのクエスト選択
df_quests_selected = Select_quest_manual(df_quests,selected_index = select)
#選ばれたクエストの表を作る
df_res = pd.DataFrame([],columns = ["number","member","prob","profit","profit_200","questName","member_name"])
for i,name in enumerate(df_quests_selected.quest_name_unique.tolist()):
maxValue = Obj_func_profit(200,i,df_quests_selected,df_value_items)
df_res = df_res.append(
{"questName": name,"number":i,"member":[],"prob":0,"profit":0,"profit_200":maxValue}
,ignore_index=True)
#理想的なリストが大きい順に並べる
df_res = df_res.sort_values(by="profit_200",ascending=False).reset_index(drop=True)
print(df_res)
#最適化
df_res,prob_transition,value_transition = optimize(df_res,iter=2000)
#推移の可視化
plot_transition(prob_transition, "probability transition", [0,200], "prob_transition")
plot_transition(value_transition, "value transition", [0,1], "value_transition")
#ゲーム画面で並んでる順番に戻す
df_res = df_res.sort_values("number",ascending=True).reset_index(drop=True)
print(df_res)
print("sumOfvalue={}".format(df_res.profit.sum()))
df_res.to_csv("./output/{}_result.csv".format(day8()))
profit_200という列は各クエストの成功確率が200%をなる時に得られる報酬の価値を表しており、その値が大きい順にソートしてから
最適化をおこなっています。
貪欲法を用いた乱択
山登り方や焼きなまし法などがありますが、なにぶん目的関数が超複雑なので、とりあえず貪欲法で行います。
各クエストの理想的な状況のアイテムの価値(=クエスト成功確率が200%となる時の報酬の価値)を計算し、それが大きいものから出動モンスターを決定していきます。
価値の大きいクエストの出動モンスターがある程度決まるか、成功確率が0%にしかならない場合は次のクエストを確認して、残りのモンスターをどのように出動させるかを検討します
乱択なので繰り返し回数が決定しづらいですがとりあえず2000回各クエストについて回しています。
optimize関数
def optimize(df_res,iter=20):
"""
最適化を行う
理想利得が高いものから順に貪欲法で求めていく
最低でも必須枠は埋まるようにあらかじめモンスターを選択しておく
Input
iter: int
ランダム選択回数。2000で大体17分程度かかる
Output
df_res
どのクエストにどのモンスターを出動させるとどれくらいの利得が得られるかなどの表
"""
# ランダムにクエスト配属して最適化していく
monsterNo = [x for x in range(len(df_monsters))]
# probとvalueの推移を記録する
prob_transition = []
value_transition = []
for i in tqdm(range(len(df_res))):
questNo = df_res.iloc[i]["number"]
#i番目のジョブに必須なスキルを持ってるモンスターのインデックスを取り出す
ndSkill = [df_quests_selected.iloc[questNo].required_skill1,df_quests_selected.iloc[questNo].required_skill2]
ndSkillLv = [df_quests_selected.iloc[questNo][ndSkill[x]] for x in range(len(ndSkill))]
skill1Monster = df_monsters[((df_monsters.skill1_name==ndSkill[0]) & (df_monsters.skill1_level >= ndSkillLv[0])) | ((df_monsters.skill2_name==ndSkill[0]) & (df_monsters.skill2_level >= ndSkillLv[0]))].index.tolist()
skill2Monster = df_monsters[((df_monsters.skill1_name==ndSkill[1]) & (df_monsters.skill1_level >= ndSkillLv[1])) | ((df_monsters.skill2_name==ndSkill[1]) & (df_monsters.skill2_level >= ndSkillLv[1]))].index.tolist()
#monsterNoに入っているものにする
skill1Monster = list(set(monsterNo)&set(skill1Monster))
skill2Monster = list(set(monsterNo)&set(skill2Monster))
if len(skill1Monster)==0:
print("クエスト {} で {} が足りません".format(df_res.iloc[i]["questName"],ndSkill[0]))
continue
if len(skill2Monster)==0:
print("クエスト {} で {} が足りません".format(df_res.iloc[i]["questName"],ndSkill[1]))
continue
# 推移記録用変数
temp_prob_transition = []
temp_value_transition = []
# 乱択を適当な回数を行う
for j in range(iter):
#必須スキルを持つモンスターを1体ずつ選ぶ。同じモンスターが選ばれた場合はsetで1体として扱う
randomSelect = list(set(random.sample(skill1Monster,1)+random.sample(skill2Monster,1)))
#現在選べる全てのモンスターから選んだモンスターを引く
lestMons = list(set(monsterNo)-set(randomSelect))
#改めて必要なモンスターを選ぶ
selectedMonsters = randomSelect + random.sample(lestMons,4-len(randomSelect))
selectedMonsters = list(sorted(selectedMonsters)) #見やすいようにソート
#目的関数で利得を求める
prob = calc_probability(selectedMonsters,df_res.iloc[i].number,df_monsters,df_quests_selected)
value = Obj_func_profit(prob,df_res.iloc[i].number,df_quests_selected,df_value_items)
#上回っていたら更新
if value > df_res.iloc[i]["profit"]:
#TODO: 取り除いても確率が変わらなければそのモンスターを除く
#TODO: SettingWithCopyWarning対策:locで指定してもエラーが出るので対処法がわからない
df_res["member"][i] = selectedMonsters
df_res["prob"][i] = prob
df_res["profit"][i] = value
temp_prob_transition.append(df_res["prob"][i])
temp_value_transition.append(df_res["profit"][i]/df_res.iloc[i]["profit_200"])
else:
#選べるモンスターの選択肢を減らす
monsterNo = list(sorted(list(set(monsterNo)-set(df_res.iloc[i].member))))
#出力のためにモンスターの種類を求めておく
member_name = []
for m in df_res.iloc[i].member:
member_name.append(df_monsters.iloc[m]["species"])
df_res["member_name"][i] = member_name
#推移記録
prob_transition.append(temp_prob_transition)
value_transition.append(temp_value_transition)
return df_res,prob_transition,value_transition
工夫した内容
ただの乱択だとスキル2,3の必須項目が足りずにたいてい0%となってしまって効率が悪いので、
クエストごとに決められた必須技能をカバーするようにモンスターを数体選んでから他のモンスターを選ぶようにします。(for i ...の次の行からの部分)
コード内容
コード全体
長いので省略しています
import pandas as pd
import os
import random
import numpy as np
from tqdm import tqdm
import copy
import sys
import datetime
import matplotlib.pyplot as plt
def day8():
"""
年月日を8桁の整数の文字列として返す
"""
t_delta = datetime.timedelta(hours=9)
JST = datetime.timezone(t_delta, 'JST')
return datetime.datetime.now().strftime('%Y%m%d')
def Load_csv():
"""
必要なcsvファイルを選択する。
マージする必要があるものはマージする
"""
datFld = "./dat/Sdoricaモンスター探索まとめ/"
#モンスターデータ本体
df_monsters = pd.read_csv(datFld+"モンスター詳細-所持モンスター.csv", header=1)
#モンスターに対応する色
df_monsters_color_skill = pd.read_csv(
datFld+"モンスター詳細-モンスタークラス.csv", header=1)
#モンスターのランクに対応するスキルレベル
df_monsters_skillLv = pd.read_csv(datFld+"モンスター詳細-ランクとレベル.csv", header=1)
#3つの表をマージ
df_monsters = pd.merge(
left=df_monsters, right=df_monsters_color_skill, on="species")
df_monsters = pd.merge(left=df_monsters, right=df_monsters_skillLv, on="rank")
#クエスト一覧
df_quests = pd.read_csv(datFld+"クエスト-クエスト.csv", header=1)
#数値はintにすると思ったけどnanのあるものは変換できなかった
#for col in df_quests.columns.tolist():
# print(df_quests[col].dtype)
# if df_quests[col].dtype =="float64":
# df_quests[col] = df_quests[col].astype("int64")
#クエストで得られた資材の価値
df_quantity = pd.read_csv(datFld+"クエスト-資材価値.csv", header=1)
#資材価値
df_value_items = pd.read_csv(datFld+"クエスト-資材価値.csv",header=1)
return df_monsters,df_quests,df_quantity,df_value_items
def Select_quest(df_quests, S=[]):
"""
ランダムにクエストを選択する。
検証用
"""
df_quests_selected = pd.DataFrame()
if S:
selected_index = S
else:
selected_index = []
#種別の中で何番目かをselected_indexに入れる
for sub in df_quests["種別"].unique().tolist():
idx = df_quests.loc[df_quests["種別"] == sub,:].index.tolist()
selected_index.append(idx[random.randint(0, len(idx)-1)])
#ランダム選択されたインデックスをもとに選択
for sel in selected_index:
df_quests_selected = df_quests_selected.append(df_quests.iloc[sel,:])
#quest_nameだとuniqueじゃないので新しい列を作成
df_quests_selected["quest_name_unique"] = df_quests_selected.field.astype(str) + "_"+df_quests_selected.quest_name.astype(str)
df_quests_selected["quest_name_unique"] = df_quests_selected.quest_name_unique.str.replace("nan_","")
return df_quests_selected.reset_index(drop=True)
def Select_quest_manual(df_quests,selected_index = []):
"""
手動でクエストを選ぶ
ゲーム上では種別ごとにランダムで選ばれ、
種別の順に並ぶのでゲームを見ながら選択できるはず
"""
df_quests["quest_name_unique"] = df_quests.field.astype(str) + "_"+df_quests.quest_name.astype(str)
df_quests["quest_name_unique"] = df_quests.quest_name_unique.str.replace("nan_","")
if len(selected_index)==0:
selected_index=[]
for sub in df_quests["種別"].unique().tolist():
tempdf = df_quests.loc[df_quests["種別"] == sub,"quest_name_unique"]
idx = tempdf.index.tolist()
for i in idx:
print("{0:2d} {1}".format(i,tempdf[i]))
selected_index.append(int(input("該当クエストのindexは?")))
print()
print(selected_index)
#選択されたインデックスをもとに選択
df_quests_selected=pd.DataFrame()
for sel in selected_index:
df_quests_selected = df_quests_selected.append(df_quests.iloc[sel,:])
return df_quests_selected.reset_index(drop=True)
def Obj_func_profit(probablity,jobNo,df_quests_selected,value_of_items):
"""
利得を含めた目的関数
"""
items = {"exp":0,"exp_home":0, #exp関係
"gem":0,"crystal":0, #Sdorica本編に関わるアイテム関係
"apple":0,"jerry":0,"egg":0,"croissant":0,"cheese":0,"cupcake":0, #モンスター召喚アイテム
"dango":0,"band":0,"syrup":0, #モンスターの体力回復アイテム
"material":0,"fence":0,"straw":0,"cloth":0 #資材
}
prob_upto100 = min(100,probablity)/100
prob_upto200 = max(0,min(100,probablity-100))/100
#各アイテムがprobabilityを持つときにどれくらい得られるかを求める
for k in items:
if not np.isnan(df_quests_selected.iloc[jobNo][k+"_upto100"]):
items[k] += df_quests_selected.iloc[jobNo][k+"_upto100"]*prob_upto100
if not np.isnan(df_quests_selected.iloc[jobNo][k+"_upto200"]):
items[k] += df_quests_selected.iloc[jobNo][k+"_upto200"]*prob_upto200
#アイテムごとの貴重さ(重み)をかける
itemValue=0
for k in items:
itemValue += items[k]*value_of_items.loc[value_of_items.item==k,"value_multiply"].tolist()[0]
return itemValue
def calc_probability(monsNo,jobNo,df_monsters,df_quests_selected):
"""
確率計算目的関数
Input:
monsNo: list(int)
モンスター番号
jobNo: int
ジョブ番号
df_quests_selectedから選択
Output:
resp: float
確率[0,200]
Note:
計算内容は
- 各モンスターがジョブのスキル1,2の条件を満たしているか
- スキル3,4の合計レベルを全て求める
- 参加しているモンスターの色情報をまとめる
- キャラクターの色を調べる
- キャラ色、モンスター色、フィールド情報、いぶし銀情報をもとに確率加算する
- モンスターレベルが足りていなければその分マイナスする
- 必須スキルが全て含まれていなければ0をかける
- 確率をもとにどのアイテムがどれくらい得られるかを計算
- 重みをつけて価値を算出
#nanの判定はこれで行う
#np.isnan(df_quests_selected.iloc[1].傷)
"""
#スキル1,2がジョブの条件を満たしていたら1にする
skill12={"傷": 0, "弱化": 0, "めまい": 0, "運搬": 0,
"挑発": 0, "サーチ": 0, "毒撃": 0, "再生": 0, "回避": 0}
#必須スキル判定
neededSkill = 1
#合計何レベル分あるかをカウントする
skill34={"いぶし銀":0, "前衛小隊":0, "中衛小隊":0, "後衛小隊":0, "前衛":0, "中衛":0, "後衛":0,
"アトラス":0, "さえずり峡谷":0, "トーテムタフ":0, "ポリヴァ砂漠":0, "メイプル湖畔":0, "青空草原":0,
"チームワーク":0, "時計のやつ":0}
mons_color={"yellow":0,"black":0,"white":0}
chara_color = {"yellow":0,"black":0,"white":0}
#キャラクター色の判定
chara_color[df_quests_selected.iloc[jobNo]["character_color"]]=1
diffmonsLv=0
for m in monsNo:
#print("モンスター:{}".format(df_monsters.iloc[m].species))
#スキル3,4のカウント
skill34[df_monsters.iloc[m]["skill3_name"]]+=df_monsters.iloc[m]["skill3_level"]
skill34[df_monsters.iloc[m]["skill4_name"]]+=df_monsters.iloc[m]["skill4_level"]
#スキル1,2の検証
for k in skill12:
if np.isnan(df_quests_selected.iloc[jobNo][k]):
continue
if df_monsters.iloc[m]["skill1_name"] == k:
skill12[k] |= (df_monsters.iloc[m]["skill1_level"]>=df_quests_selected.iloc[jobNo][k])
if df_monsters.iloc[m]["skill2_name"] == k:
skill12[k] |= (df_monsters.iloc[m]["skill2_level"]>=df_quests_selected.iloc[jobNo][k])
#モンスター色のカウント
mons_color[df_monsters.iloc[m]["color"]] |= 1
#レベルによる確率低下
diffmonsLv += max(df_quests_selected.iloc[jobNo].need_monster_level-df_monsters.iloc[m].level,0)
#必須スキル判定。全て持っていれば1。持っていなければ0
neededSkill &= skill12[df_quests_selected.iloc[jobNo]["required_skill1"]] & skill12[df_quests_selected.iloc[jobNo]["required_skill2"]]
#スキル1,2を使った基礎確率を求める
basep = 0
for k in skill12:
if np.isnan(df_quests_selected.iloc[jobNo][k]):
continue
lv = int(df_quests_selected.iloc[jobNo][k])
basep += skill12[k]*df_quests_selected.iloc[jobNo]["lv"+str(lv)]
#スキル3,4による確率上昇
addp = 0
if type(df_quests_selected.iloc[jobNo]["field"])==str: # npだとstrに対してisnanが使えないので
addp += skill34[df_quests_selected.iloc[jobNo]["field"]]*5
addp += skill34["いぶし銀"]*5
addp += skill34["前衛"]*5*chara_color["yellow"]
addp += skill34["中衛"]*5*chara_color["black"]
addp += skill34["後衛"]*5*chara_color["white"]
addp += skill34["前衛小隊"]*5*mons_color["yellow"]
addp += skill34["中衛小隊"]*5*mons_color["black"]
addp += skill34["後衛小隊"]*5*mons_color["white"]
if DEBUG:
print("クエスト名:{}".format(df_quests_selected.iloc[jobNo]["quest_name_unique"]))
print("basep:{}, addp:{}, diffmonsLv:{}, neededSkill:{}".format(basep,addp,diffmonsLv,neededSkill))
print()
resp = (basep+addp-diffmonsLv)*neededSkill
return max(min(200,resp),0)
def optimize(df_res,iter=20):
"""
最適化を行う
理想利得が高いものから順に貪欲法で求めていく
最低でも必須枠は埋まるようにあらかじめモンスターを選択しておく
Input
iter: int
ランダム選択回数。2000で大体17分程度かかる
Output
df_res
どのクエストにどのモンスターを出動させるとどれくらいの利得が得られるかなどの表
"""
# ランダムにクエスト配属して最適化していく
monsterNo = [x for x in range(len(df_monsters))]
# probとvalueの推移を記録する
prob_transition = []
value_transition = []
for i in tqdm(range(len(df_res))):
questNo = df_res.iloc[i]["number"]
#i番目のジョブに必須なスキルを持ってるモンスターのインデックスを取り出す
ndSkill = [df_quests_selected.iloc[questNo].required_skill1,df_quests_selected.iloc[questNo].required_skill2]
ndSkillLv = [df_quests_selected.iloc[questNo][ndSkill[x]] for x in range(len(ndSkill))]
skill1Monster = df_monsters[((df_monsters.skill1_name==ndSkill[0]) & (df_monsters.skill1_level >= ndSkillLv[0])) | ((df_monsters.skill2_name==ndSkill[0]) & (df_monsters.skill2_level >= ndSkillLv[0]))].index.tolist()
skill2Monster = df_monsters[((df_monsters.skill1_name==ndSkill[1]) & (df_monsters.skill1_level >= ndSkillLv[1])) | ((df_monsters.skill2_name==ndSkill[1]) & (df_monsters.skill2_level >= ndSkillLv[1]))].index.tolist()
#monsterNoに入っているものにする
skill1Monster = list(set(monsterNo)&set(skill1Monster))
skill2Monster = list(set(monsterNo)&set(skill2Monster))
if len(skill1Monster)==0:
print("クエスト {} で {} が足りません".format(df_res.iloc[i]["questName"],ndSkill[0]))
continue
if len(skill2Monster)==0:
print("クエスト {} で {} が足りません".format(df_res.iloc[i]["questName"],ndSkill[1]))
continue
# 推移記録用変数
temp_prob_transition = []
temp_value_transition = []
# 乱択を適当な回数を行う
for j in range(iter):
#必須スキルを持つモンスターを1体ずつ選ぶ。同じモンスターが選ばれた場合はsetで1体として扱う
randomSelect = list(set(random.sample(skill1Monster,1)+random.sample(skill2Monster,1)))
#現在選べる全てのモンスターから選んだモンスターを引く
lestMons = list(set(monsterNo)-set(randomSelect))
#改めて必要なモンスターを選ぶ
selectedMonsters = randomSelect + random.sample(lestMons,4-len(randomSelect))
selectedMonsters = list(sorted(selectedMonsters)) #見やすいようにソート
#目的関数で利得を求める
prob = calc_probability(selectedMonsters,df_res.iloc[i].number,df_monsters,df_quests_selected)
value = Obj_func_profit(prob,df_res.iloc[i].number,df_quests_selected,df_value_items)
#上回っていたら更新
if value > df_res.iloc[i]["profit"]:
#TODO: 取り除いても確率が変わらなければそのモンスターを除く
#TODO: SettingWithCopyWarning対策:locで指定してもエラーが出るので対処法がわからない
df_res["member"][i] = selectedMonsters
df_res["prob"][i] = prob
df_res["profit"][i] = value
temp_prob_transition.append(df_res["prob"][i])
temp_value_transition.append(df_res["profit"][i]/df_res.iloc[i]["profit_200"])
else:
#選べるモンスターの選択肢を減らす
monsterNo = list(sorted(list(set(monsterNo)-set(df_res.iloc[i].member))))
#出力のためにモンスターの種類を求めておく
member_name = []
for m in df_res.iloc[i].member:
member_name.append(df_monsters.iloc[m]["species"])
df_res["member_name"][i] = member_name
#推移記録
prob_transition.append(temp_prob_transition)
value_transition.append(temp_value_transition)
return df_res,prob_transition,value_transition
def plot_transition(trans, plotTitle, lim, filename):
plt.style.use('tableau-colorblind10')
plt.figure()
plt.title(plotTitle)
for pt in trans:
plt.plot(pt)
plt.ylim(lim)
plt.savefig("./output/{}_{}.png".format(day8(),filename))
if __name__ == "__main__":
#DEBUG
DEBUG = False
#データのロード
df_monsters, df_quests, df_quantity, df_value_items = Load_csv()
#ランダムの設定
random.seed(20)
#クエストの選択(ランダム選択)
select=[]
#検証用select
select = [0, 7, 12, 17, 23, 28, 32, 37, 46, 49, 57, 58, 63, 66, 72, 78, 82]
#ランダムにクエスト選択
#df_quests_selected = Select_quest(df_quests,S=select)
#マニュアルのクエスト選択
df_quests_selected = Select_quest_manual(df_quests,selected_index = select)
#選ばれたクエストの表を作る
df_res = pd.DataFrame([],columns = ["number","member","prob","profit","profit_200","questName","member_name"])
for i,name in enumerate(df_quests_selected.quest_name_unique.tolist()):
maxValue = Obj_func_profit(200,i,df_quests_selected,df_value_items)
df_res = df_res.append(
{"questName": name,"number":i,"member":[],"prob":0,"profit":0,"profit_200":maxValue}
,ignore_index=True)
#理想的なリストが大きい順に並べる
df_res = df_res.sort_values(by="profit_200",ascending=False).reset_index(drop=True)
print(df_res)
#最適化
df_res,prob_transition,value_transition = optimize(df_res,iter=2000)
#推移の可視化
plot_transition(prob_transition, "probability transition", [0,200], "prob_transition")
plot_transition(value_transition, "value transition", [0,1], "value_transition")
#ゲーム画面で並んでる順番に戻す
df_res = df_res.sort_values("number",ascending=True).reset_index(drop=True)
print(df_res)
print("sumOfvalue={}".format(df_res.profit.sum()))
df_res.to_csv("./output/{}_result.csv".format(day8()))
結果
出力される内容は以下です。
76%|█████████████ | 13/17 [14:34<04:36, 69.08s/it]
クエスト ハードなキャンプ巡回1 で 再生 が足りません
クエスト ハードなバトル訓練4 で 傷 が足りません
100%|█████████████████| 17/17 [16:55<00:00, 59.73s/it]
number member prob profit profit_200 questName member_name
0 0 [7, 11, 27, 42] 165 95.7 116.00 アトラス_秘境の宝さがし [狂犬, カタ獣, トラ柄トゲミミザル, ビーバー・つー坊]
1 1 [3, 8, 33, 49] 155 6.5825 11.15 熾烈なバトル訓練2 [クスメット, グラスグース, ハサメット, 冒険者ガンボル]
2 2 [22, 28, 29, 53] 148 2.16 4.50 熾烈なキャンプ巡回1 [ピョコノコ, カモノソ, トラガンボル, 吸血スライム]
3 3 [9, 25, 44, 50] 150 10.25 10.50 トーテムタフ_トーテムタフの端-フィールド調査 [緋狼, 茶狼, クロワッサンガンボル, オバネムシ]
4 4 [1, 14, 21, 32] 160 5.04 8.24 特級材料収集3 [碧狼, サーパン, トパス, はらぺこ湖ドロリ]
5 5 [12, 20, 40, 58] 165 50.91 77.16 トーテムタフ_エリア探査 [ビーバー・たー坊, ノミカレハ, アテナガンボル, 乙女ガンボル]
6 6 [34, 52, 54, 66] 89 0.1869 0.21 高級食料貯蔵1 [アクダマ, 巨大サソリ, ハダカワタネズミ, グライピオン]
7 7 [10, 13, 24, 51] 140 2.32 2.56 トーテムタフ_端-フィールド調査 [ポブ, アカクタス, 小グル獣, かじり草]
8 8 [2, 5, 23, 39] 190 98.14 108.14 青空草原_秘境の奥へ [コケマル, ビーバー・あー坊, パック, ピョコノコママ]
9 9 [] 0 0 0.89 ハードなバトル訓練4 NaN
10 10 [6, 26, 38, 48] 165 2.3675 2.49 青空草原_石碑群-フィールド調査 [アカイッカク, ピョコノコママ, ブタバナ, サンタガンボル]
11 11 [19, 31, 43, 46] 145 1.04 2.14 高級材料収集1 [ノミクサ, ハキダシリュー, 炎尾トカゲ, 剣士ガンボル]
12 12 [] 0 0 2.12 ハードなキャンプ巡回1 NaN
13 13 [35, 36, 37, 63] 136 2.228 2.42 アトラス_前線基地-フィールド調査 [野生の子ワニエル, ウキウミクラゲ, ワタネズミ, かじり草]
14 14 [4, 15, 18, 47] 200 50.6 50.60 アトラス_エリア探査 [ブタバナ, トゲミミザル, ノミクサ, 魔物ガンボル]
15 15 [16, 17, 61, 65] 96 0.144 0.15 中級食料貯蔵1 [ドングリコ, ドングリコ, サンタガンボル, ハダカワタネズミ]
16 16 [0, 30, 41, 45] 200 2.35 2.35 さえずり峡谷_ルーン学院-フィールド調査 [ホネバット, ワニエル, 乙女ガンボル, 赤ずきんガンボル]
sumOfvalue=330.0189000000001
-
questName: クエストの名前 -
member,member_name: クエストに派遣するモンスターたち -
prob: モンスターをクエストに派遣した時の成功確率 -
profit: 重み付きのアイテム期待値 -
profit_200: もし成功確率が200%だったらの仮定のアイテム期待値 -
sumOfValue: 重み付きアイテム期待値の総計。これが高いと良い。
まあまあじゃないでしょうか?probが0になっている行はモンスターが足りず計算できなかったクエストですね。
各クエストの期待値の推移
各クエストで2000回回す過程のprobと、profit/profit_200の値をプロットしたものがこちら
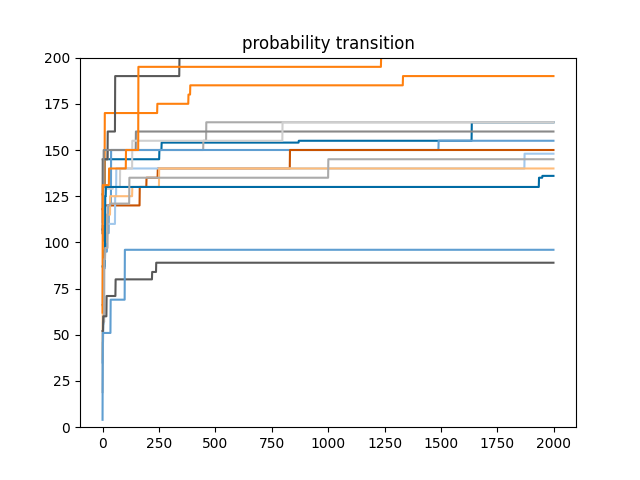
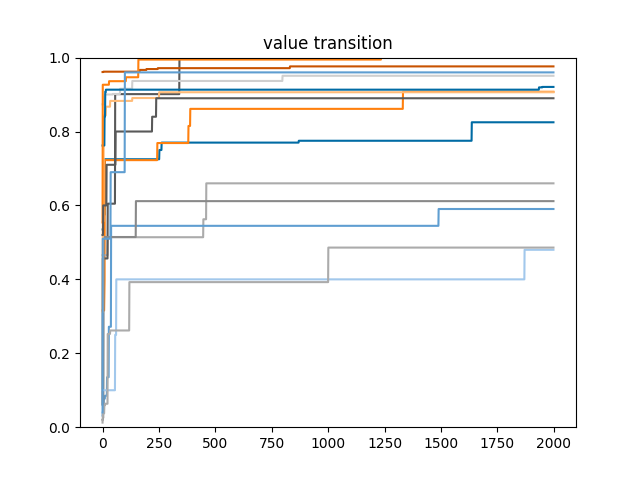
やはり乱択なので回数増やしたらまだ確率上がりそうな気も・・・悩ましいですね。
ちなみに計算に要した時間は17分程度でした。朝仕掛けて通勤したりするのにはきついですね・・・
クイック編成との比較
クエスト選択の順番(クエストで得られるアイテムの価値が大きい順)を揃えて、クイック編成を使う場合と今回の最適化と理想を比較します。
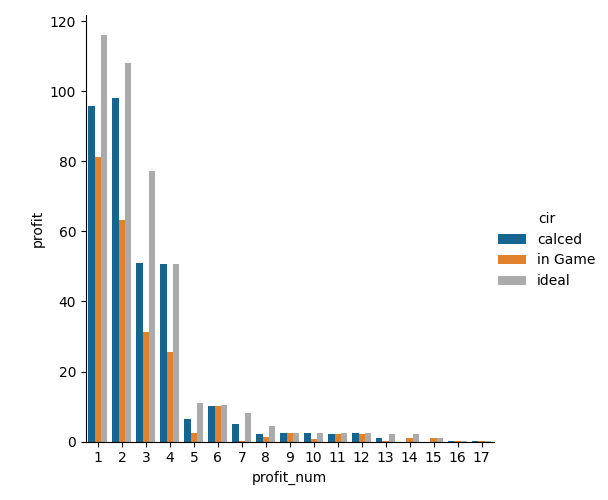
in Gameのクイック編成のものよりprofitが大きいので
かなりいいのではないでしょうか?
ちなみに合計値はcalcedが330.0189でin Gameが225.4828です。自分の作成した重みで考えるとガチャ石10個分の勝ちになりました。
結論
- Gurobipyなどの最適化ソルバーを使っての最適化は、相当モデルを単純にしたり計算的工夫を行わないと難しい(今回のものも方法はあるかもしれない)
- 目的関数さえ作れれば乱択で結構性能は出る
- ゲーム内でのクイック編成のアルゴリズムはどうなってるんだろうか・・・
今後の目標
- どの技能が不足しているのか->今後どのようにモンスターを育成していけばいいのかわかるようにする
- 貪欲法ではなく全体を考慮しながら期待値を最大化する方法を考える
感想
- ずっとやりたかったことを冬休みの自由研究的な感じ(実働3日)でできたのでよかった
- ソルバの勉強のモチベが地味に下がった
20230305追記
ゲームの方でアップデートがあり、クイック編成の精度が向上しました。比較したところ、今回のアルゴリズム以上の結果が得られ、計算時間についてもiPhone13で一瞬かくつく程度で済んでいるので使えるレベルになっております。喜ばしい。あとアルゴリズム教えてほしい・・・
全体最適化は今後もやりたいなーと思っていますがひと段落とさせておきたいと思います。