snowflakeとは(AIの回答)
Snowflakeは、クラウドベースのデータプラットフォームで、以下のような特徴を持っています:
1. クラウドネイティブなデータウェアハウス/データレイクソリューション:
クラウド上でデータの保存、処理、分析を行うプラットフォームです。
2. 独自のアーキテクチャ:
ストレージ、コンピューティング、クラウドサービスの3層が物理的に分離され、論理的に統合されています。
3. 高速なデータ処理:
独自のアーキテクチャにより、大量のデータを高速に処理できます。
4. スケーラビリティ:
データ量や利用者数の増加に柔軟に対応できます。
5. データシェアリング機能:
組織内外でのデータ共有が容易に行えます。
6. マルチクラウド対応:
複数のクラウドプラットフォーム上で利用可能です。
7. セキュリティ機能:
高度なセキュリティ機能を備えています。
8. 多様なワークロードサポート:
データエンジニアリング、データウェアハウス、データレイク、データサイエンスなど、様々なデータ関連タスクをサポートします。
9. 柔軟な料金体系:
データ量に応じた料金設定となっています。
Snowflakeは、企業がデータを効率的に管理、分析し、ビジネス価値を創出するのを支援するプラットフォームとして広く利用されています。
新しいデータベースの型(VARIANT)について
このsnowflakeでは、JSON型でのデータ保存が出来ます。
先輩から聞いた話ではありますが、実に興味深い!!
ということで、実際にデータを入れてみましたので、記事にいたします。
テーブルの作成
1.[Databases]の[PUBLIC]から、[Create]の[Table]→[Standard]をクリック
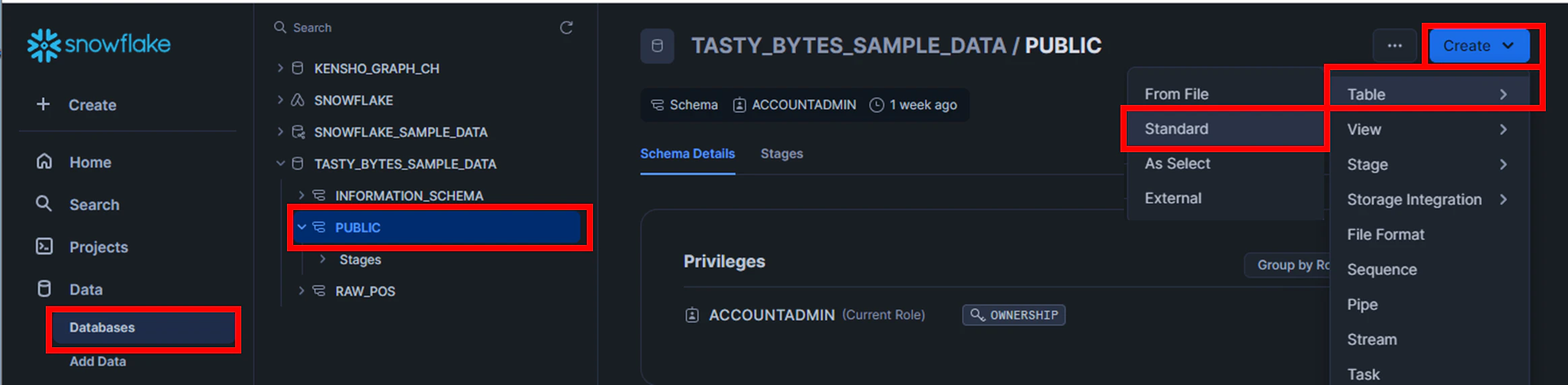
2.Create文を作成→実行
create table SAMPLE_TABLE1 (
JSON_VALUE VARIANT
)
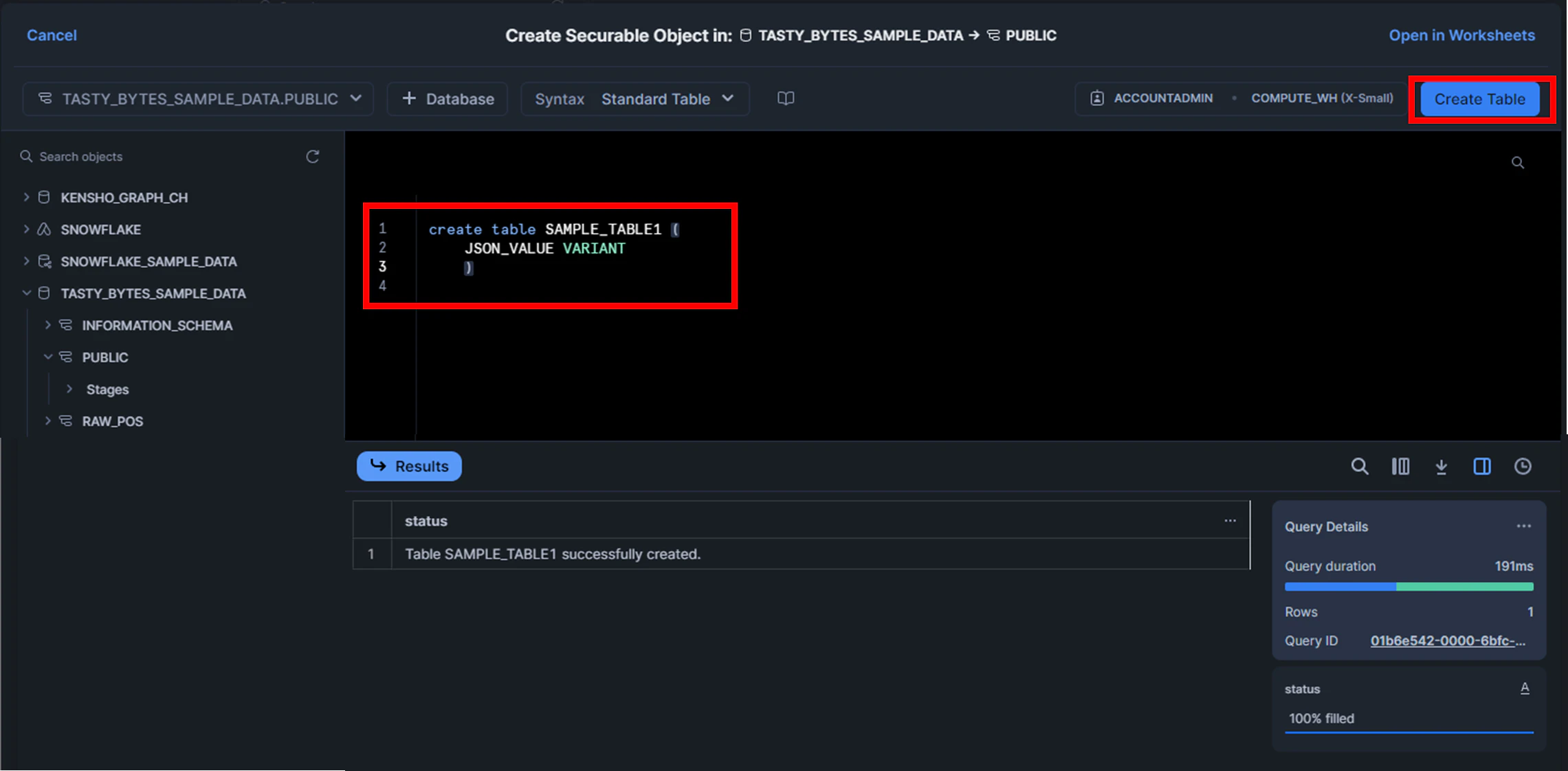
これでテーブルの作成が出来ました。
3.テーブルの確認
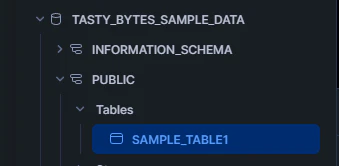
データの登録処理
JSONファイルを用意してもいいのですが、せっかくなので、snowflakeのコンソール(?)上で使えるPythonを使ってみましょう。
1.[Projects]の[Worksheets]から、[Create]の[Python Worksheet]をクリック
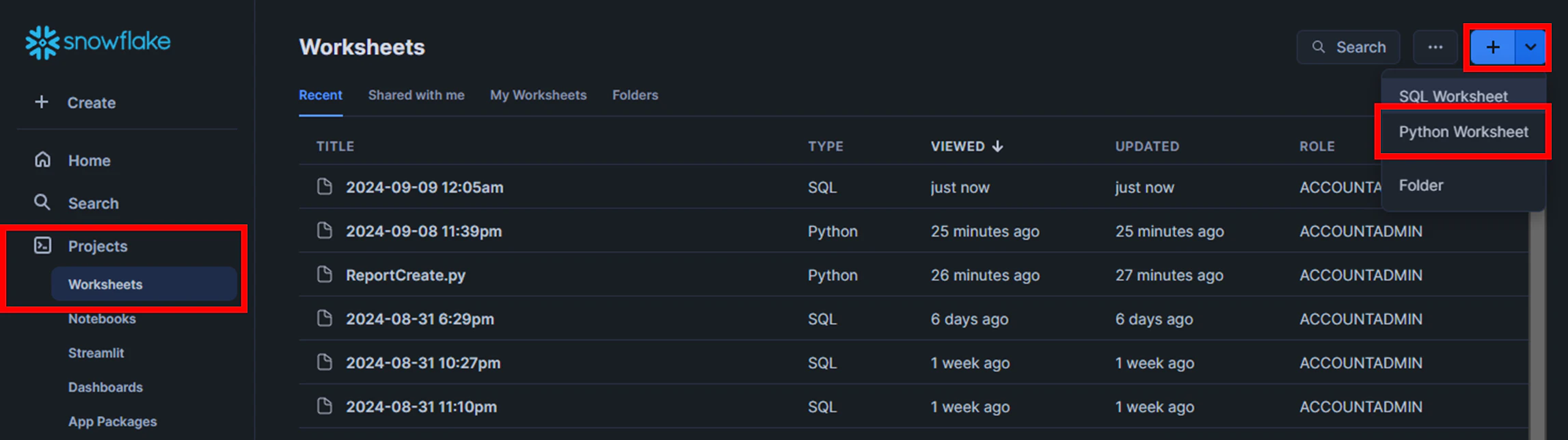
2.新規作成すると、標準のサンプルプログラムが表示されます。
いくつか制約はあるみたいで、main関数の定義が必須だったり、returnしなければならないなど。
細かいところはAIにでも聞いていただけると。
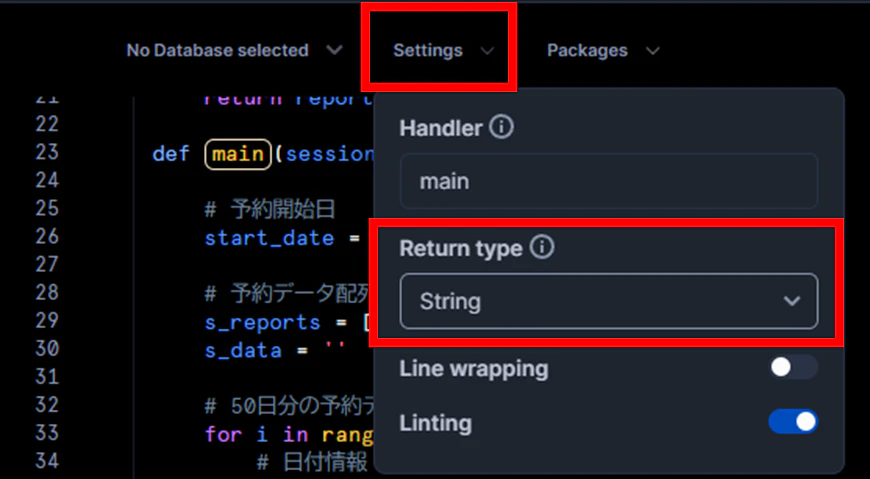
3.PGを作る前に、戻り値をプロパティとして設定する必要があるので、先に設定しておきます。
今回作るプログラムでは、戻り値は不要なのですが、わかりやすく文字列にしておきます。
4.ということでまずはJSONデータを作りましょう。
テーマは、予約データをJSONファイルで作成します。
イメージ:
{
"date": "2020-01-01",
"name": "清水 明"
}
結構、試行錯誤して色々試した結果となります。
# The Snowpark package is required for Python Worksheets.
# You can add more packages by selecting them using the Packages control and then importing them.
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
from snowflake.snowpark.functions import parse_json
from snowflake.snowpark.types import StructType, StructField, VariantType
import randomTASTY_BYTES_SAMPLE_DATA.PUBLIC.SAMPLE_TABLE1
import json
from datetime import datetime, timedelta
def generate_random_report(date):
# 名前をランダムを取得する元データ
names = ["佐藤 太郎","鈴木 花子","高橋 一郎","田中 美咲","伊藤 健太","渡辺 直子","山本 大輔","中村 由美","小林 優","加藤 さくら","吉田 亮","山田 友美","佐々木 陸","山口 美紀","松本 陽介","井上 結衣","木村 健","林 佳子","斎藤 翔","清水 明","山崎 亜美","森 俊介","池田 美和","橋本 拓海","阿部 由紀","石川 俊","山下 美香","田村 智樹","岡田 美奈","藤田 直樹","中島 恵","石井 大地","佐藤 由紀","高木 友介","宮崎 さやか","横山 祐樹","高田 ひかり","増田 健太郎","丸山 由香","杉山 雄太","大野 美咲","小島 直人","谷口 未来","今井 亮太","工藤 友香","田辺 直也","佐藤 里奈","中西 拓海","野口 美穂","武田 陽子"]
# JSONデータの作成
report = {
"date": date.strftime("%Y-%m-%d"),
"name": random.choice(names)
}
return report
def main(session: snowpark.Session):
# 予約開始日
start_date = datetime(2020, 1, 1)
# 予約データ配列の変数
s_reports = []
s_data = ''
# 50日分の予約データを作成
for i in range(50):
# 日付情報
current_date = start_date + timedelta(days=i)
# JSON変数に取得
j_data = generate_random_report(current_date)
# dumps関数で文字列に変換
s_data = json.dumps(j_data)
# 予約データを配列に保存
s_reports.append(s_data)
# 配列を元にデータフレームを作成
df = session.create_dataframe(s_reports, schema=["JSON_VALUE"])
# 列を設定するとともに、文字をjsonへ変換する。
df = df.withColumn("json_value", parse_json("json_value"))
# テーブルへデータを上書きとして登録
df.write.mode("overwrite").save_as_table("TASTY_BYTES_SAMPLE_DATA.PUBLIC.SAMPLE_TABLE1")
# 戻り値 OK
return 'OK'
5.つまずいた点をいくつか
- [3]の内容に気づかなくて、エラーの原因がわからなかったこと
- JSONの変数→テーブルのVARIANT型へ直接入れようとして、全然入らなかったこと
一度dumpsで文字にしてから、parse_jsonする手順がわからなかった。
これはなかなか難しかったけど、なんとか出来てよかった。 - マニュアル確認とAIへの質問をやりくりしても時間かかった。疲れた。
6.実行
上部の [Run] で実行!
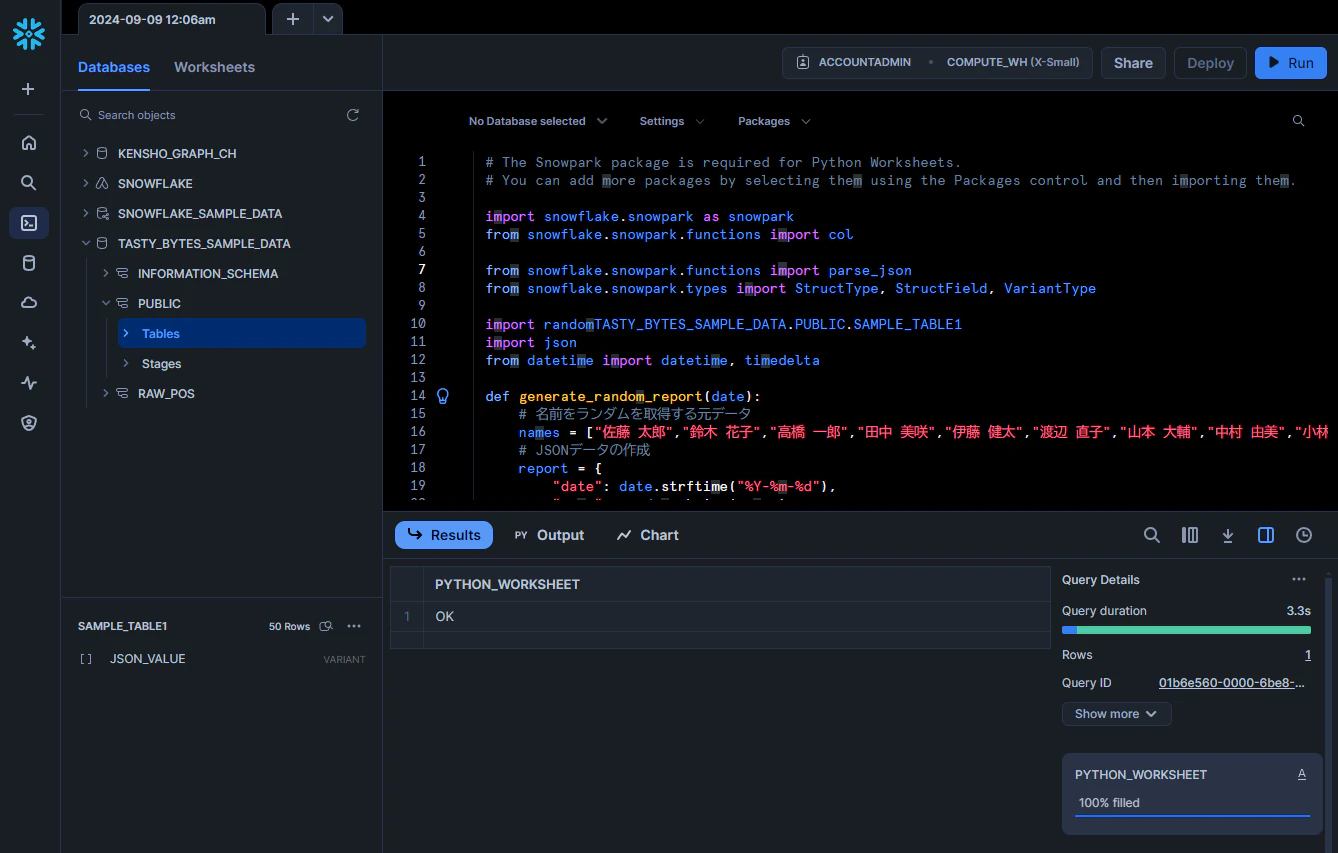
ResultsにOKが表示されれば、登録完了
7.データ登録後の確認
1.[Projects]の[Worksheets]から、[Create]の[SQL Worksheet]をクリック
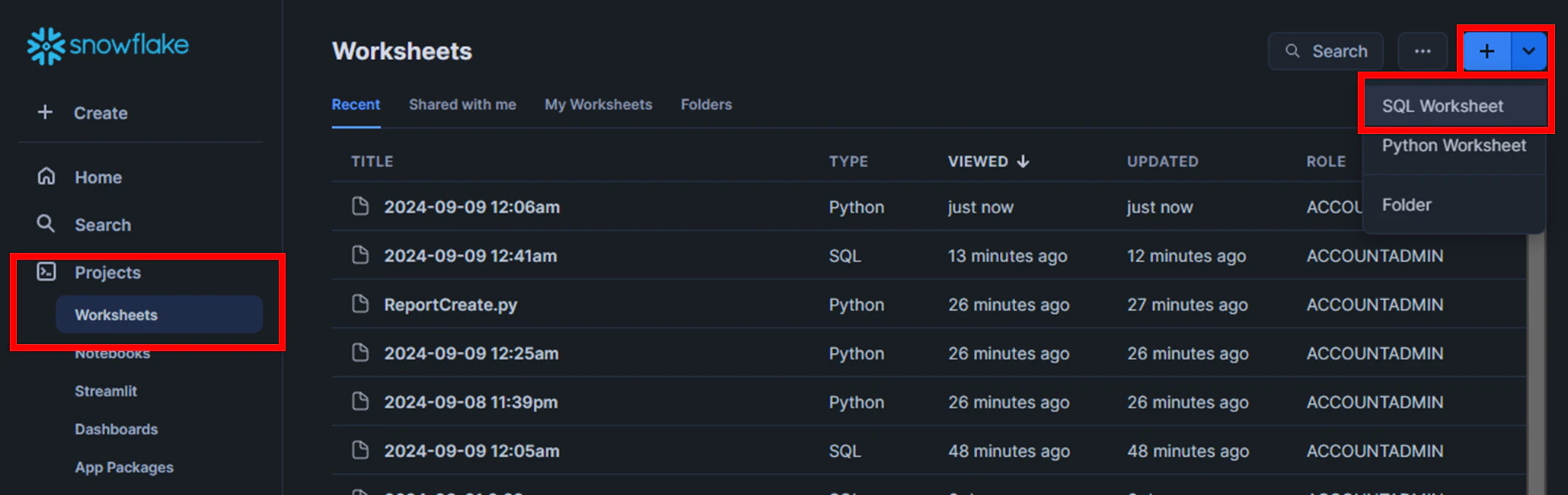
SELECT文を作成
select * from TASTY_BYTES_SAMPLE_DATA.PUBLIC.SAMPLE_TABLE1
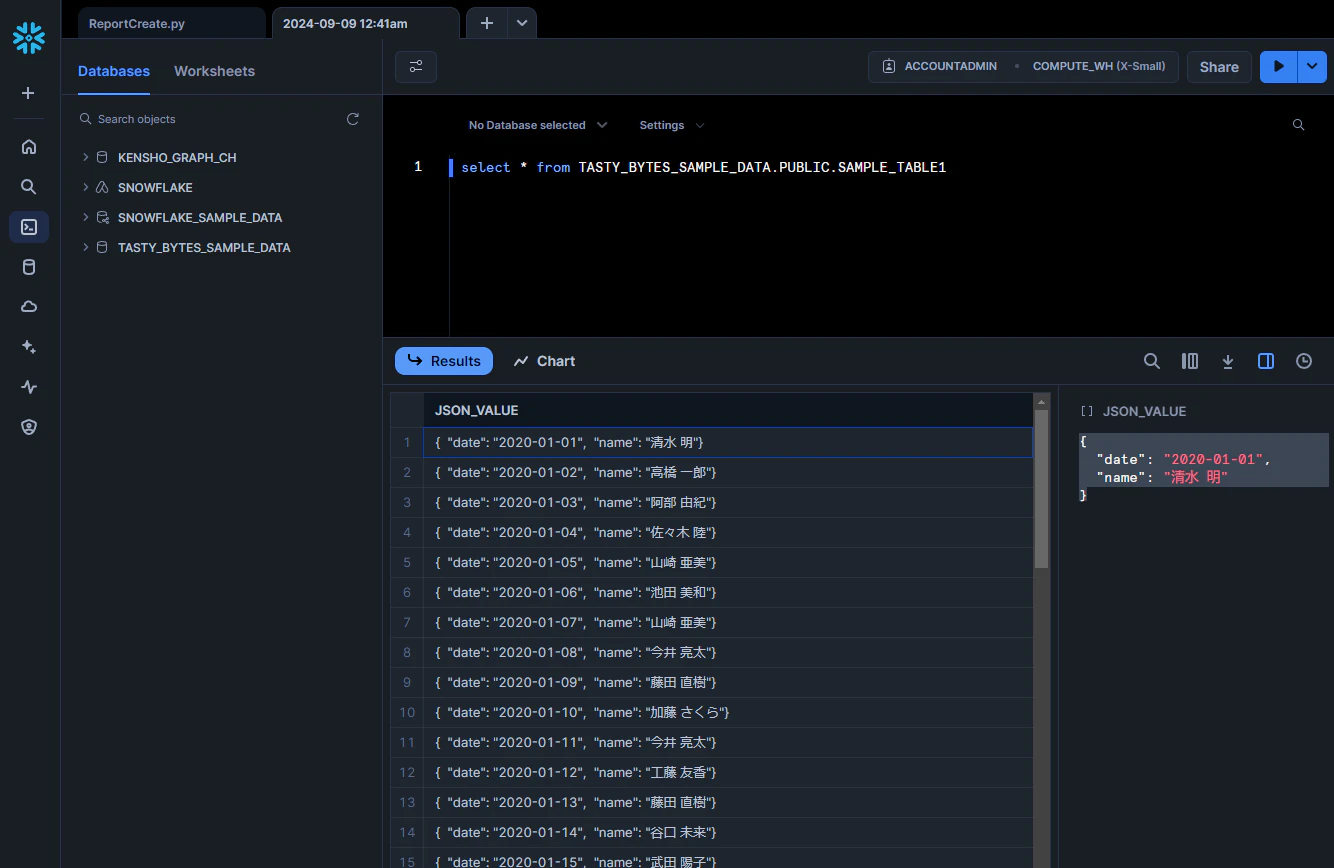
ということで、JSON_VALUEに値が入りました。
JSONをSELECTする方法
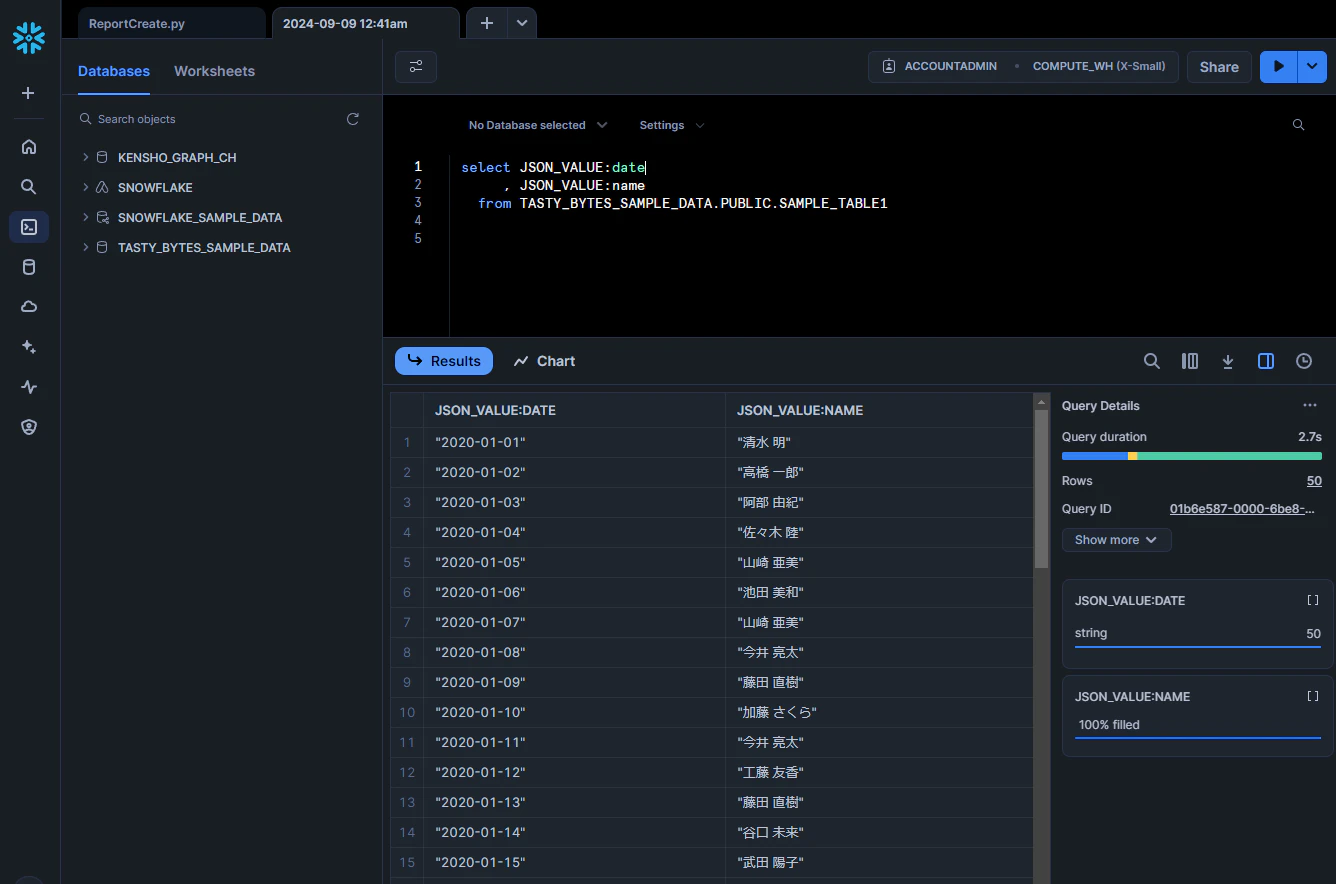
今回登録したデータを分解して列として取得することが出来ます。
select JSON_VALUE:date
, JSON_VALUE:name
from TASTY_BYTES_SAMPLE_DATA.PUBLIC.SAMPLE_TABLE1
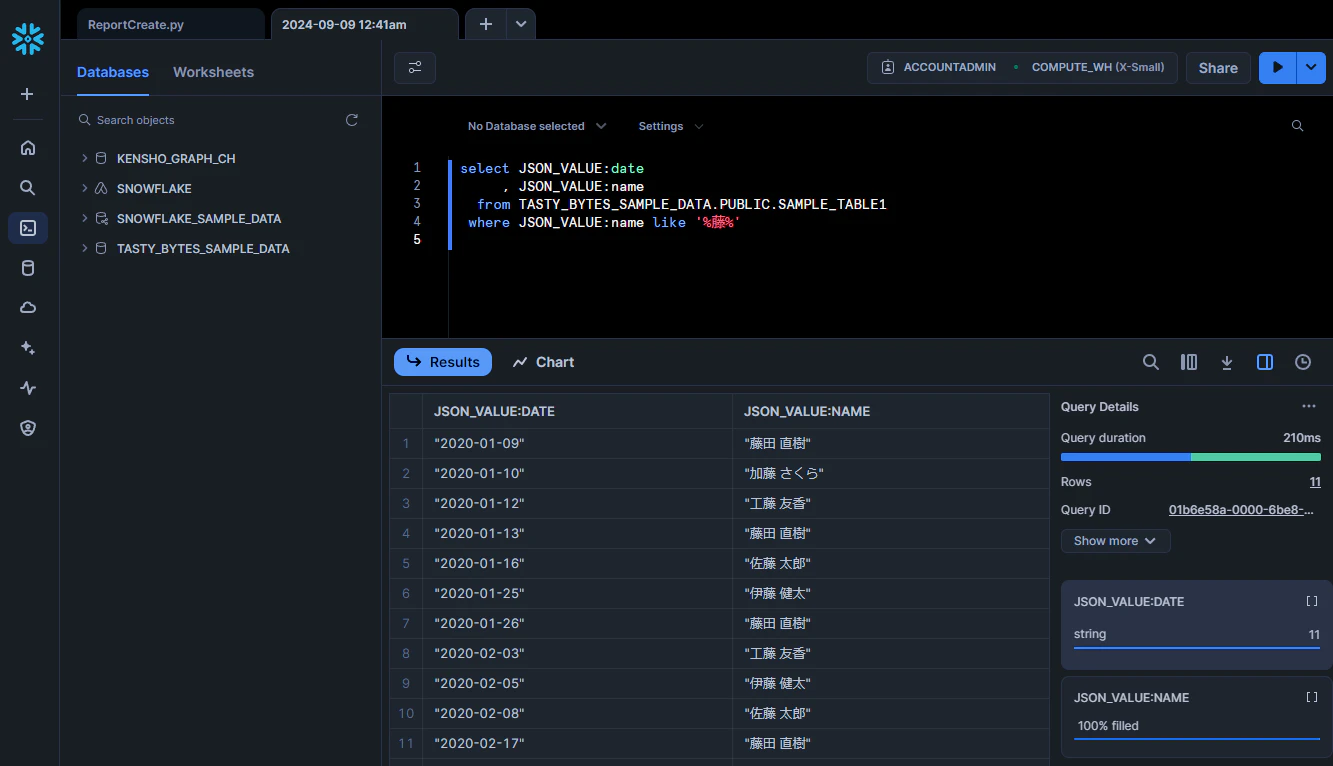
これが列で使えるということは、検索でも使うことが出来ます。
select JSON_VALUE:date
, JSON_VALUE:name
from TASTY_BYTES_SAMPLE_DATA.PUBLIC.SAMPLE_TABLE1
where JSON_VALUE:name like '%藤%'
一時期、XMLデータベースというような柔軟性をメリットに出したデータベースがありましたが、とうとう進化しました。
RDBの良さと柔軟性を兼ね揃えたのが、snowflake!
AI系の機能とかも搭載しているそうなので、今後も色々触ってみようかと思います。