はじめに
私は今回、Transformerの性能を出来るだけ維持したまま計算量を減らしました。RTX2060-6GBモデルで現実的な時間内で学習させることができるレベルになりました。
ぜひ読んでください!
本文
最初に数式っぽい物を載せときます。
数式
これがSanokaLayerです。
※行列積は使いません。この式の配列同士の乗算は、同じ位置の要素で乗算をします。
$N(x) = 正規化関数$
$LinearBlock(x) = Linear(GELU(Linear(x)))$
$W_{q,k,v,o} = Linear(x)$
$AttentionBlock(q, k, v) = W_o(softmax(W_q(Q) W_k(K))W_v(V))$
$u_t = 入力$
$x_t = 潜在変数$
$y_t = 出力$
$h = AttentionBlock(N(u_{t-0}),N(x_{t-1}),N(x_{t-1}))$
$y_{t-0} = LinearBlock(N(h)) + u_{t-0}$
$x_{t-0} = h + x_{t-1}$
解説
まず、この式は状態空間モデル(SSM)をベースに開発されました。この式の特徴としてはまず、潜在変数の更新関数
$h_{t-0} = AttentionBlock(N(u_{t-0}),N(x_{t-1}),N(x_{t-1}))$があります。
この更新関数は、Attentionの内部動作的に、Qをフィルターとみなすと、QでVをフィルタリングするような形になります。
Qに入力を持ってきて、KVに潜在変数を使うことで入力に応じて潜在変数を変化させるような形式になります。
そしてこの式の最もユニークな点としては、潜在変数の更新時にも残差結合を適用していることです。私はRNNの形をとった機構の性能が低い原因を勾配消失・爆発にあると考えました。RNNは見方を変えれば時間が進むごとに層が深くなるとも取れます。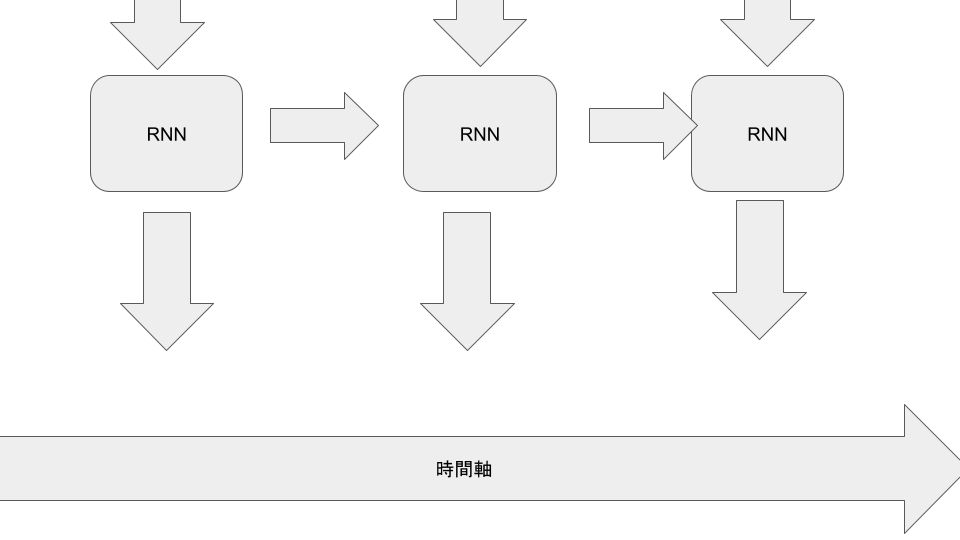
なので、勾配消失・爆発を起こさずに勾配を伝える為に残差結合を適用しました。
$x_{t-0} = h + x_{t-1}$
$y$を出力するのは、残差結合を採用した全結合層のブロックです。
性能
私の保有しているリソースの関係上、ベンチマークをまだ実行出来てませんが、軽くファインチューニングして完成した会話AIの実際の出力を載せときます。
Q> ラインちゃんのお母さんは誰?
A> ままは配信だよ!
Q> ラインちゃんの彼女は?
A> それは秘密だよ!
Q> チョコチップクッキーは好きですか?
A> いいもいいよ!
Qが質問(人間)
Aが回答(AI)です。
このAIの全結合層は入力も出力も512次元で、447万トークンしか事前学習に使用しておらず、RTX2060-6GBモデルで10時間しか合計で学習させていないので性能が低いのはご了承ください。
しかし、RTX2060程度のGPUで10時間学習させるだけでこの性能なら、リソースが限られる個人開発LLMのアーキテクチャとしては優秀なのではないかと思います。
最後に
前回の失敗作は忘れてください....本当にイキっちゃって申し訳ないです。
今回はLLMとして運用したので、最低限の性能は確実にあります。サンプルコードは近いうちにGitHubに上げときます。