【注】ステップバイステップでこれでもかこれでもかと完全な手順を記載しましたので、分量多めです。右側の目次を使いながらご覧ください。2時間あれば構築できます。
社内生成AIツール使ってくれない問題
「社内で使える生成AIツールを展開したのに、全然ユーザーが使ってくれない...」
誰も見てないダッシュボード同様、DX推進あるあるではないでしょうか?
このようなツールはリリースして満足しがちですが、最も重要かつ難しいのは、日々の業務に使ってもらうことです。以下のようなアプローチが考えられます。
- 業務プロセスに組み込んで、強制的に使われるようにする
- ユーザーが日々使うツールから利用できるようにし、ツールのアクセスコスト、学習コストを(ほぼ)ゼロにする
今回は日頃の業務コミュニケーションで活用しているツールSlackを窓口としたQ&A生成AIチャットボットを構築するという2.のアプローチをとり、「ユーザーに使われる生成AIツール」を構築します。Slackを窓口とすることで、同僚に相談する感覚で手軽に質問可能です。
今回構築するSlackを窓口にしたQ&Aシステム

<ツールの特徴>
- Slackを窓口とすることでユーザーはアプリケーションへのアクセスコストなし
- Slackのスレッドに回答するので、トピックがまとまり後で確認しやすい
- スレッド内の投稿履歴が利用されるので、チャットボットとインタラクティブに深掘りができる
- 格納ドキュメントは英語でも、日本語で回答してくれる
- コストは月数万円レベル(ほぼOpenSearch Serverless代)
アーキテクチャ
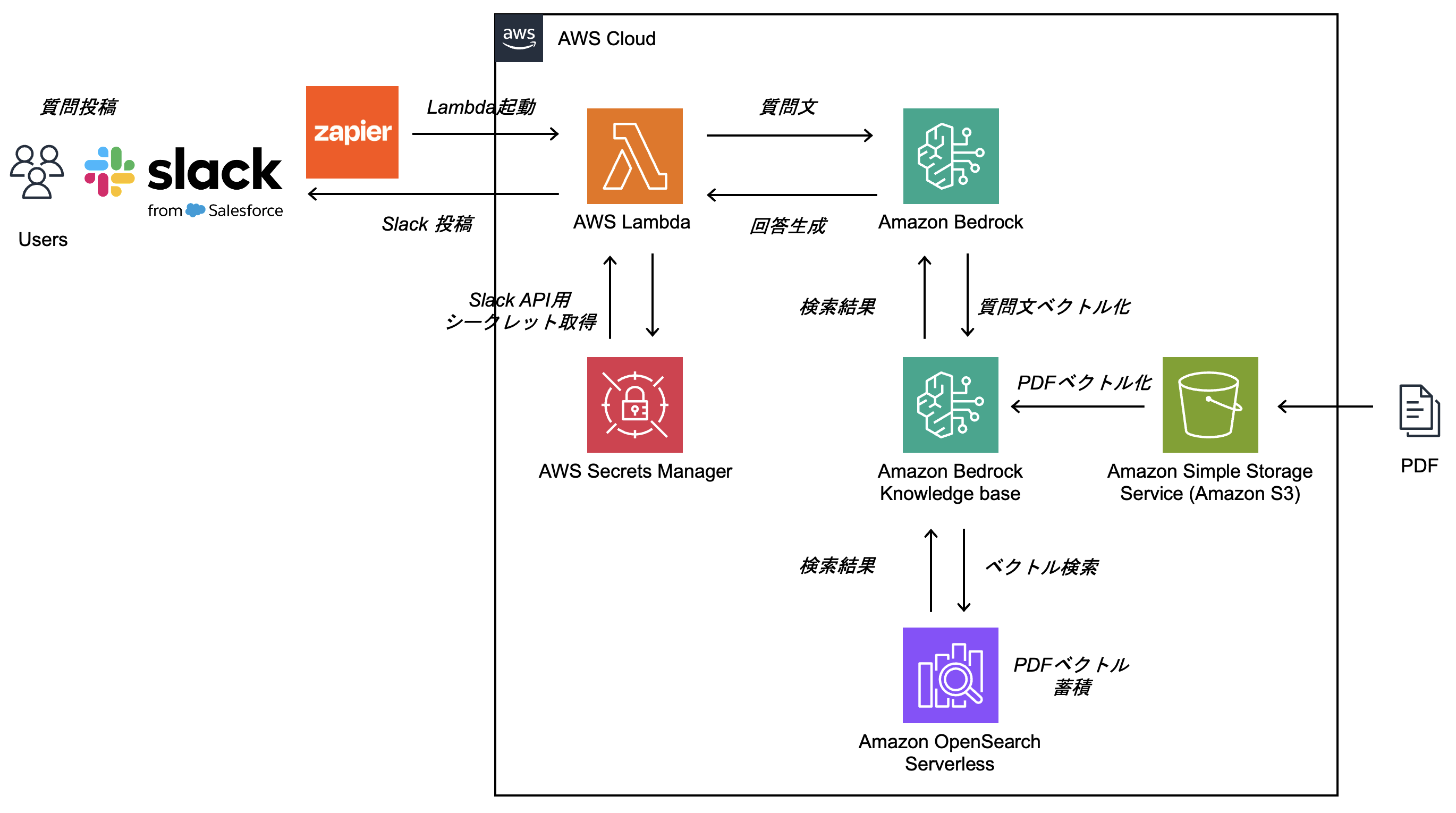
<事前準備>
- PDFファイルを Amazon Simple Storage Service(Amazon S3) に格納します。
- Amazon Bedrock Knowledge base の機能にて、PDFのベクトル化を行います。
- PDFベクトルは Amazon OpenSearch Serverless のVector Storeに格納します。
<処理の流れ>
- ユーザーはSlackに質問を投稿します。
- Slack投稿をトリガーにzapierが発火し、zapierはAWS Lambdaを起動します。
- Amazon Bedrock Knowledge baseの機能にて、質問文をベクトル化、Amazon OpenSearch Serverlessによるベクトル検索を実施し、検索結果から回答を生成します。
- AWS LambdaはAWS Secrets ManagerからSlack API用のシークレット情報を取得し、Slack APIを利用して生成された回答をSlackのスレッドに投稿します。
社内Q&Aシステム構築手順
このシステムを構築する手順を、(これでもかと)詳細に記載します。
1. RAGを構築する
まずは検索結果から回答を生成するRAGの仕組みを構築します。AWSの Knowledge Bases for Amazon Bedrock を利用します。作業対象は以下の赤枠です。

Knowledge base に格納するファイルは、ServiceNow Xanadu(ザナドゥ)バージョンのAI機能に関するプロダクトドキュメントです。
1-1. ファイルダウンロード
ドキュメントをPDF形式でダウンロードしていきます。
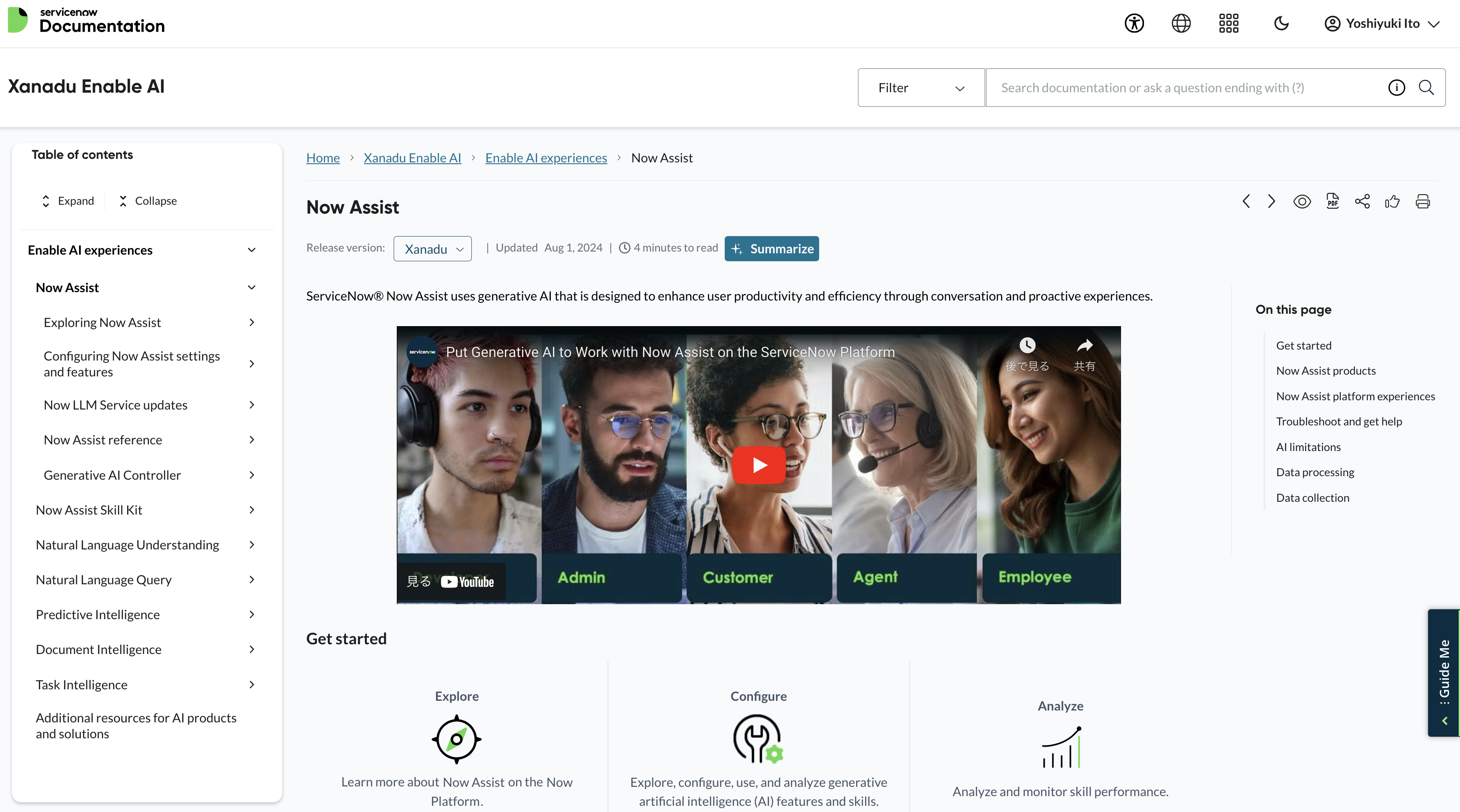
2024/8/11時点では日本語ドキュメントはありませんので、英語ドキュメントをダウンロードします。赤枠の Save entire publicationを押すと、セクション全体のPDFを取得できます。

548ページあります。かなりのボリュームですね。ServiceNowプロダクト全体のdocsは、数万ページにもなります。これはクラウドサービスの開発者ドキュメントと同様ですね。
1-2. ファイル容量削減
PDFファイルをダウンロードして、容量を確認します。

ファイルサイズが50MBを超えてしまいました。50MBを超えるとAmazon Bedrockで扱うことができないので、サイズを削減します。
今回は、MacBook Pro のPreviewアプリのサイズ削減機能を使います。
File > Export から、Quartz Filterで Reduce File Sizeを選択します。
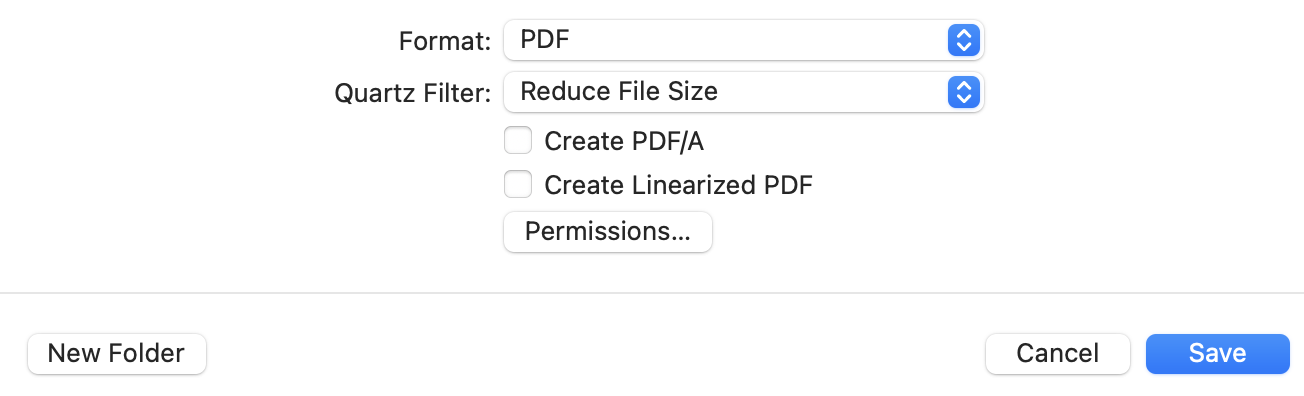
46.9MBになり、50MB以下に抑えることができました。50MBに収まらない場合は、ファイルの分割などを検討します。

1-3. Amazon S3 にPDFファイルを格納
サイズを小さくしたPDFファイルを、Amazon S3に格納します。
1-4. Amazon Bedrock Knowledge bases の構築
Amazon BedrockのKnowledge basesサービス画面に移動し、Create knowledge baseを選択します。

<設定>
Step1は、デフォルトのままNextをクリックします。

Step2は、S3 URIを入力します。
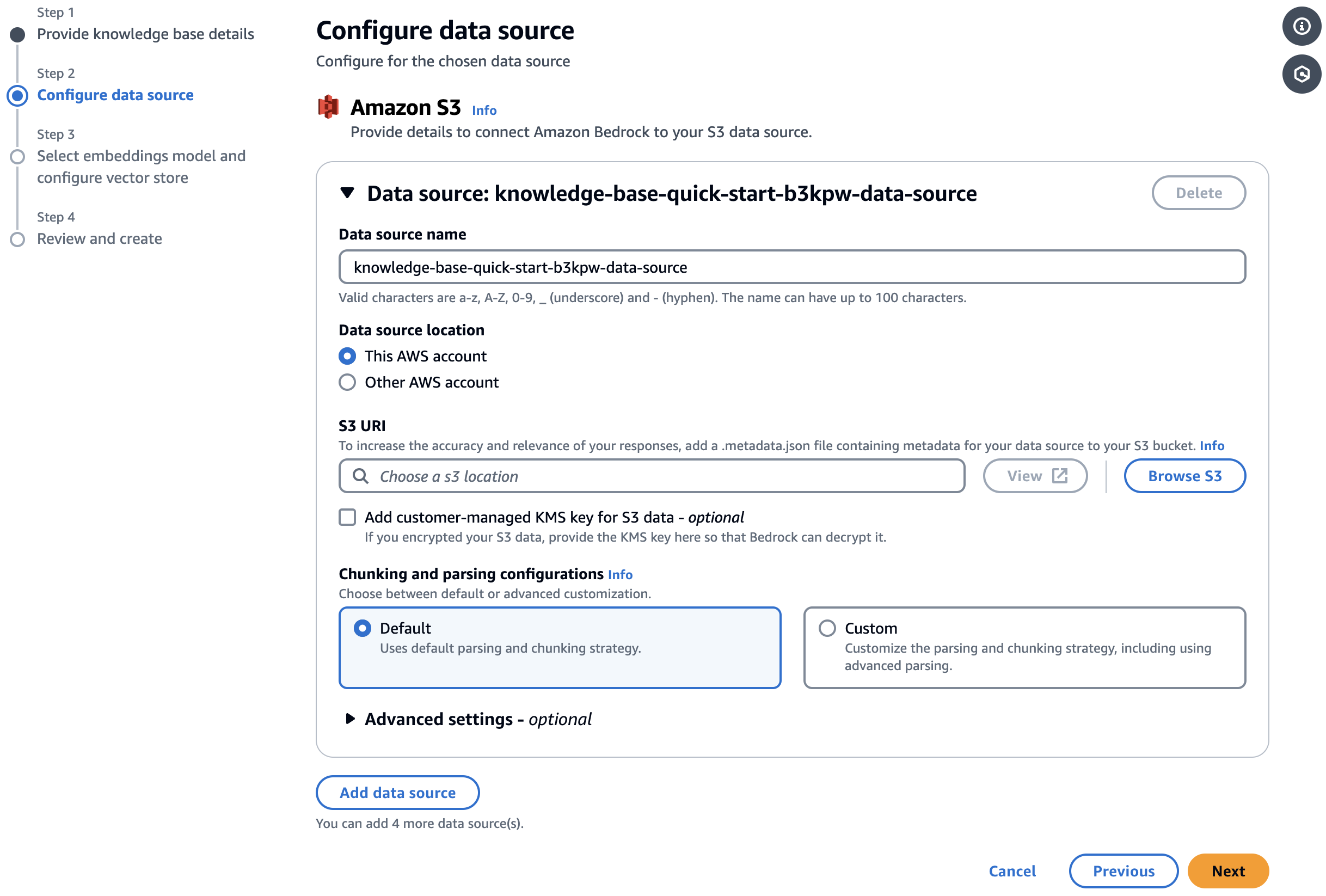
赤枠のように入力しました。

Step3は、Embeddings modelとして Titan Embeddings G1 - Text v1.2 を選択します。
Vector databaseはデフォルトのQuick create a new vector storeを選択します。Amazon OpenSearch Serverless vector storeが構築されます。
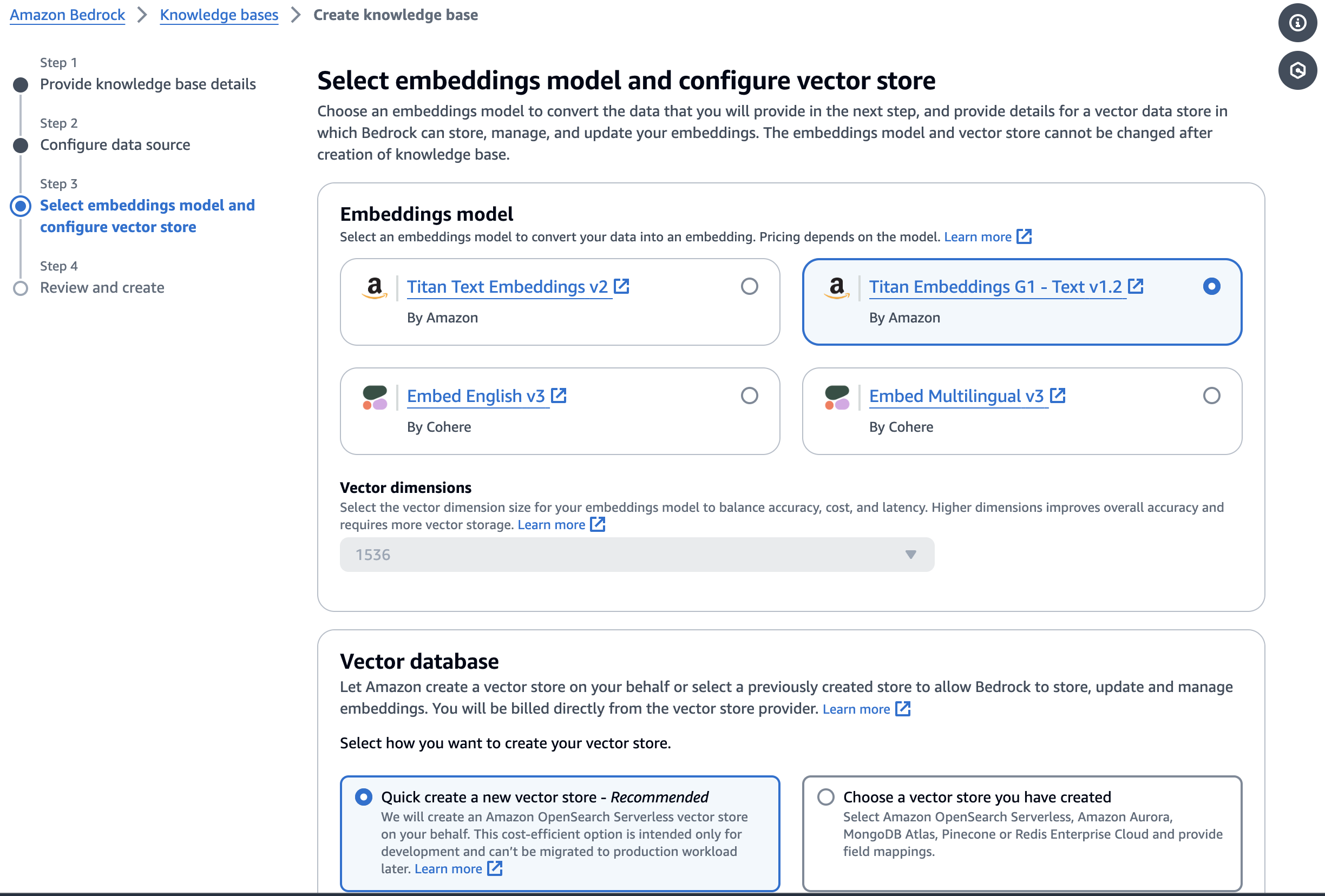
Step4は、設定した項目を確認し、Create knowledge baseをクリックします。

作成中になり、右下がくるくる回っています。しばし待ちましょう......

待つこと5分ほど、Knowledge baseが構築されました。
Knowledge base ID
は、後ほどLambda関数内で利用しますので、メモしておきましょう。
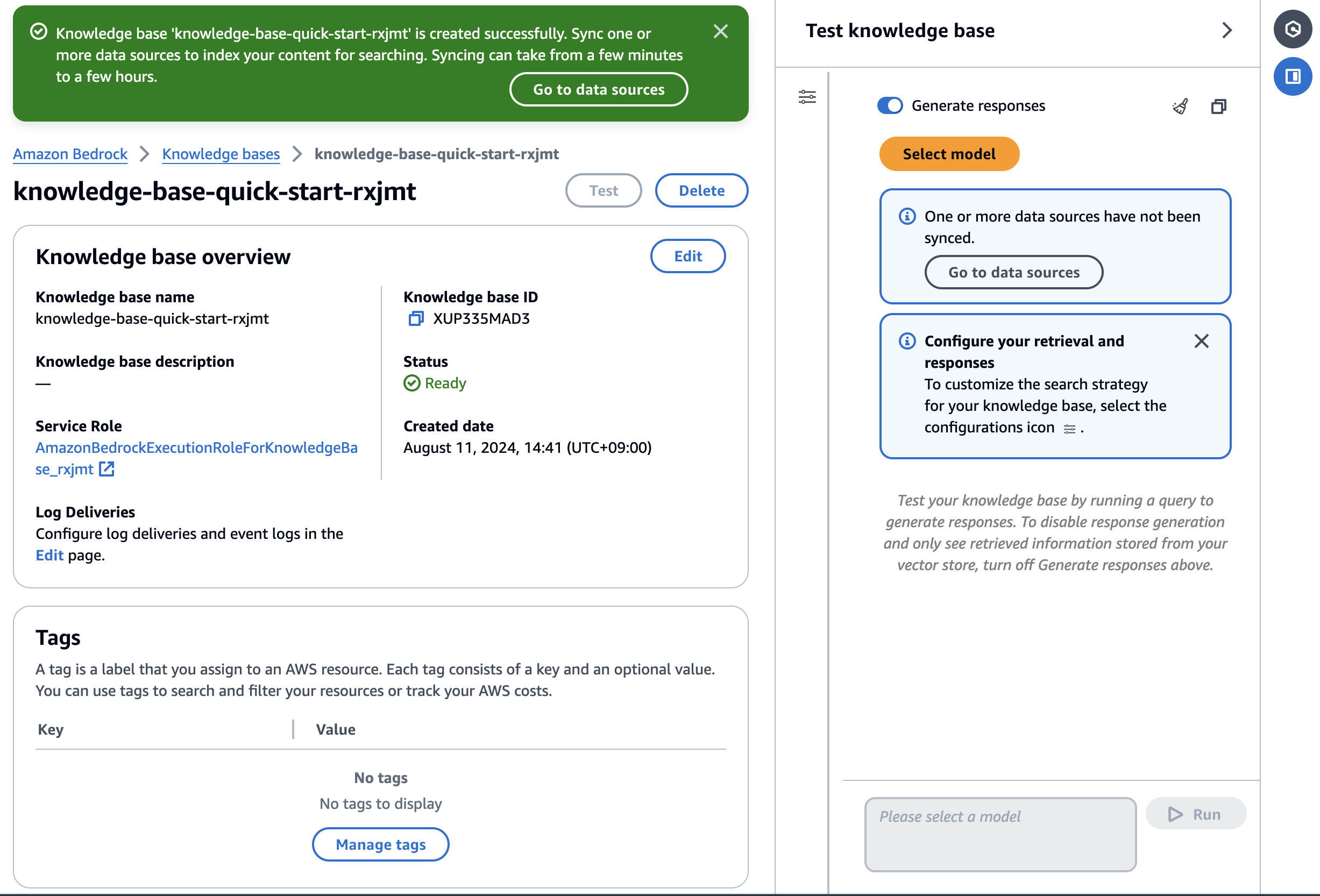
データソースを選択し、Syncを押します。Amazon S3のPDFが Titan Embeddings G1 - Text v1.2 によってベクトル化され、Amazon OpenSearch Serverless の vector storeに格納されます。

Syncが始まりました。

今回は1ファイルなので、数分で完了しました。
データソースをクリックして詳細画面で、Sync historyが確認できます。
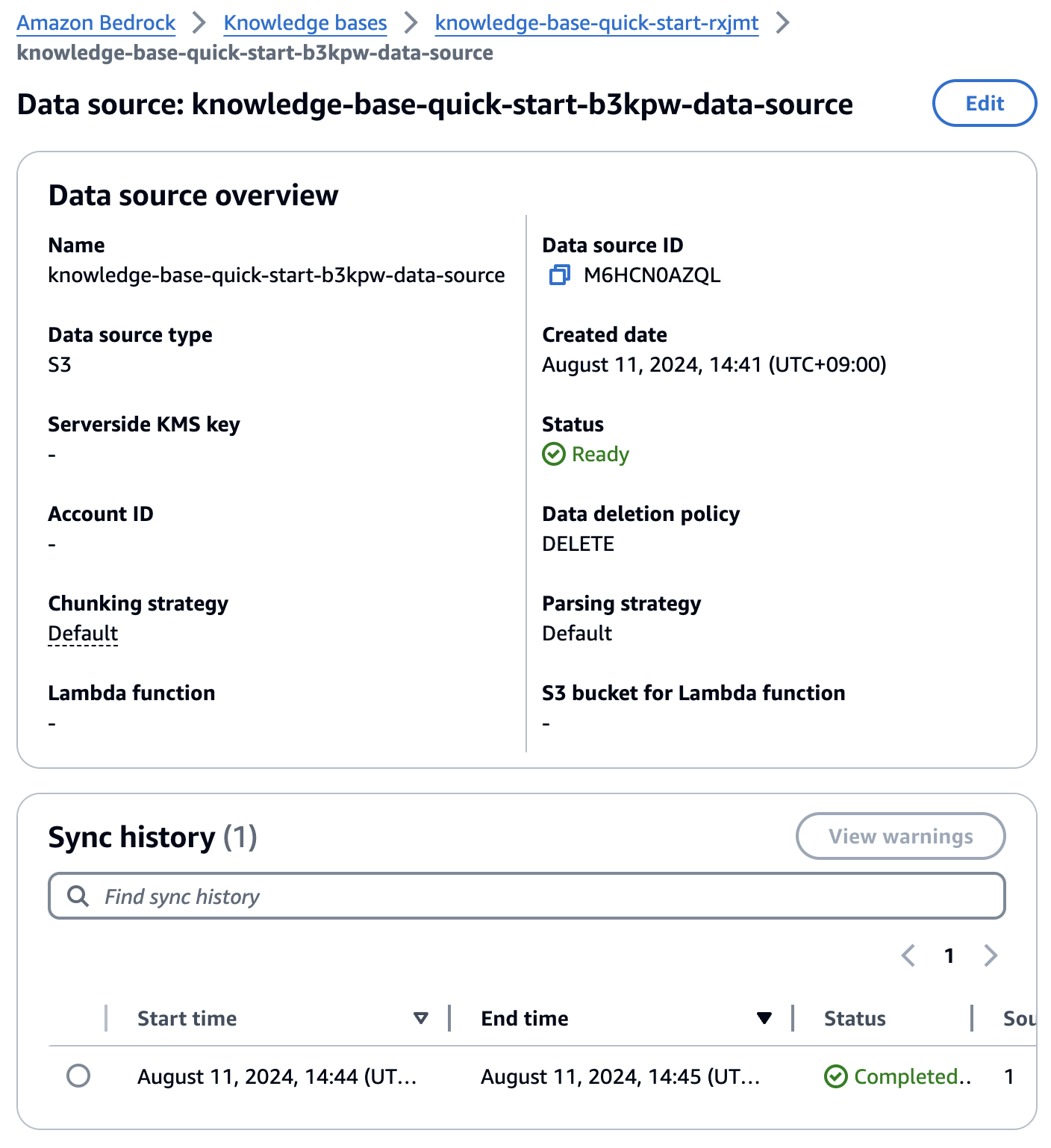
右側の Test Knowledge baseで動作確認してみましょう。
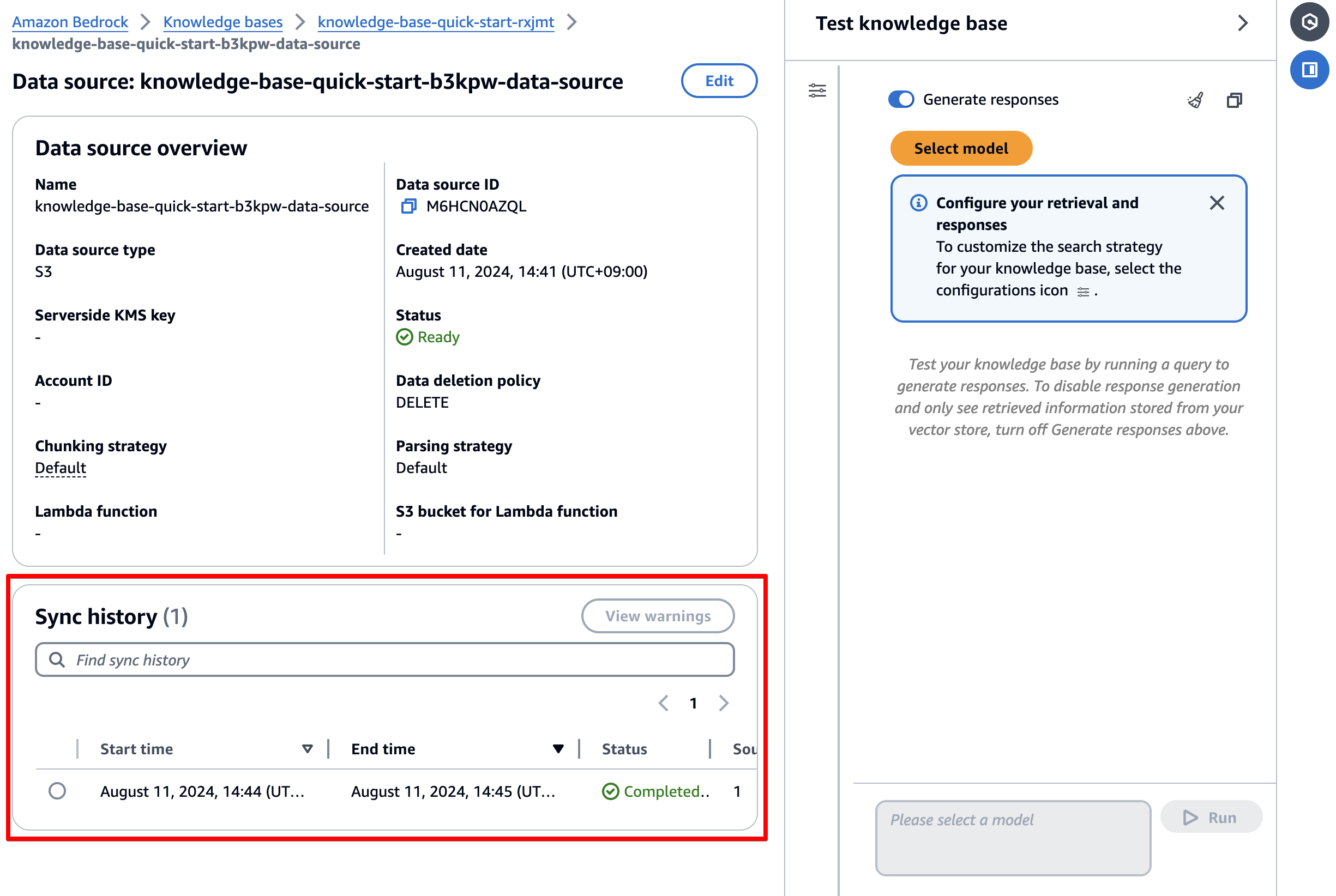
モデルは、AnthropicのClaude 3 Sonnetを選択します。
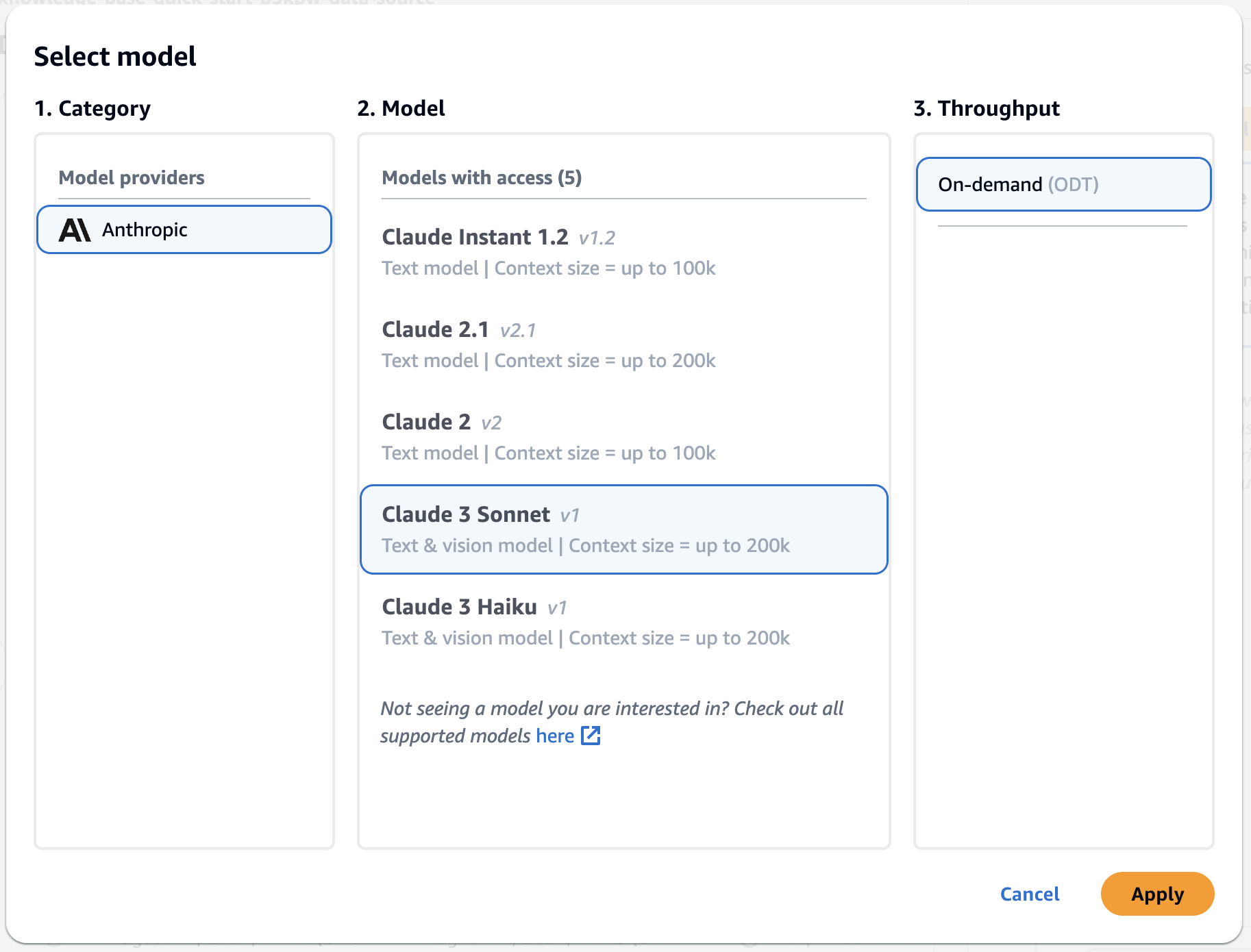
<質問>
ServiceNowのNLU modelを削除するために必要なロールは何ですか?またその手順は?

プロダクトドキュメントは英語なのですが、日本語で回答生成してくれました!!内容も正しいです。
次に、Knowledge baseを利用しない場合の回答も確認してみます。

nlu_adminロールが正解なので、この回答は誤りです。
手順も遠くから薄めでぼんやり見ると合っている風!ですが、近くで冷静にみたら間違っておりました。
他のLLMでも試しましたが、Knowledge baseのような具体的な回答はできませんでした。
ドキュメントを基にした具体的な回答ができるのは、RAGの価値ですね。
2. Slackを窓口にしたシステムを作る
では、Amazon Bedrockで作成したRAGを、Slackから利用するシステムを作っていきます。
アーキテクチャの赤枠が対象になります。

2-1. Slackの設定
まずは、RAGチャットボットが応答するチャネルを作成します。

デフォルトのままPublicとします。
Channel IDをメモしておきます。後でAWS Lambdaのコード内で利用します。

Slackにアプリケーションを追加する
Slack APIから、Slackアプリの新規作成ダイアログを表示します。
Create New Appを押して、新しいアプリを作成します。
From scratchを選択します。

App Nameを入力し、workspaceを選択します。
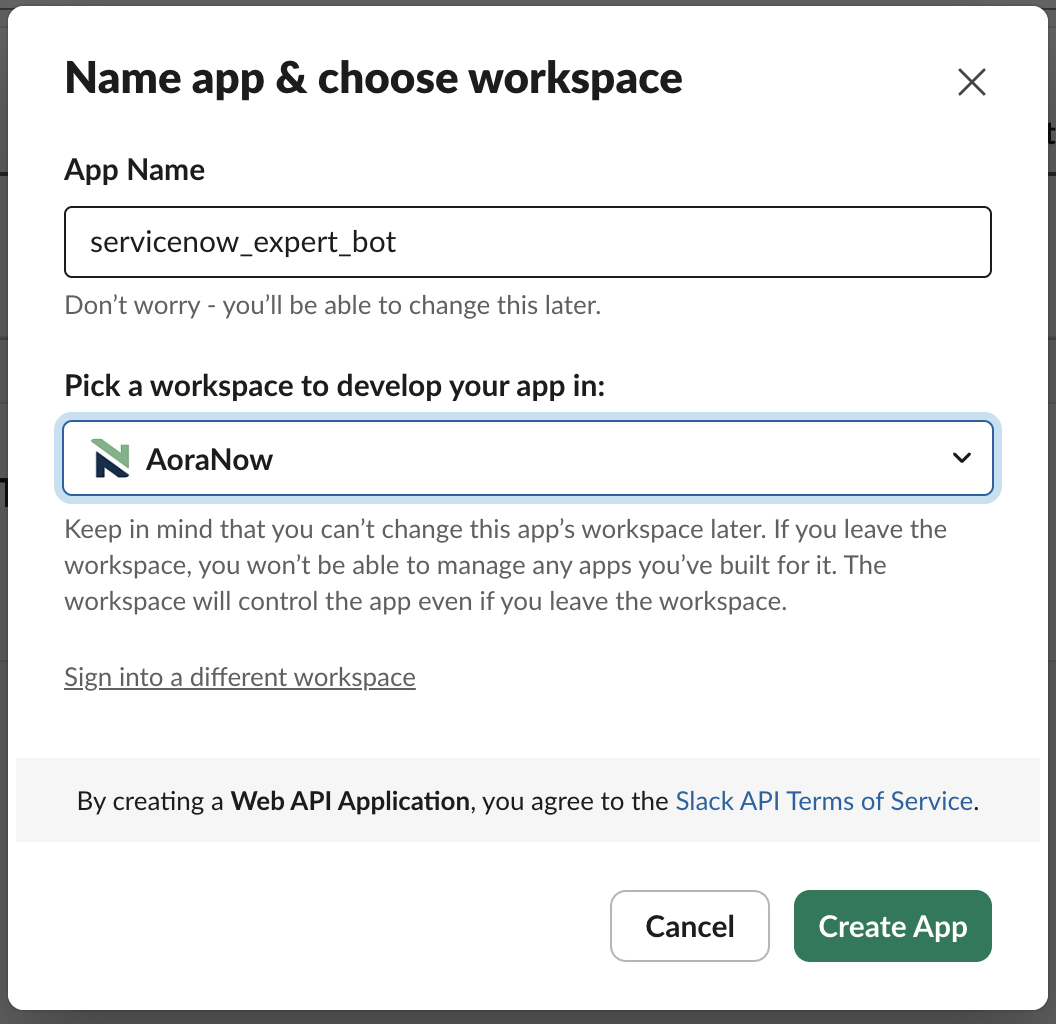
Basic Informationの、Permissionsをクリックします。

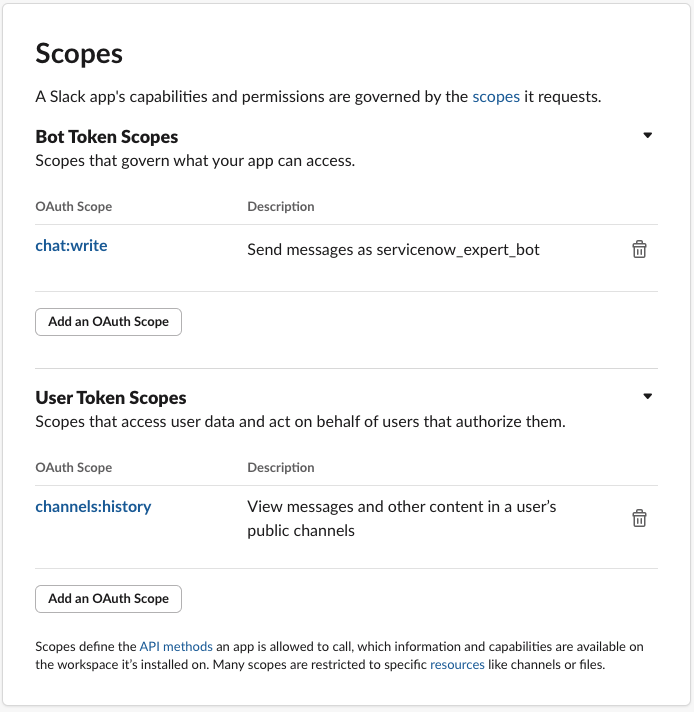
Bot Token Scopesと、User Token Scopesを設定します。

Bot Token Scopesに chat:write、
User Token Scopesに channels:historyを設定します。
ワークスペースにインストールします。

Allowを選択します。

User OAuth Token
Bot User OAuth Token
が発行されました。

このコードを、後ほど AWS Secrets Manager に登録します。
Slackチャネルにアプリケーションを統合
次に、作成したアプリケーションをSlackチャネルに登録します。
Slackチャネル詳細のIntegrationsから Add an App をクリックします。

作成したアプリケーションのAddをクリックします。

追加されました。

2-2. AWS Secrets Manager の設定
AWS LambdaでSlack APIのシークレットキーを使います。Slackのシークレットキーを安全に利用するために、AWS Secrets Manager を利用します。
Store a new secretをクリックします。

Secret typeでOther type of secretを選択し、
Slackの2つのキーを設定します。その後、Nextをクリックします。

Secret nameのみ入力してNextをクリックします。
そのままNextをクリックします。

review画面に遷移します。Python3のコードは後のLambdaで利用します。
Storeをクリックします。

表示されたPython3コードは以下です。(参考)
# Use this code snippet in your app.
# If you need more information about configurations
# or implementing the sample code, visit the AWS docs:
# https://aws.amazon.com/developer/language/python/
import boto3
from botocore.exceptions import ClientError
def get_secret():
secret_name = "slack_app_servicenow_expert"
region_name = "us-east-1"
# Create a Secrets Manager client
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
except ClientError as e:
# For a list of exceptions thrown, see
# https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html
raise e
secret = get_secret_value_response['SecretString']
# Your code goes here.
登録されました。

2-3. AWS Lambdaの設定
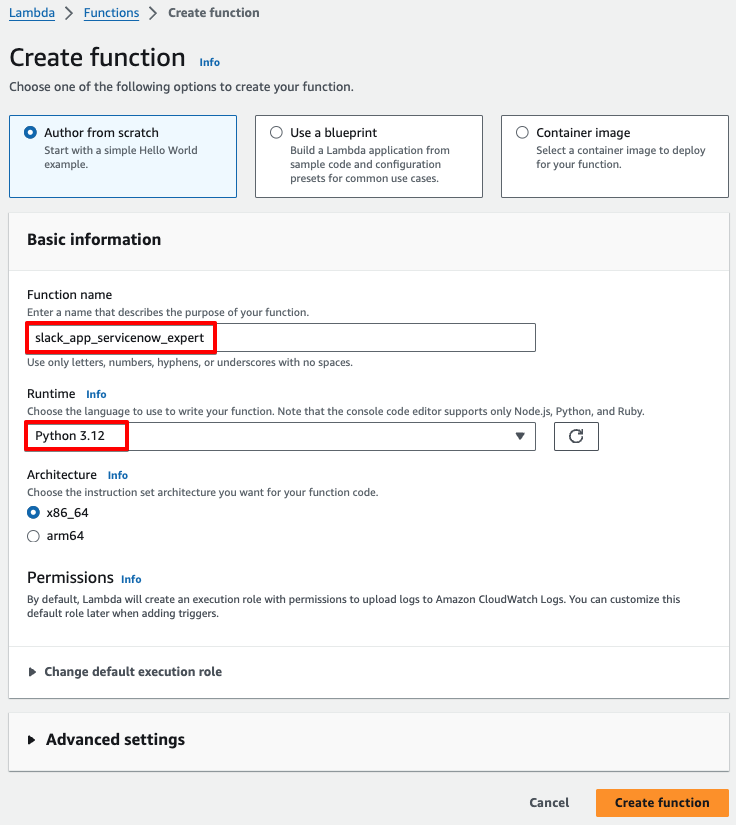
処理の中核である、AWS Lambda を構築していきます。Create a functionをクリックします。

Function nameと、Runtimeを入力します。
以下のソースコードをlambda_function.pyにコピペします。
<以下は環境に合わせて修正してください>
- cid = 'C07H38BSFRN' # 要修正1:SlackチャンネルID
- region_name = "us-east-1" # 要修正2:リージョン設定
- region = "us-west-2" # 要修正3:リージョン設定
- kb_id = 'XUP335MAD3' # 要修正4:Knowledge base ID
- region = "us-east-1" # 要修正5:リージョン設定
AWS Lambdaのコード: lambda_function.py
import json
import os
import re
import urllib.request
from datetime import datetime
from urllib.parse import urlparse
import boto3
from botocore.exceptions import ClientError
# Lambda関数のメインハンドラー
def lambda_handler(event, context):
cid = 'C07H38BSFRN' # 要修正1:SlackチャンネルID
key_to_retrieve = 'thread_ts'
# イベントにthread_tsが含まれているかチェック
if key_to_retrieve in event:
thread_ts = event[key_to_retrieve]
# Slackユーザートークンを取得
slack_user_token = get_secret(
"slack_app_servicenow_expert",
"User_OAuth_Token"
)
# Slackスレッドの履歴を取得
response = get_slack_thread_history(cid, thread_ts, slack_user_token)
# 会話を抽出
conversation = extract_conversation(response)
# 会話をフォーマット
formatted_conversation = format_conversation(conversation)
# タグ付きセクションを削除
formatted_conversation_wo_ref = remove_tagged_sections(
formatted_conversation
)
# プロンプトを作成
prompt_pre = (
f"あなたはBotです。Userから今回入力された質問を補正してください。"
f"補正した質問は、生成AIの入力に利用されます。補正する際、"
f"これまでの会話履歴を考慮して、Userの質問意図を十分に理解して補正してください。"
f"時間をかけてじっくり考えてください。"
f"<今回入力された質問>"
f"{event['raw_text']}"
f"</今回入力された質問>"
f"<これまでの会話履歴>"
f"{formatted_conversation_wo_ref}"
f"</これまでの会話履歴>"
f"解説は不要です。補正した質問のみを出力すること!"
)
# Bedrock Sonnetを使用してプロンプトを処理
prompt = use_bedrock_sonnet(prompt_pre)
else:
# thread_tsがない場合は、raw_textをそのまま使用
prompt = event['raw_text']
# Bedrock RAG Sonnetを使用してメッセージを生成
message = use_bedrock_rag_sonnet(prompt)
# Slackにメッセージを投稿
ts = event['ts']
slack_access_token = get_secret(
"slack_app_servicenow_expert",
"Bot_User_OAuth_Token"
)
post_message_to_slack(cid, message, slack_access_token, ts)
# 正常終了を示すレスポンスを返す
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
# AWS Secrets Managerからシークレットを取得する関数
def get_secret(secret_name, secret_key):
region_name = "us-east-1" # 要修正2:リージョン設定
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
try:
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
except ClientError as e:
raise e
return json.loads(get_secret_value_response['SecretString'])[secret_key]
# Bedrock RAG Sonnetを使用して回答を生成する関数
def use_bedrock_rag_sonnet(prompt):
region = "us-west-2" # 要修正3:リージョン設定
bedrock_client = boto3.client("bedrock-agent-runtime", region_name=region)
model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
model_arn = f'arn:aws:bedrock:{region}::foundation-model/{model_id}'
kb_id = 'XUP335MAD3' # 要修正4:Knowledge base ID
# Bedrock RAG Sonnetを呼び出し
response = bedrock_client.retrieve_and_generate(
input={'text': prompt},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kb_id,
'modelArn': model_arn,
}
}
)
# 応答を整形
answer = response['output']['text']
answer += "\n\n<回答根拠> ==================\n"
for citation in response["citations"]:
for reference in citation["retrievedReferences"]:
answer += "<ファイルURI>\n" + reference["location"]["s3Location"]["uri"] + "\n"
answer += "<該当箇所>\n" + reference["content"]["text"] + "\n"
answer += "---------------\n"
answer += "</回答根拠>\n"
print(answer)
return answer
# Bedrock Sonnetを使用してスレッド履歴からユーザーの意図する質問文を生成する関数
def use_bedrock_sonnet(message):
region = "us-east-1" # 要修正5:リージョン設定
bedrock = boto3.client('bedrock-runtime', region_name=region)
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [{"role": "user", "content": message}]
})
model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept='application/json',
contentType='application/json'
)
response_body = json.loads(response.get('body').read())
answer = response_body["content"][0]["text"]
print(answer)
return answer
# Slackにメッセージを投稿する関数
def post_message_to_slack(cid, message, slack_access_token, ts):
url = "https://slack.com/api/chat.postMessage"
data = {
'channel': cid,
'text': message,
'thread_ts': ts
}
post_data = urllib.parse.urlencode(data)
req = urllib.request.Request(url, data=post_data.encode())
req.add_header('Authorization', 'Bearer ' + slack_access_token)
with urllib.request.urlopen(req, timeout=1) as response:
json.loads(response.read())
# Slackスレッドの履歴を取得する関数
def get_slack_thread_history(cid, thread_ts, slack_user_token):
url = "https://slack.com/api/conversations.replies"
data = {'channel': cid, 'ts': thread_ts}
post_data = urllib.parse.urlencode(data).encode()
req = urllib.request.Request(url, data=post_data)
req.add_header('Authorization', 'Bearer ' + slack_user_token)
with urllib.request.urlopen(req, timeout=5) as response:
response_data = json.loads(response.read().decode('utf-8'))
return response_data
# Slack応答から会話を抽出する関数
def extract_conversation(response):
conversation = []
for message in response['messages']:
timestamp = datetime.fromtimestamp(float(message['ts']))
user = 'Bot' if 'bot_id' in message else f"User ({message['user']})"
text = message['text']
conversation.append({
'timestamp': timestamp,
'user': user,
'text': text
})
return conversation
# 抽出した会話をフォーマットする関数
def format_conversation(conversation):
formatted = "# Extracted Slack Conversation\n\n"
for i, message in enumerate(conversation, 1):
formatted += f"{i}. **[{message['timestamp']}] {message['user']}:** {message['text']}\n\n"
return formatted
# 指定されたタグで囲まれたセクションを削除する関数
def remove_tagged_sections(text, start_tag='<回答根拠>', end_tag='</回答根拠>'):
pattern = re.escape(start_tag) + '.*?' + re.escape(end_tag)
return re.sub(pattern, '', text, flags=re.DOTALL)
Lambdaの環境設定をします。まずはタイムアウトが3秒と短すぎるので、伸ばします。
Configurationから、General configurationのEditをクリックします。

今回は30秒にしておきます。
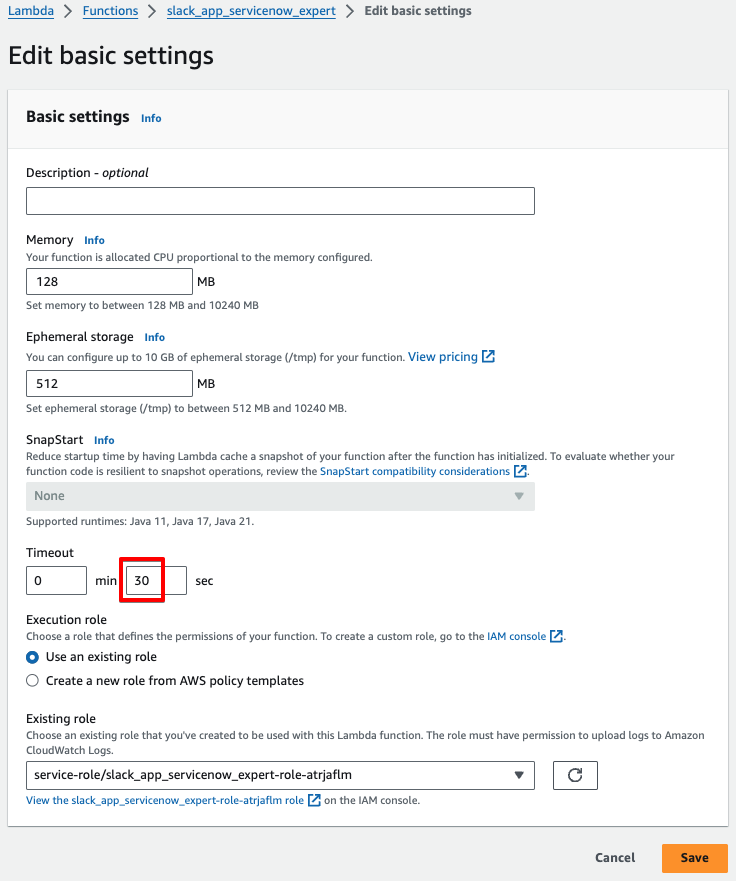
必要なロールを追加します。Configuration -> Permissions から、下の赤枠をクリックします。
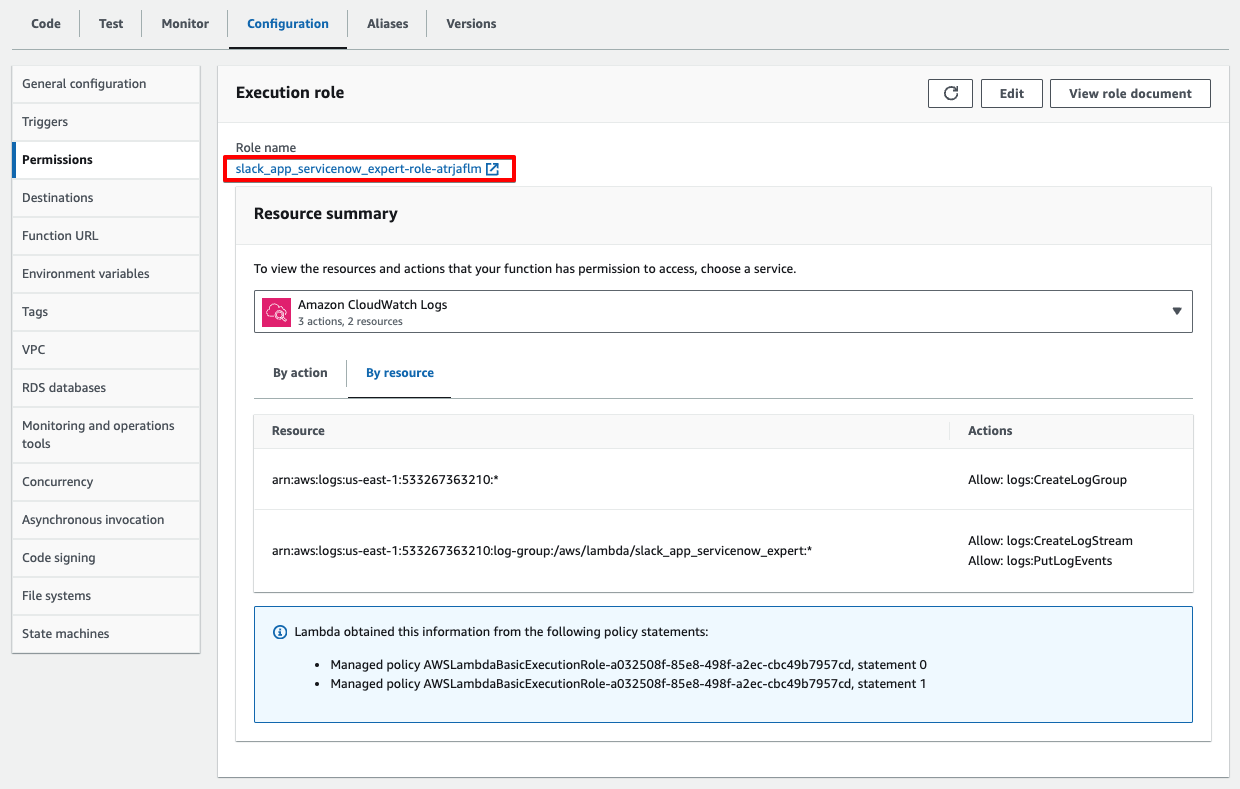
IAMの画面が開きます。
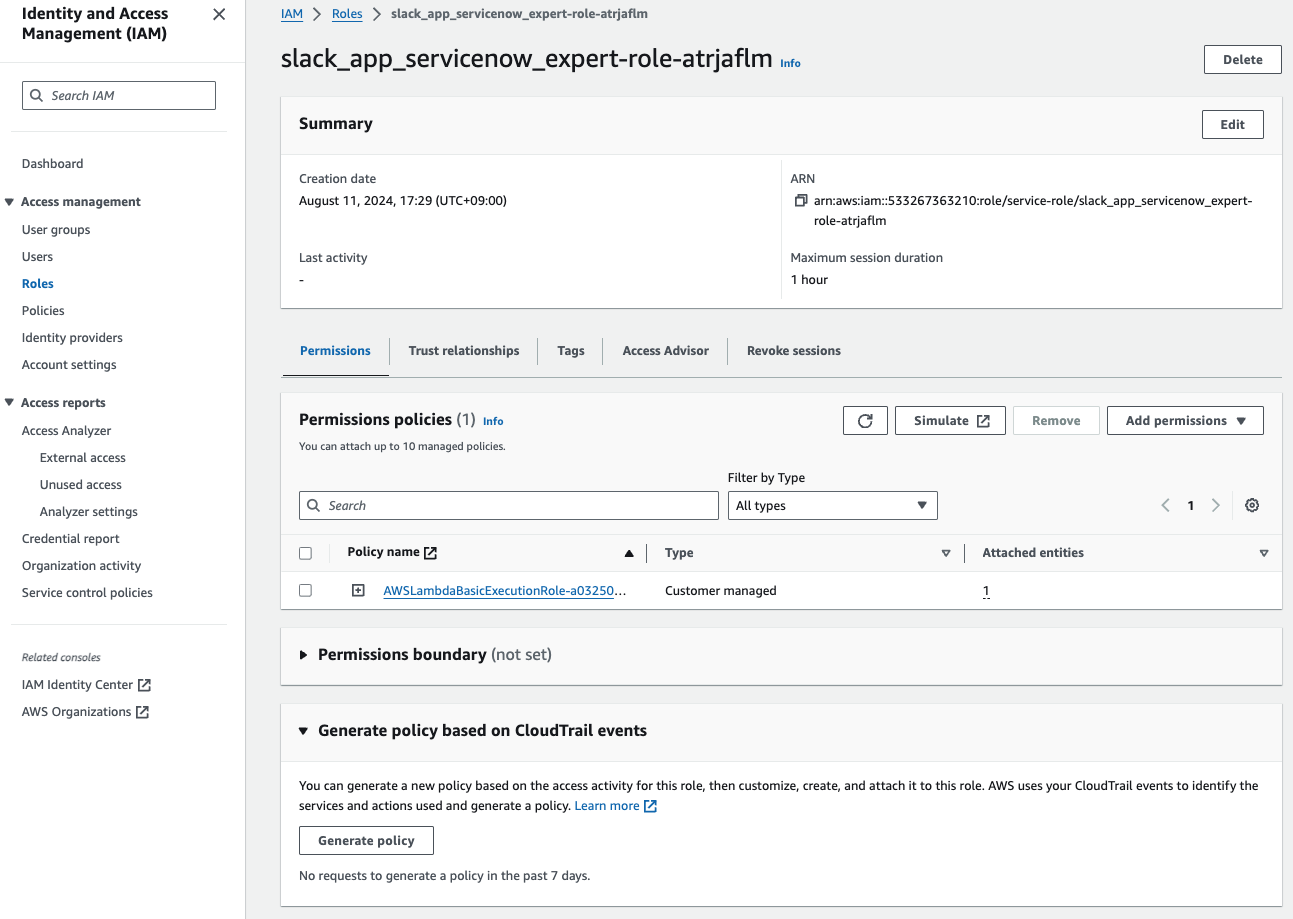
選択して、Attach policiesを選択します。

SecretsManagerReadWriteを付与します。

AmazonBedrockFullAccessを同様に付与します。

これでAWS Lambdaの設定は完了です。
2-4. Zapierの設定
Zapierの設定をしていきます。
Zaps画面(左のイナズママーク)で、Createを押し、New Zapを選択します。

トリガーの設定
Triggerをクリックし、設定していきます。

Slackを選択します。

New Message Posted to Channelを選択します。

Continueをクリックして次へ。
アカウント選択し、Continueをクリックします。
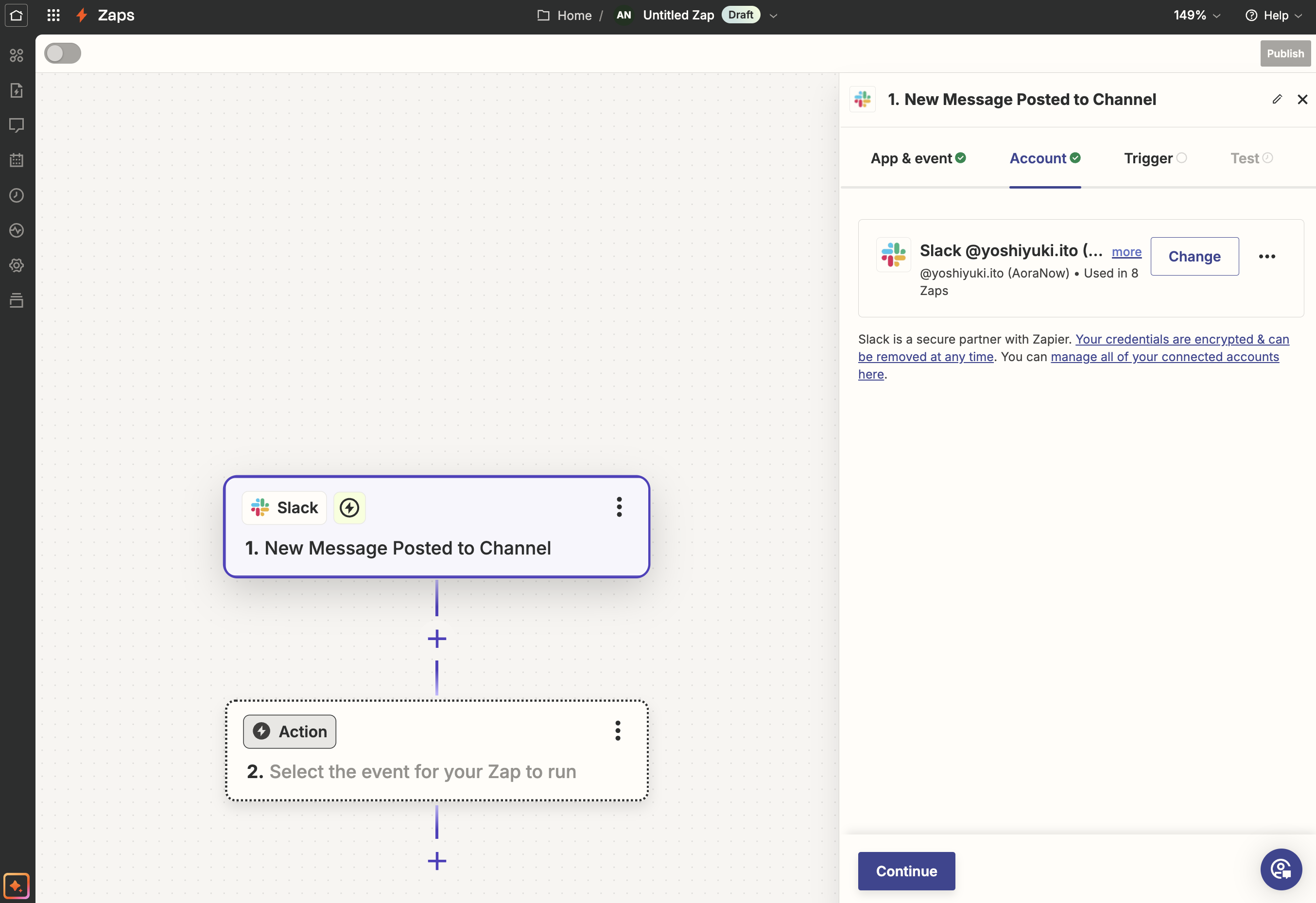
Channelでは、作成したSlackチャネルを選択します。
Trigger for Bot Messages?は、デフォルトのNoのままにします。

Test Triggerをクリックします。

Cotinue with selected recordをクリックします。

次に、アクションを設定していきます。
アクションの設定
AWS Lambdaを選択します。

Invoke Function(Async)を選択します。

AWSアカウントを選択します。

Continueをクリックします。

補足: AWSアカウントの登録
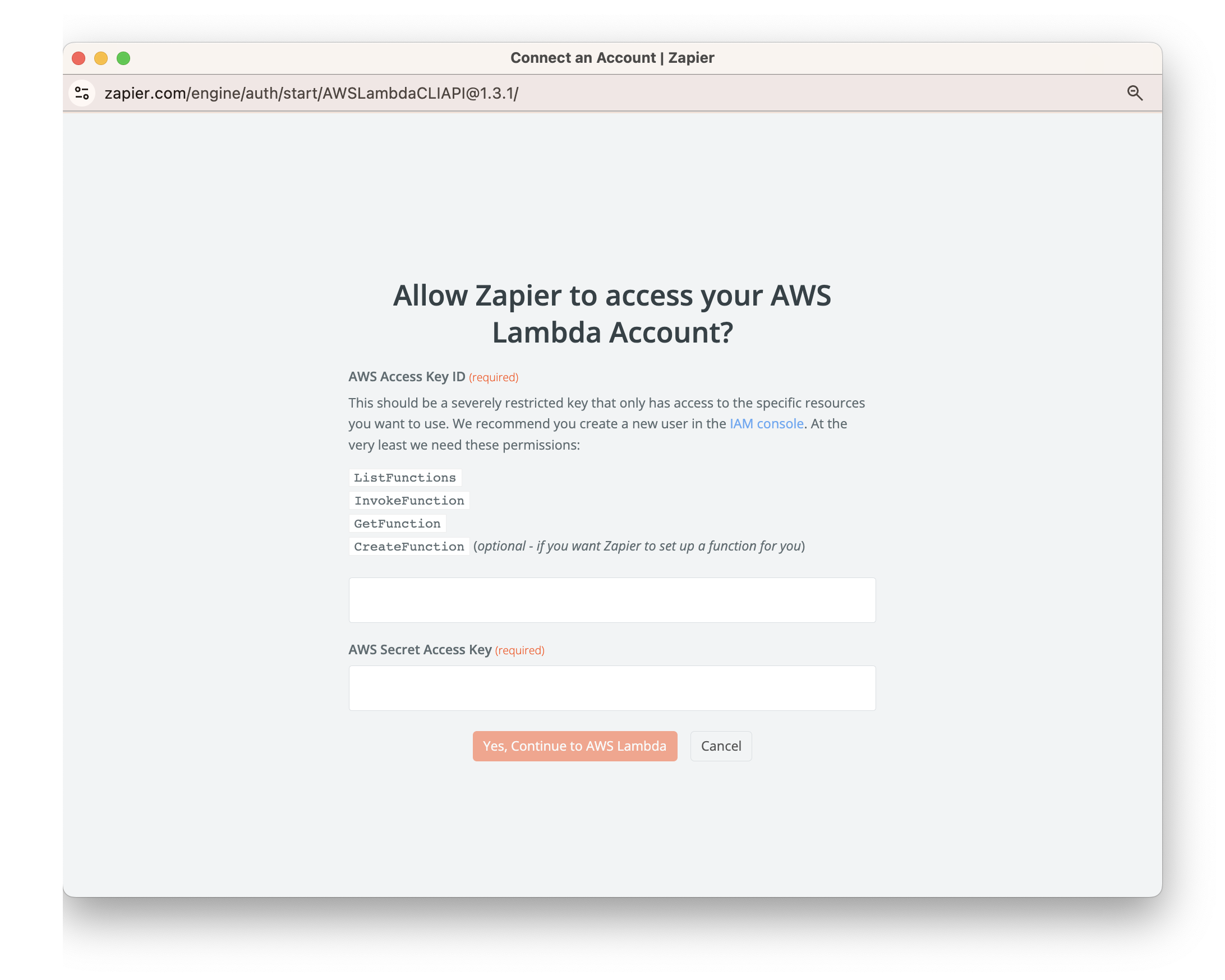
ZapierにAWSアカウントを未登録の場合は、ユーザー選択ウィンドウにて、Connect a new accountを選択し、AWSアカウントの登録を行います。
IAM consoleから、 AWS Access Key IDと、AWS Secret Access Keyを発行し、登録してください。
補足終わります。
アクションの設定(続き)
Actionの設定をします。
Argumentsを3つ設定するのがポイントです。Lambda関数内で利用します。

テストを実行します。

Publishをクリックします。

作成したZapが発行されました。
本記事では設定しませんが、Zapには名前をつけておきましょう。

以上でシステム構築完了です。実際に試してみましょう!
動作確認: Slackに投稿!
構築したRAGシステムを試してみましょう。
<質問>
ServiceNowのNLU modelを削除するために必要なロールは何ですか?またその手順は?
無事応答が返ってきました!!

さらに、履歴を元に追加質問もできます。NLU Workbenchについて、そっけなく聞いてみましょう。
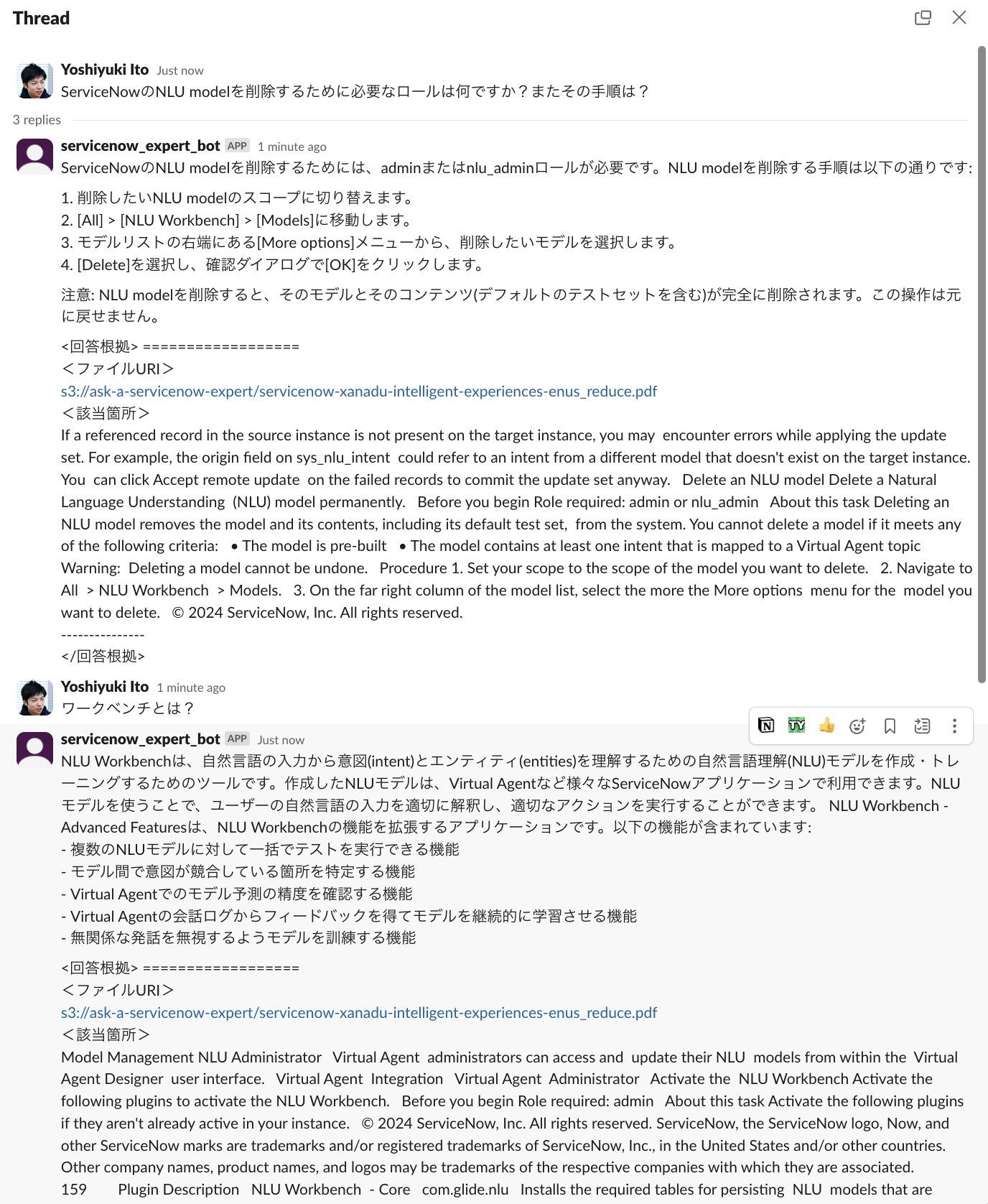
NLU Workbenchのことを聞いていると読み取ってくれました!
以上でRAGシステム構築は完了です。おつかれさまでした!
まとめ
日常業務に使っているSlackに、社内ドキュメントを根拠とした具体的な回答を生成してくれるQ&Aボットを構築する手順を紹介しました。実際に弊社では様々な生成AIアプリケーションを業務に活用していますが、最も利用率が高いのが今回のプロダクトです。いかにアクセスコストと学習コストを下げることが重要か実感しました。
「せっかくRAGアプリケーション作ったのに使われない!」とお悩みの方の参考になれば幸いです。
宣伝:アオラナウ株式会社/人材募集!!
アオラナウ株式会社は、ServiceNow&生成AIでお客様のビジネス課題解決に興味のある方を募集しております。実ビジネスに活用できる生成AIアプリケーション開発に興味ある方もお待ちしています。(応募時にご相談下さい)