はじめに
こんにちは、Datadog Japan で Sales Engineer をしている AoTo です。
この記事は AoTo Advent Calendar 2023 19日目の記事です。
AWS Observability Best Practices というサイトはご存知でしょうか。ここでは、AWS の従業員を中心に Observability のベストプラクティスについてさまざまなガイドを提供しています。
Obeservability って難しそう、Monitoring と何が違うの、と思われている AWS ユーザー向けに、基本的な概念から実装に向けた話までがまとまっているので必見です。
ここからは AWS Observability Best Practices を「本書」として解説し、「Observability とは」「Observability のベストプラクティス」「AWS Observability 成熟モデル」を抜粋して邦訳しまとめました。
2023/12/19 時点での情報を元にまとめています。最新の内容については、AWS Observability Best Practices をご確認ください。
Observability とは
Observability とは日本語では可観測性と訳されたり、慣習的に o~y に11文字含まれることから o11y と表記されます。(ここからは o11y と表記します)
o11y を説明するために定義を確認していきましょう。CNCF tag-observability の Observability Whitepaper の言葉を借りると、o11y とは制御理論で「外部出力の知識からシステムの内部状態をどの程度適切に推測できるかを示す尺度」である、と説明されています。
このように、現在では o11y とはソフトウェアシステムの状態を把握する指標・尺度・能力のように語られていますが、この言葉は1960年の数学的制御理論の論文『On the general theory of control systems』で使われたのが始まりとされています。1
厳密に定義を定めることは難しいですが、o11y が「Observe」と「Ability」を組み合わせた造語であることからも、「何かしらの対象を観測・監視するできる能力」を表していることは想像できると思います。ソフトウェアシステムにおける対象は当然アプリケーションやツール、ソフトウェアやシステムそれ自体で、観測・監視する能力はそれらの状態や構造、挙動や動作を指します。
本書では、o11y とは「観察中のシステムからの信号に基づいて、実用的な洞察を継続的に生成および発見する能力」としています。これにより、「ユーザーは外部出力からシステムの状態を理解し、(修正)アクションを実行できる」とも言い換えています。
このように、ソフトウェアシステムシステムでは「観測・監視する能力」として信号を利用して実践的な洞察を行うことが重要となることがわかります。
現在は様々なベンダーによってログ・メトリクス・トレースの「3本柱」がこれらの信号ないしは o11y そのものであるという解説もされています。しかし、この信号は特定のものに限られず、あらゆるソフトウェアシステムに関連する情報を含むべきです。あくまでログ・メトリクス・トレースをはじめとする信号は o11y の一部であるということは押さえておいた方が良いように思います。
この前提を踏まえて、本書でも o11y が対処する問題として「CPU 時間・メモリ・ディスク容量・API レスポンス時間・エラー・トランザクションレート」などの信号を例に出しています。これらの信号が確認できることによって、運用・開発コスト(インシデント対応速度・開発生産性)を大幅に削減できます。
先ほど示したように、すべてのソフトウェアシステムの情報が必ずしも観察可能な信号ではなく、「3本柱」であってもシステムの一部の情報でしかなく、すべての状態を正しく把握できる訳ではないことは強調する必要があります。あくまでも人間やツールができる限り適切に意思決定を行うために、適切なタイミングで適切なデータを取得することが重要となります。
Observability のベストプラクティス
本書では、o11y の戦略に関する意思決定プロセスに役立つものとして、合計8つの項目から成る5つの主要なベストプラクティスが紹介されています。ここからはそれらの内容を紹介していきます。
重要なものを監視する
o11y において重要なのは、サーバー・ネットワーク・アプリケーション・顧客のような特定の対象ではなく、目的から逆算して想定されるデータの測定・記録方法です。ここでは、e コマースワークロードを例にして説明されています。
ここでの項目は簡素な内容です。
目的を知り、観測する
何が重要かが定まれば、これを自動的に追跡して測定することが必要となります。測定ができていてもデータが活用するために適切な場所にあるとは限りません。そのため、すべての必要なデータは時系列として保持し、他のデータと紐づけて確認することが重要となります。
コンテキストの伝搬とツールの選択
ここでは、モダンな o11y のアプローチはアプリケーショントレースによる「connecting the dots」に依存していることから説明が始まります。つまり、現状ソフトウェアシステムの状態を理解する上では、アプリケーショントレース信号が欠かせないということです。
ここでは、3点の重要な項目が提示されています。
共通のツールの使用
運用上の手間や学習コストの軽減により、新しい環境への o11y の迅速な適用につながります。そのため、広範なワークロードの層を担っているツールか、標準化されたオープンソースのツールが望ましい選択肢となります。
既存のツール・プロセスとの統合
既に存在している IdP(Active Directory, SAML IdP)、ITSM ツール(JIRA, ServiceNow)、ワークロード管理・エスカレーションツール(PagerDuty, OpsGenie)、IaC ツール(Ansible, SaltStack, Cfn, Trraform, CDK)を活用して o11y ツールを利用することが重要です。
自動化・機械学習の利用
AIOps と呼ばれる概念が示すように、人間よりもコンピュータが得意な領域については自動化・機械学習を積極的に利用することが効果的です。すべての情報を目にしようとするのではなく、異常検出・自動化・機械学習によってデータの変化を捉え通知を行うことで目的に集中できます。
すべての層からのテレメトリ収集
ソフトウェアシステムの中心となるアプリケーションも独立して存在はしておらず、ネットワーク・クラウド・ISP・SaaS・別のアプリケーションとのやりとりがあることを念頭におく必要があります。つまり、これらすべての繋がりの結果としてソフトウェアシステムへの影響が発生するため、ワークロード全体を包括して把握することが重要となります。
ここでは、2点の項目が示されています。
コンポーネント間の統合を重視
o11y のアプローチが依存しているように、コンポーネント間の繋がりを可視化するためにはアプリケーショントレースを利用して、単一の識別子によって情報を繋げることが重要となります。2
エンドユーザーの体験を忘れない
しばしば、ワークロード全体はアプリケーションシステムのみを指すように考えてしまいがちですが、エンドユーザーがどのような体験をするかを含めて考える必要があります。ユーザー体験の品質を定量化し理解することが、例えば CPU 使用率を理解するような基本的な監視以上に重要となってきます。3
細かいことは気にしない
4点目は面白いベストプラクティス(アドバイス)が示されています。
あらゆることを考慮するとアプリケーションのコンポーネントから収集する信号が膨大になる懸念があり、逆効果となりえます。細かいことは気にせず、重要なことから監視をすることから始めて、重要なコンポーネントとその繋がりをマッピングし、本当に必要な詳細な情報を得るようにしましょう。
o11y from Day One
o11y はもはやセキュリティと同様に後回しにすべきではない重要な概念です。アプリケーションシステムが稼働する早期の段階で o11y を考慮することで、初めから o11y を前提としてそれを利用してシステムを作り上げ、開発効率自体も向上することができます。
AWS Observability 成熟モデル
本書では、モニタリングと o11y の違いは、モニタリングはシステムが動作しているかどうかを伝えるのに対し、オブザーバビリティはシステムが動作していない理由を伝えることであるというように区別しています。また、モニタリングは事後対応的な手段で、o11y の目標は KPI をプロアクティブな方法で改善できるようにすることであるとも表現されています。
成熟モデルの概要
o11y 成熟モデルはワークロードの o11y と管理プロセスの最適化を目指す組織にとって不可欠なフレームワークで、o11y を改善・評価・達成するためにの包括的なロードマップを提供しています。
成熟モデルの段階
ワークロードが拡大するにつれて、o11y 成熟モデルの各段階を達成できるようにすることが重要です。成熟モデルは大きく4段階に分かれています。
- 基本的なモニタリング - テレメトリ データの収集
- 中級モニタリング - テレメトリ分析と洞察
- 高度な o11y - 相関と異常の検出
- プロアクティブな o11y - 自動的かつプロアクティブな根本原因の特定
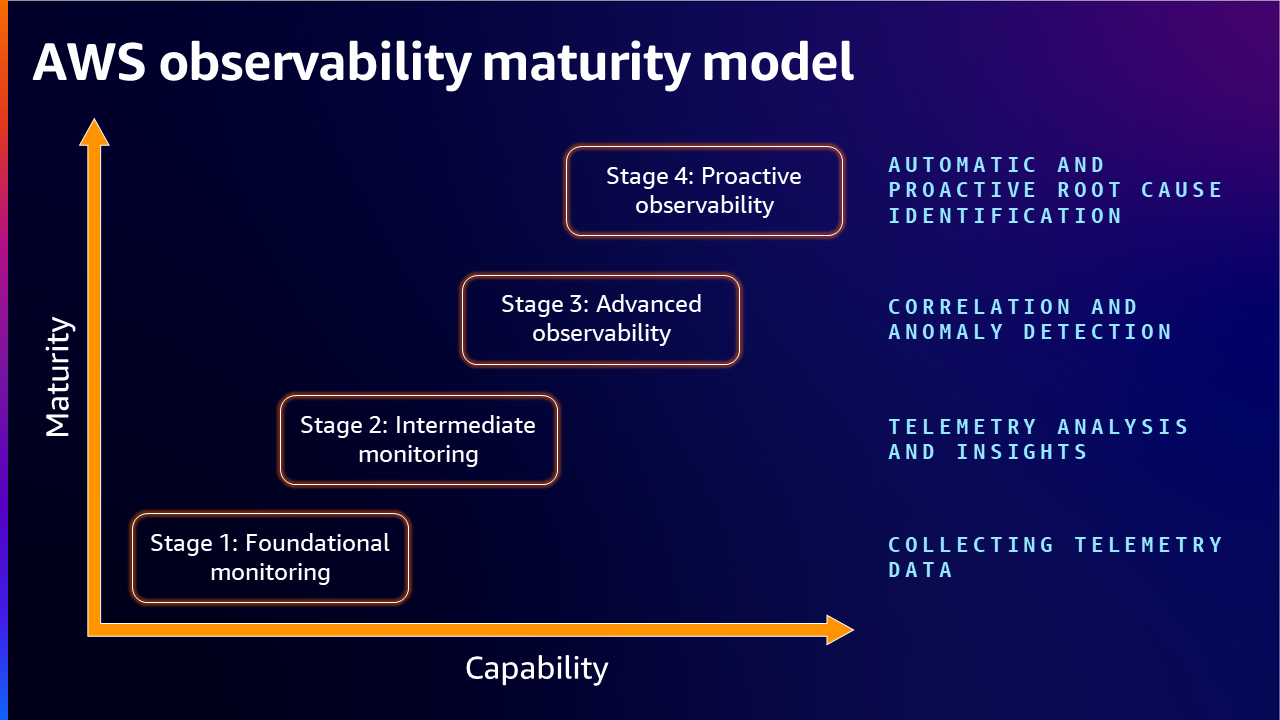
基本的なモニタリング - テレメトリ データの収集
さまざまなチーム内で必要最小限な複数の監視ツールを使用するサイロな段階です。チーム間では互いのデータを使用できないため、環境全体のデバッグや環境の最適化には有効な手段ではありません。
成熟度レベルの向上に向けて、メトリクス・ログ・トレースの収集を通じてワークロードを計測し、適切な監視および可観測性ツールを使用して洞察を得ることで、環境全体を制御および最適化できるようになります。
中級モニタリング - テレメトリ分析と洞察
オンプレミスやクラウドなどのさまざまな環境から共通のシグナルを収集し、環境全体が明確になる段階です。ワークロードからメトリクス・ログ・トレースを収集するモデルは現在では o11y の基本構造として認識されています。事後対応や推測でなく、必要なアクションをワークフローで呼び出し、取得した情報と知見に基づいて分析とトラブルシューティングを行えます。
成熟度レベルの向上のために、アーキテクチャの定期的に見直しによりダウンタイムを軽減してアラートを減少させたり、実行可能な KPI を定義してアラートの優先順位づけを実行し、問題解決を迅速化することが必要になります。
高度な o11y - 相関と異常の検出
トラブルシューティングの効率化により、問題の根本解決を明確に行うことができる段階です。これにより、メトリクス・トレース・ログの信号の関連づけを行うことで、状況の全体像を把握してシステムへの是正措置を迅速化することができます。
成熟度レベルの次の段階に進むためには、可能な限りこのプロセスを自動化して複雑な知見や技術を必要とせず、未知の事柄に対しても一定の洞察・結論を得られるようになる必要があります。この自動化を支えるソリューションとして、AIOps のような可能な限り属人的な要素を排除した上で、信号の関連付け・根本原因の特定に繋げることが必要となります。
プロアクティブな o11y - 自動的かつプロアクティブな根本原因の特定
成熟モデルの最終段階では、o11y1 で観測しているデータを利用して、問題が起きる前にリアルタイムで状況を分析し、起こりうる問題に備えることができる段階です。ここでは、動的なダッシュボードを自動的に作成できるようになり、現在抱えている問題に関連する情報のみを参照して問題解決に繋げることが可能です。
近年では、生成 AI や機械学習の恩恵をすぐに受けられるため、将来的にはこのようなプロアクティブな監視を行うことが現在よりも一般的となる可能性があります。
AWS Well-Architected Framework と AWS Cloud Adoption Framework
AWS Well-Architected Framework と AWS Cloud Adoption Framework を活用することで、o11y を最大限活用しクラウド環境を効果的に監視・トラブルシュートできます。これらのフレームワークはワークロードの設計・デプロイ・運用のために構造化されたアプローチを提供し、ベストプラクティスが確実に遵守されるようにします。さらに、組織に標準化された実践と規範的なガイダンスも提供し、組織全体でのコラボレーション・知識の共有・一貫したソリューションの実装を容易にします。
o11y を実現するために AWS Well-Architedted Framework と AWS Cloud Adoptioon Framework を実装するには、いくつかの手順があります。
- o11y 成熟度モデルに基づいた、現状の評価と改善領域の特定
- 結果に基づいた、監視要件定義やツールの実装などの取り組みへの優先順位付けと計画
- o11y ソリューションの継続的な監視と最適化
評価
o11y 成熟度モデルの評価は、o11y の現状を評価して改善すべき領域を特定するために行います。o11y 成熟度モデルにおける各段階の評価基準として、複数チームにわたる既存の監視と管理の実践を評価し、改善すべきギャップと領域を特定することで、次の段階への全体的な準備状況を判断します。
o11y 成熟度モデルの評価は、最新のシステムの複雑で動的な性質にビジネスが対応できるようにする上で重要な役割を果たします。これは、システム障害やパフォーマンスの問題につながる可能性のある盲点や弱点を特定するのに役立ちます
さらに、定期的な評価により、ビジネスの機敏性と適応性が維持されます。
o11y 戦略の構築
o11y の段階を特定したら、現在のプロセスとツールを最適化するための戦略を練り、成熟度の向上に向けて取り組みを開始する必要があります。o11y 戦略を構築するには、3つの主要な側面を考慮する必要があります。
- 何を収集するか
- 監視する必要があるシステム・ワークロードは何か
- 問題発生時の対応方法と修正する仕組み
o11y 戦略と全体的なビジネス目標と整合するようにし、o11y 目標を定義します。また、組織が戦略を通じて達成すべきことを明確に示し、o11y 計画を構築・実行するためのロードマップを作成します。
ロードマップが作成できたら、システムのパフォーマンスを示す KPI を特定する必要があります。(レイテンシー・エラー率・リソース利用率・トランザクション量など)この指標の選択はビジネスの性質・ニーズに大きく依存します。
KPI が特定されたら、データ収集に必要なツール・技術を決めます。ツール選択は、目標との整合性・既存システムとの統合・コストの最適化・拡張性・顧客のニーズを考慮して選択する必要があります。
最後に、o11y を重視する文化を奨励することが重要です。メンバーのトレーニング・積極的な監視・継続的な学習と改善の文化を育成する必要があります。この戦略によって、収集・行動・改善の継続的なプロセスの好循環を生み出します。
結論
o11y 成熟度モデルは現在の状態を評価して、システムの動作を理解・分析し、対応する能力を向上させる方法を模索するためのロードマップとして使用できます。これにより、o11y 成熟度が段階的に向上し、より多くの情報に基づいた迅速な意思決定を行えるようになります。
おわりに
AWS はこのような o11y のベストプラクティスや成熟度モデルを提示していて、これにより o11y の導入を考えている場合も既にある程度実装を進めている場合も、システムの現在の o11y の達成度を把握することができます。
特に、o11y 成熟度の最終段階「プロアクティブな o11y」に何の調整もせずに到達することはほとんどなく、現状の評価や継続的な改善を通じて達成することができるものです。
AWS はこれらの o11y を実現するための様々なツールの選択肢を、様々な AWS のソリューション別に提供しています。実際の実装や選定にも興味がある場合は、是非AWS Observability Best Practices を参考にしてみてはいかがでしょうか🐶
-
詳しい解説は O’Reilly Japan から邦訳も出ている、『オブザーバビリティ・エンジニアリング』をご参照ください。 ↩
-
現在ではこの単一の識別子の標準化が進み、W3C Trace Contextが分散トレーシングで活用されるようになっています。 ↩
-
このユーザー体験を定量化するツールとして Real User Monitoring(RUM) があります。 ↩