概要
scikit-learnのサイトでは、いくつかToyデータセットが用意されています。
そのうちの一つの「ボストン住宅価格データセット」を使って重回帰分析を行い、残差プロットをしてみたところ、気になる外れ値が見つかったのでその原因を考察してみました。
ボストン住宅価格データセットを重回帰分析する
必要なライブラリのインポート
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_boston
%matplotlib inline
データセットの読み込み
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data', header=None, sep='\s+')
df.columns = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','MEDV']
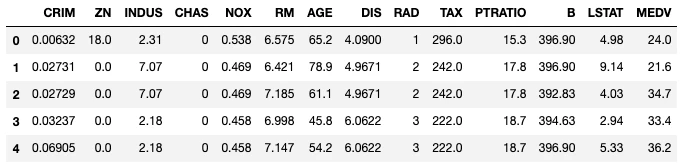
データフレーム確認
pd.DataFramae(df.head())
出力結果
特徴量と正解の指定
データフレームの出力結果から、0~13列のデータを特徴量(説明変数)とし、14行目のMEDV(住宅価格)を正解(目的変数)とします。
# 住宅価格以外のデータを特徴量Xに設定
X = df.iloc[:, 0:13].values
# 住宅価格を正解yに設定
y = df['MEDV'].values
特徴量と正解を、訓練データとテストデータに8:2で分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=0)
標準化
例えば、部屋の数の特徴量は一桁が一般的ですが、部屋の広さは二桁以上(㎡)が一般的です。この場合、数値の大きさとばらつきに大きな差があるため、同じ基準では評価できません。
そのため、標準化を行い、スケールを揃える必要があります。
# 特徴量の標準化
sc = StandardScaler()
# 訓練データで標準化モデルを作成し変換
X_train_std = sc.fit_transform(X_train)
# 作成した標準化モデルでテストデータを変換
X_test_std = sc.transform(X_test)
# 標準化された訓練データ
X_train_std[0]
モデルの作成と訓練
モデルには、scikit-learnの線形回帰モデルLinearRegression()を使用します。
# モデルの作成
model = LinearRegression()
# モデルの訓練
model.fit(X_train_std,y_train)
傾きと切片の確認
print('傾き: ' , model.coef_)
print('切片: ' , model.intercept_)
出力結果

MSEの計算
MSEとはモデルの評価指標の一つで、この値が低いほどモデルの性能が良いと言えます。
算出方法は、予測値と正解の平均二乗和誤差です。
MSEの計算は、scikit-learnが提供しているmean_squared_error関数を使用すれば、実装できますが、ここではあえて、手打ちで計算します。
# 訓練データ、テストデータの住宅価格を予測
y_train_pred = model.predict(X_train_std)
y_test_pred = model.predict(X_test_std)
# MSEの計算
MSE_train = np.mean((y_train_pred - y_train) ** 2)
MSE_test = np.mean((y_test_pred - y_test) ** 2)
print('MSE train: ', MSE_train)
print('MSE test:', MSE_test)
出力結果
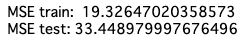
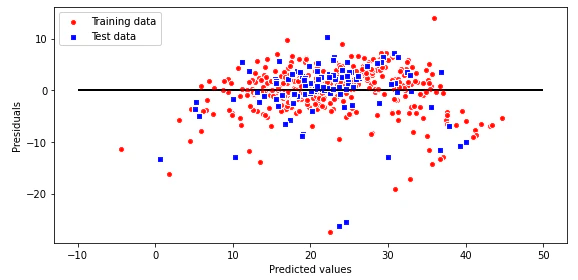
残差プロット
残差プロットは、誤差のばらつきを視覚化したもので、ばらつきが小さいほど性能が良いモデルと言えます。
プロットを確認すると、大体-10から10くらいの範囲に誤差のばらつきが見られます。
plt.figure(figsize = (8,4)) #プロットのサイズ指定
plt.scatter(y_train_pred, y_train_pred - y_train,
c = 'red', marker = 'o', edgecolors='white',
label = 'Training data')
plt.scatter(y_test_pred, y_test_pred - y_test,
c = 'blue', marker='s', edgecolors='white',
label = 'Test data')
plt.xlabel('Predicted values')
plt.ylabel('Presiduals')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=-10,xmax=50,color='black', lw=2)
plt.tight_layout()
plt.show()
出力結果
残差プロットから読み取る外れ値
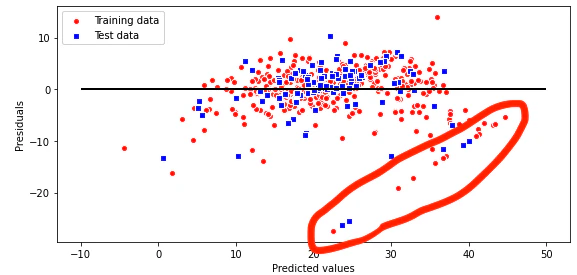
上の図の赤い丸で囲った部分のプロットに着目します。
なんだかよくわからないですが、直線にプロットされているので、何かしらの相関関係がありそうです。
そこで、価格と部屋数の散布行列図をみてみます。
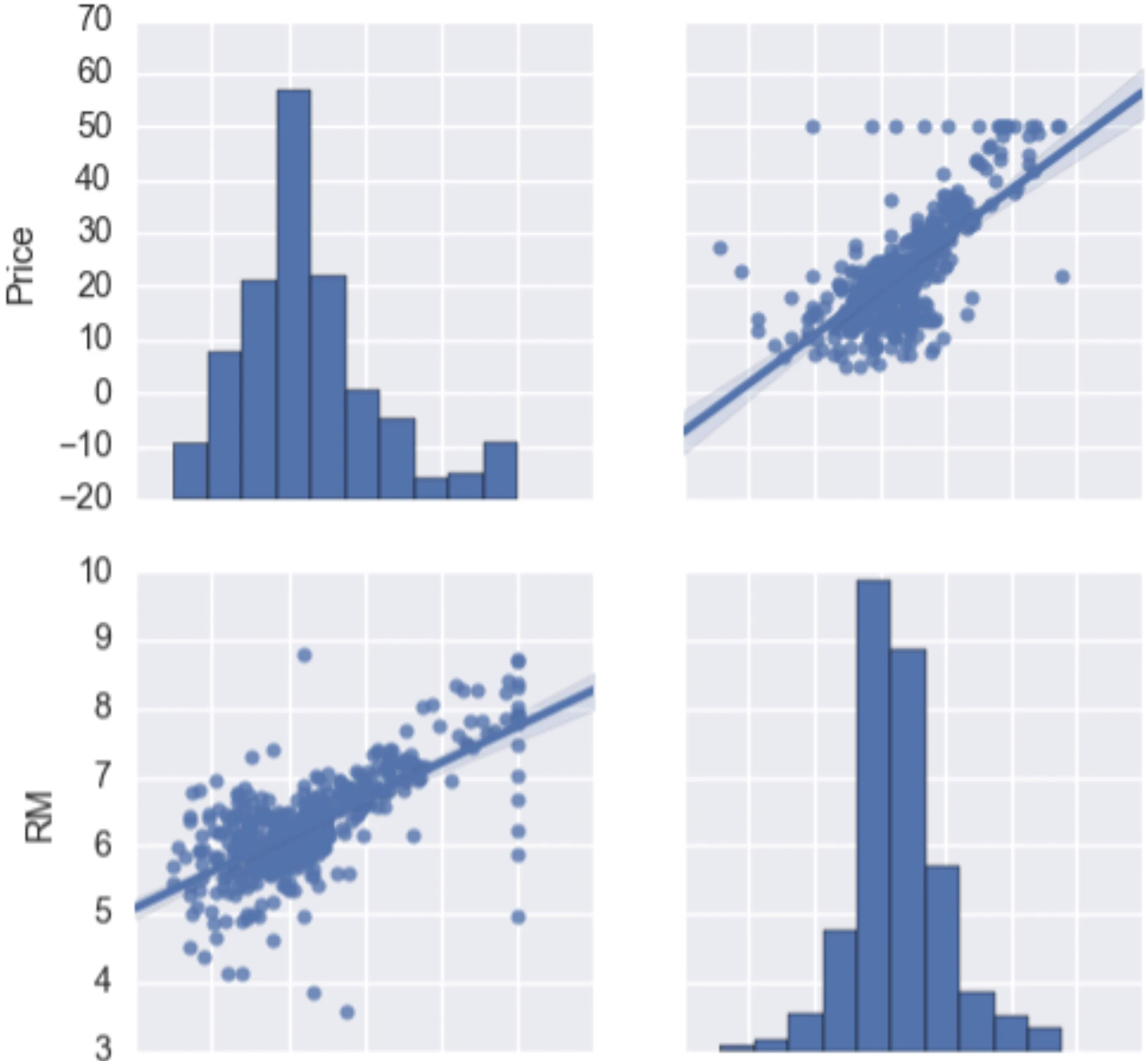
上図の右上の散布図に着目してみましょう。
住宅価格の上限が50で固定されてそうです。
何の意図があって、このようなデータになっているのかわかりませんが、おそらく、住宅価格の上限が設定されていることが原因だと思われます。
まとめ
今回は、ボストンの住宅価格データセットを用いて、住宅価格の回帰を行い、その過程できになる外れ値の調査をしました。
普段、何気なしにプロット図を出力していた僕ですが、なぜそのような図になるのかを考察してみるといろいろなことが見えてきました。
また、本来機械学習を行う際は、上記のような外れ値は除外して行うのが一般的です。