1 初めに
皆様お久しぶりです(はじめましての方は初めまして)。今回は私が普段行う「データ整理」に関連する記事です。皆様は学校の授業や会社で「CSVファイルを整理してグラフ化して」と頼まれたことありませんか?そんな時に0からグラフを作る作業を何度も繰り返すのは時間の無駄です。
今回はそんなCSVファイルから所望のデータを抽出、グラフ化することをpythonで自動化していきたいと思います。また、初心者の方にもわかりやすいように、初学者知識と少しの数学知識(算数知識の方が適当かもしれません)でプログラムを書いていきます。
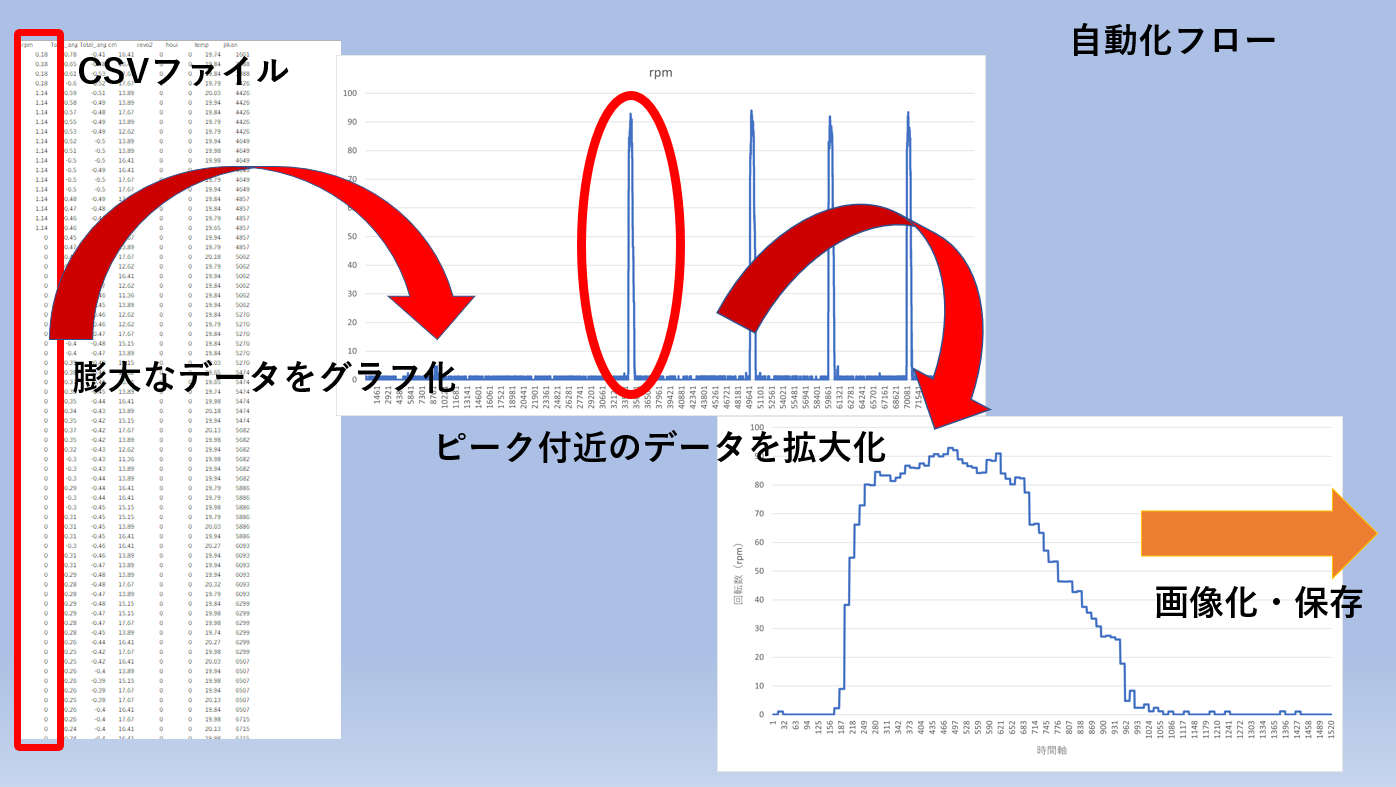
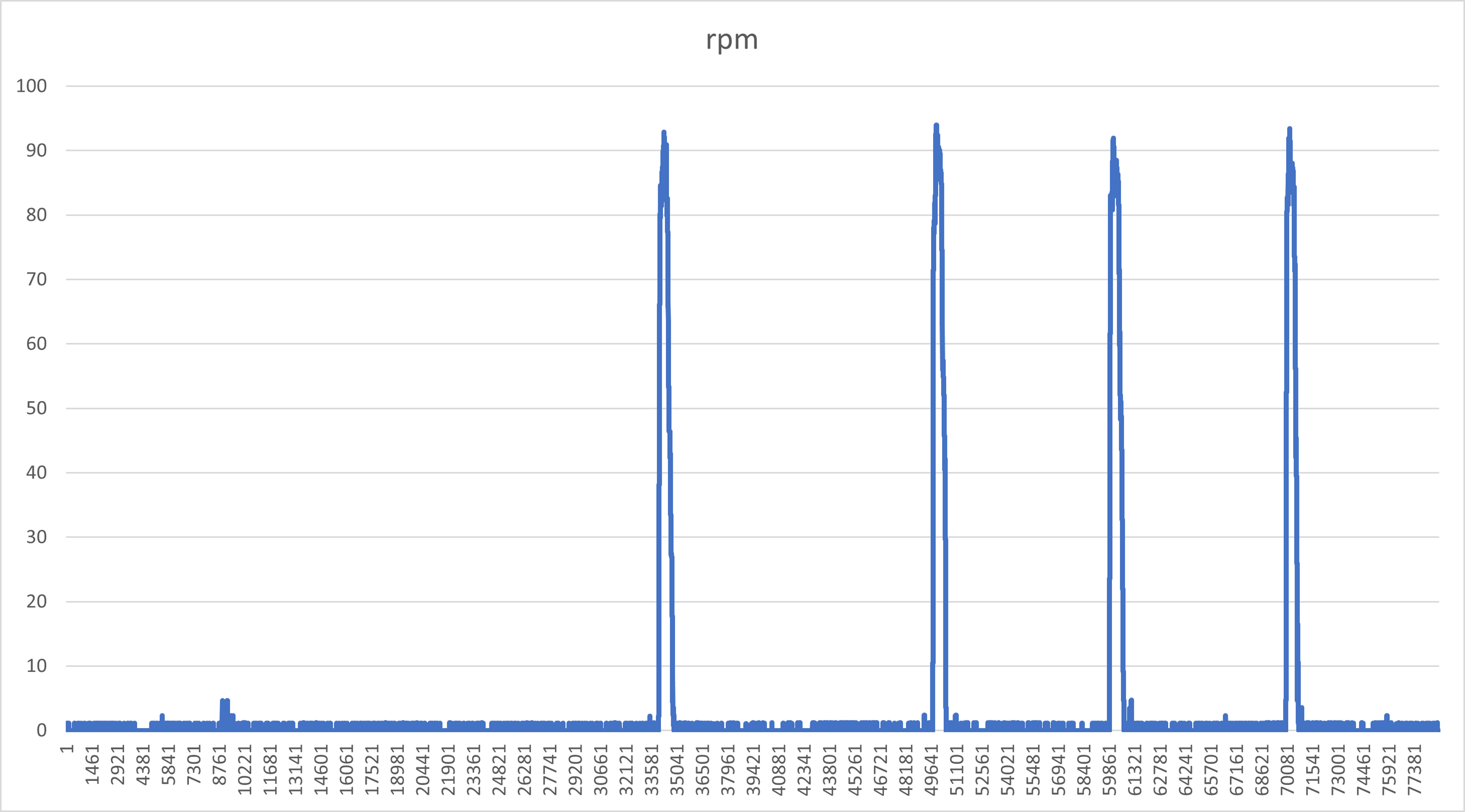
特に今回グラフにするデータとは下図のように量が莫大で、そのデータの中からある領域を抽出、グラフにするというものです。このプログラムを理解し、コツをつかんでしまえば、読者様の環境に合わせてグラフ化するプログラムを自由自在に書けると思います。
グラフを描画するにあたりpythonのmatplotlibライブラリを使用します。また、コードはオブジェクト指向スタイルで作成しています。スタイルやpythonライブラリの構成などの詳しい内容は、本記事の最後にある「6 理論的なお話」で説明します。理論的な話は後に回して、まずは書いてみることから始めましょう。
また、「自動化」という点から今回の動作はRaspberry Piで行います。WindowsやMacでもpython環境とそのライブラリ環境が整っていれば動作できます。また、ラズパイ独自の操作は記載していません。本記事では、ラズパイで動かすことで業務の自動化を模擬して、Linuxコマンドで実行することでITエンジニアっぽくやっていきます笑。
1.1 今回したいこと
さて、冗談はさておき本記事では大きく2つのステップで説明を進めていきます。
1. ピークを探す
2. ピーク付近を切り取ってグラフ化する
1.2 学びポイント
また、本記事で学習できるポイントをまとめました。太文字は重要項目です。
- CSVファイルを読み込む
- データフレームの扱い方(簡易・限定的)
- ピークを捉える
- スライス
-
グラフ作成
- 軸ラベル
- 数値表示設定
- matplotibライブラリのオブジェクト指向スタイル
2 準備
コードの説明を始める前に今回の例を動作させる環境について簡単に紹介します。2章の説明はWindowsやMac環境の方はpythonのバージョン以外は読み飛ばしてもらって構いません。
2.1 動作環境
例に用いる環境は以下の通りです:
プラットフォーム:Raspberry Pi 4[4GB]
Distributor ID: Raspbian
Description: Raspbian GNU/Linux 10 (buster)
Release: 10
Codename: buster
pythonバージョン:Python 3.7.3
編集エディタ:VsCode[Windows]
補足:Pythonを実際に動作させるのはラズパイなのですが、ラズパイに直接マウスやキーボードを付けて操作しません。WindowsからSSH経由でVisual Studio Codeを使ってラズパイに書き込み、操作します。以下ではWindowsのVsCodeのスクショを使用して説明することがありますのでご承知おきください。
2.2 ラズパイ環境参考情報
先ほど説明したWindowsからラズパイを操作する方法や、ラズパイのネットワーク環境に関する説明の参考元URLを下に示しておきます。
3 ピークを探す
では本題のコードを説明していきます。
第1のステップとしてデータからピークを探します。
前述したように今回はpython初心者向けの記事となっていますので、プログラムも少し丁寧に説明していきます。
3.1 CSVファイルを読み込んでデータ化する
初めにcsvファイルを読み込みます。
今回はpythonの一般的なライブラリの一つであるpandasライブラリを用いてcsvの中身をデータフレーム化していきます。まず下記のようにRDdata変数にpandasライブラリのread_csv関数を用いて、csvファイルの中身をデータフレーム化して代入します。引数については、1つ目がcsvファイルのパスで、2つ目はメモリを効率的に使うためのオプションです。これは、扱うデータの量が大きい場合(csvファイルの中身が大きい時)にメモリの制限を超え、プログラムが止まるのを防ぐものです。
RDdata = pd.read_csv("include csv path", low_memory=False)
3.2 上から順に読み込む
では、次にデータフレーム化したcsv、RDdata変数の中身を上から順に読む動作をします。
下記のfor文は私の以前作成した「LINE Messaging API+Ngrok+Python で実験的にLINEボットを開発してみよう Part3会話盛りだくさん編 2.3.1節」に詳しい説明がありますので、詳しくはそちらをご覧ください。
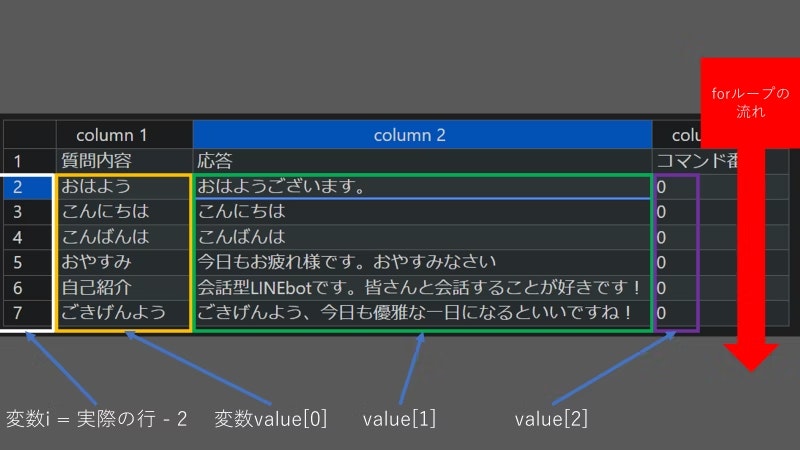
見るのが面倒な人のために簡単に説明しておくと、まずfor文中にある.iterrows()メソッドはforループを繰り返すたびに対象のデータフレームの情報を1行ずつ読み込んでいきます。forループの動きと変数の扱い方はコード下の図を参照してください。尚、画像は上の記事より引用したもので、データの中身は今回と関係ありません。変数value、iの役割と動き方、forの流れがどのようになるかだけを確認してください。
for i,value in RDdata.iterrows():# RDdata変数の中身を1行ずつ読む
#処理内容
3.3 閾値超えデータを検出する
次にデータを読む動作ができましたので動作中に閾値判定処理を入れます。
下記コードでは、csvファイル(元データ)のforループ回数行目の1列目のデータを見て、その値が65を超えたときにDetectと出力されるようにしています。例えば、1列目の3行目に65を超えるデータが存在すれば、forループが3回目の時にDetectという出力がされます。
for i,value in RDdata.iterrows():
if value[0] > 65:#csvファイルの一列目を観察して検知する
print("Detect")
3.4 ピークを正確に捉える方法
次にピークを捕捉する処理を行います。この節が本記事で一番重要となりますので、気を引き締めて読んで書いてください。
実際にピークを捉えようとするときは3.3節のように閾値条件の可否で行います。ですが、問題が2点あります。
- ピークを超えた1点だけを取得
- 1つのピークで複数回閾値をまたぐ場合
3.4.1 ピークを超えた1点だけを取得
今回欲しいのはピークを検出した瞬間の一点の場所だけです1。その為、閾値を超えた瞬間のデータを捕捉する必要があります。
では、どのように行えばよいでしょうか?先の3.3節では閾値を超えると、そのすべてのデータで検出してしまいます。では下図のように考えるのはどうでしょうか。
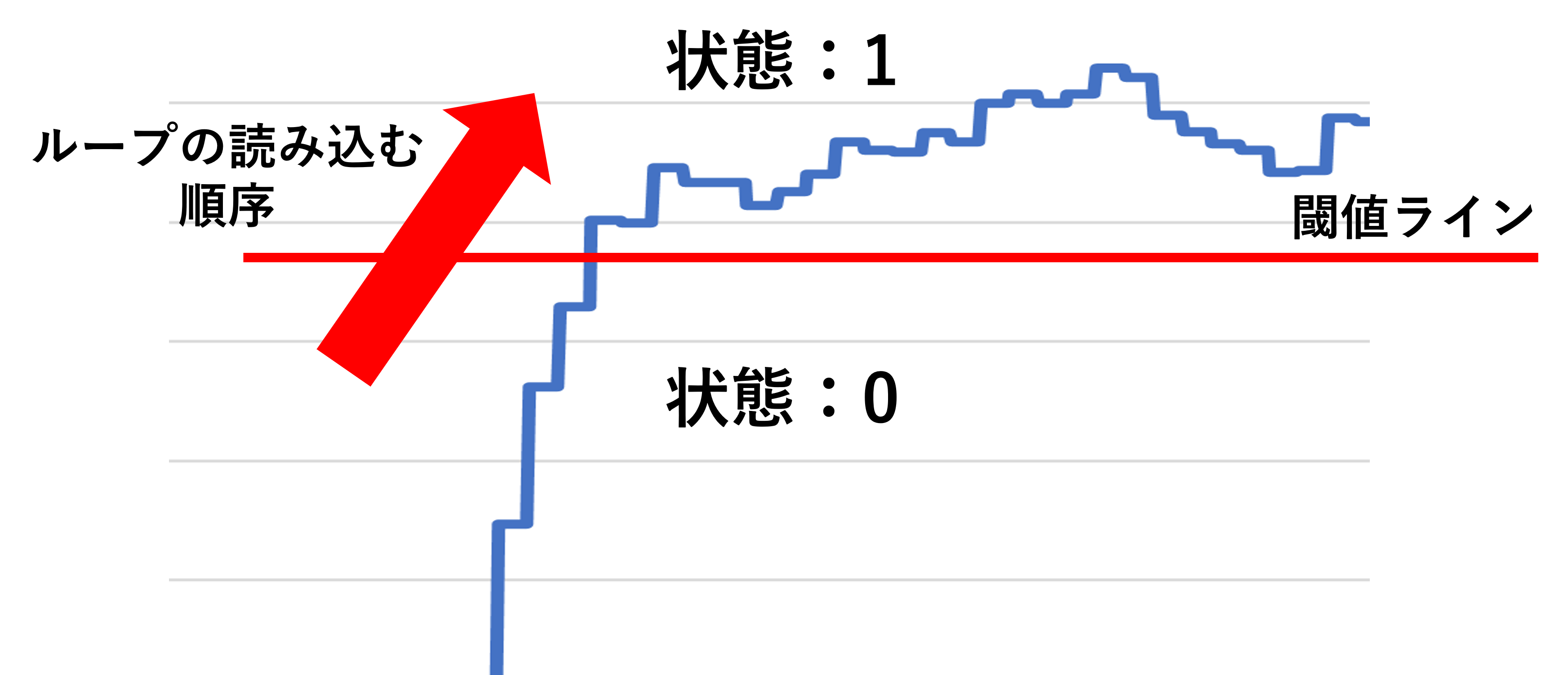
今、forループ(読み込む動作)が左から右へ進むとするとします。また、赤い閾値を超えない領域は状態0とし、反対に超えた領域を状態1とします。
すると、閾値を超えた瞬間のデータとは前ループで状態0かつ現ループで状態1であることが分かります。つまり、閾値を超えた瞬間のデータとは現時点でのループと前ループの状態が異なり、同時に前ループで状態0である状況の事を指します。この状況をifの条件文で作成すると、下記のようになります。現ループの状態を表す変数をdetect、前ループはpre_detectとしています。
if detect != pre_detect and pre_detect == 0:
3.4.2 1つのピークで閾値を複数回またぐ場合
3.4.1節でピークを捉えることができました。しかし、下図のようにピークに幅がありその間で値が閾値を上下する場合についてはどうでしょうか?
3.4.1節の条件文では1つのピークに複数ピークがあると誤認してしまうケースが出ます。それを回避することが必要です。
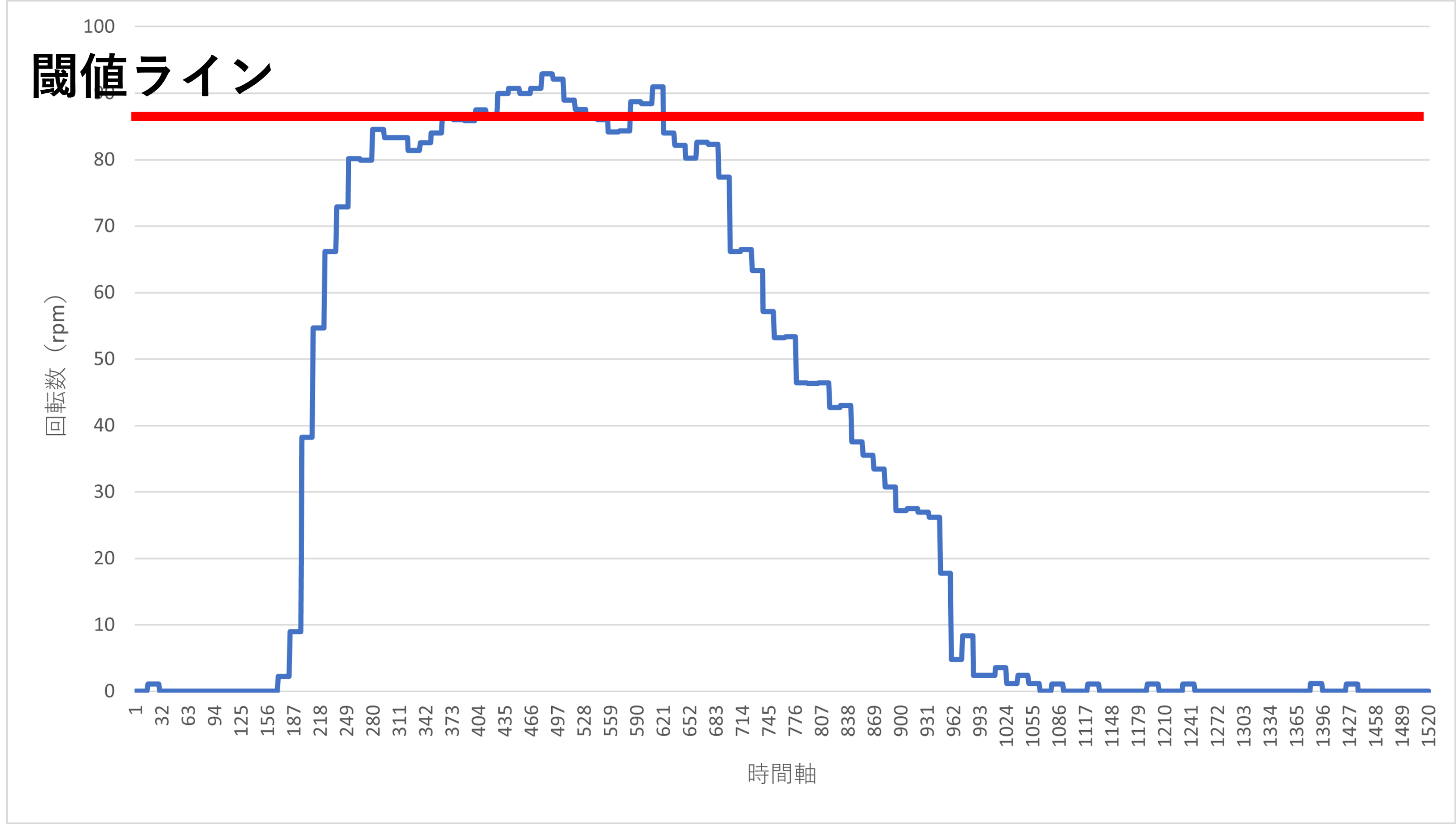
一番簡単な回避方法としては閾値を下げることです。下から上の動作が一回しか訪れない領域に閾値を設定してあげれば問題は回避できます。しかし、閾値が小さくなるため、捉えたくない別のピークや平常値を捉える可能性があります。加えて閾値も環境に合わせて常に変える必要があり、ピーク捕捉の精度が落ちてしまいます。
今回は別の回避方法を提示しています。下図のように、閾値を超えた際にそのあと一定の間には閾値の判別を行わないとするものです。そうすれば、1つのピークで複数回閾値をまたぐことがあっても判別を行わない間隔があるため、判別を正常に行えます。また、閾値も常に変える必要がなくなります(閾値条件の柔軟性が向上)。
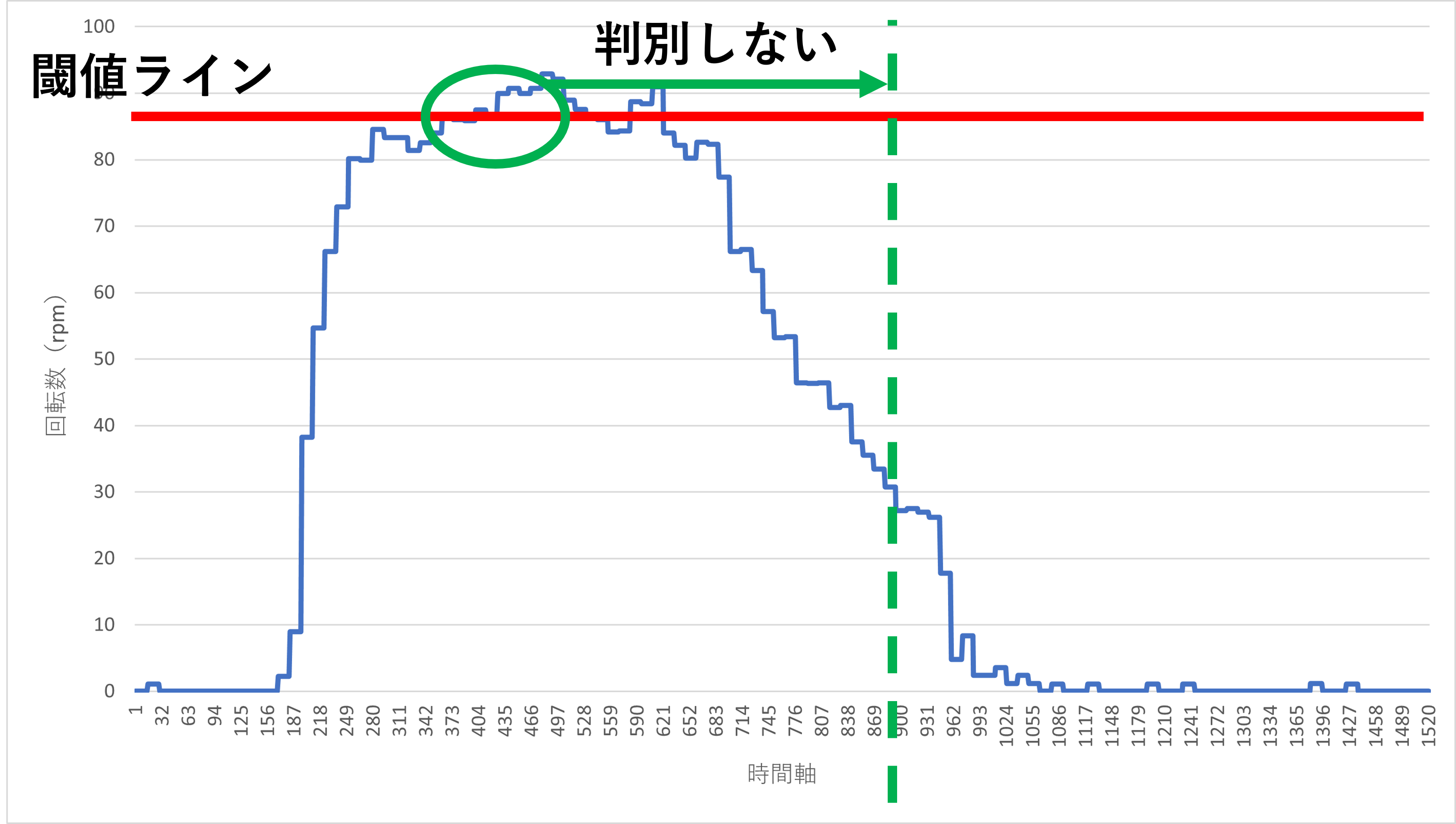
では、その処理について説明します。先ほど検出した「ピークを超えた瞬間」のforループ回数を記録します。そして、再度ピークが下から上にまたぐ状態が発生した時にそのループ回数と記録したループ回数(前回検出した際のループ回数)の差をとって、その差がある一定の値より小さければ記録しないとすれば良いです。3.4.1節のコードと併せて書くと以下のようになります。以下の例では差の条件を500としています。
if detect != pre_detect and pre_detect == 0 and (i-pre_c) > 500:
しかし、この方法には問題もあります。まず第一に判別を行わない間隔をどのように設定するかです。その為にピークの線幅をExcelで最初に大まかに確認します。大体はその線幅の半分に設定しておけば大丈夫です。また、隣り合うピークが多くある時もこの値には注意する必要があります。
このプログラムの条件が良いのは、下図のような平常値とピーク値が大きく異なり、その間隔が大きい時です。
3.5 ピーク要素数を記録する
閾値判定処理ができましたので次にその情報を記録する処理を書きます。
for処理の前にいくつか変数を用意します。それぞれの変数の目的について説明します:
-
detect変数では現在のループにおけるピーク検出の識別状態を示すものです。 -
pre_detect変数では前のループにおけるピーク検出の識別状態を示すものです。 -
peak変数は本命のピークの場所を記録する変数です。この変数では、複数のピークが存在することを想定して複数の情報を記録できるように配列としています。 -
list_c変数はpeak配列の要素情報を持っています。 -
pre_c変数はピークを識別した時のforループ回数を記録するものです。
ではコードを見ていきましょう。下記コードでは、今までの処理をすべて記載して後の操作のために一つのcheck_peak関数にまとめています。
def check_peak():
RDdata = pd.read_csv("include csv path", low_memory=False)
detect = 0 #ピーク存在有無状態識別子
pre_detect = 0 #ピーク状態遷移判別識別子
list_c = 0 #配列の要素数
pre_c = 0 #ピーク識別時のforループ回数判別子
peak = [] #ピーク場所を記録する配列
for i,value in RDdata.iterrows():
if value[0] > 65:
detect = 1
else:
detect = 0
if detect != pre_detect and pre_detect == 0 and (i-pre_c) > 500:
peak.append(1)
peak[list_c] = i
list_c += 1
pre_c = i
else:
pass
pre_detect = detect
for中の最初のif文は3.3節の処理で紹介したもので、detect変数に現ループで閾値超えを検知をした場合は1、それ以外は0を代入します(状態)。2つ目のif文条件は3.4節で説明した通りです。
2つ目のif文処理はピークの場所を記録しています。peak.append(1)はpeak配列の配列要素を1つ増やしています。参照するデータのピーク数が不明であることを想定して、データからピーク数を取得するためです。
peak[list_c] = iではpeak配列のlist_c要素に、現在のループ回数(ピークの場所)を保存します。その後、list_c変数をプラス1して、次にピークを検知した際にその情報を格納できるスペースを確保します。最後にpre_c変数に検知した際のforループの回数(変数i)を保存します。
最後にpre_detect変数にdetect変数を代入します。これは次のピークに向けて、今回のループでのピーク識別状態を保存するものです。
3.6 3章コードまとめ&仕上げ
最後に3章でのプログラム全文と後の操作のために、戻り値を設定しておきます。戻り値はピーク数を示すlist_c変数と、ピークの場所が保存されたpeak配列変数です。
def check_peak():
RDdata = pd.read_csv("include csv path", low_memory=False)
detect = 0 #ピーク存在有無状態識別子
pre_detect = 0 #ピーク状態遷移判別識別子
list_c = 0 #配列の要素数
pre_c = 0 #ピーク識別時のforループ回数判別子
peak = []
for i,value in RDdata.iterrows():
if value[0] > 65:
detect = 1
else:
detect = 0
if detect != pre_detect and pre_detect == 0 and (i-pre_c) > 500:
peak.append(1)
peak[list_c] = i
list_c += 1
pre_c = i
else:
pass
pre_detect = detect
return list_c, peak
このコードがcsvファイルから情報を引き出し、ピークを検出するための完全版です。
4 ピーク付近のグラフ化
第2のステップとしてピーク付近の領域をグラフ化します。
尚、今回使用するcsvファイル(元データ)にはデータ列が2列あり1列目がy軸、2列目がx軸データとなっています。
4.1 グラフ化内容
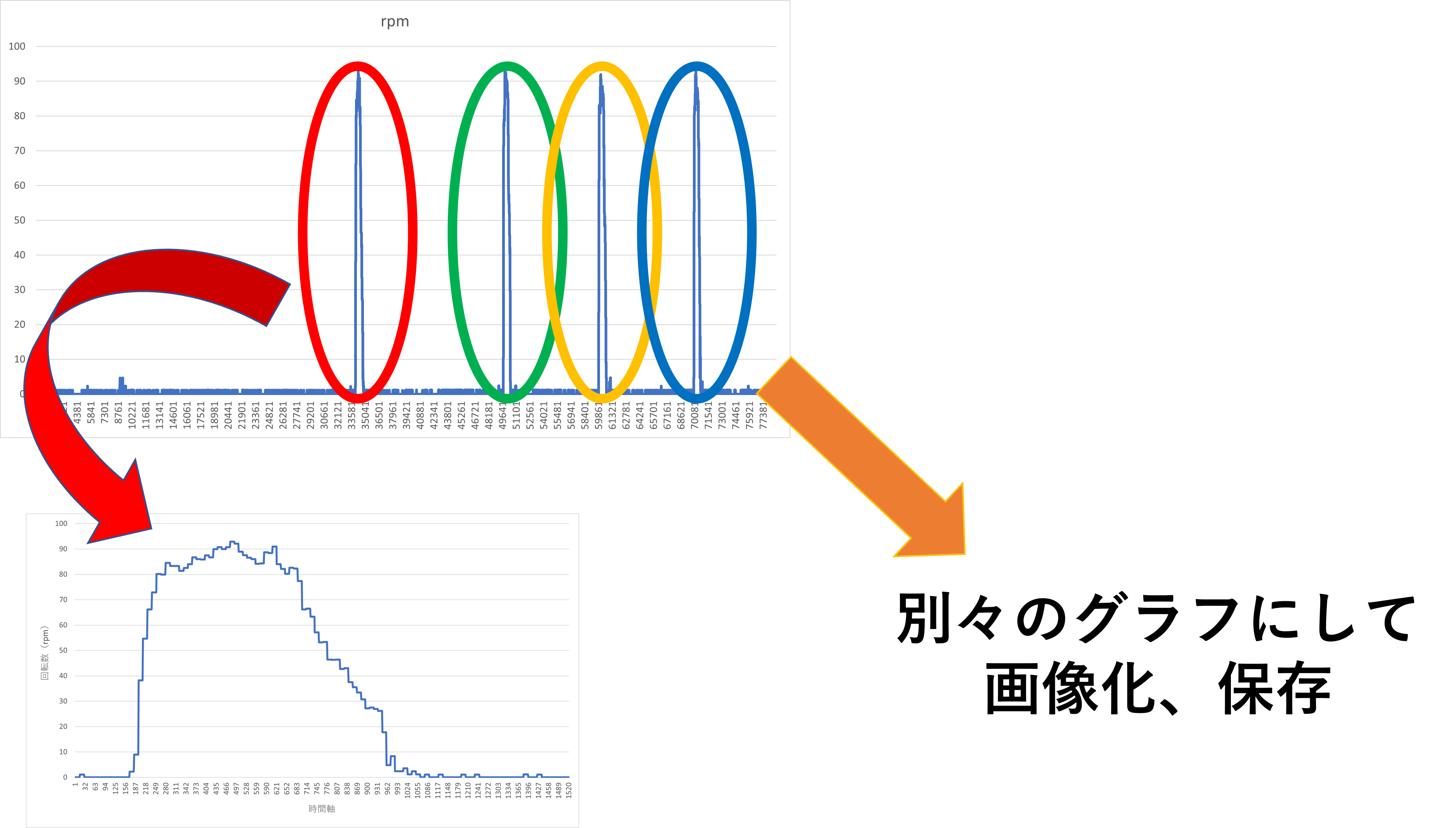
一応どの領域をグラフ化するのかを改めて説明しておきます。下図のようにピークを検知して、その付近の領域を拡大、そしてピーク毎に画像にして保存します。下図のようにピークが4つある場合は4枚のグラフ(画像)ができることになります。
4.2 コード解説
では、そのコードを書いていきましょう。
ここでは3章で取得したピークの場所の前後を切り取ってグラフ化します。本章では説明が3章のものと一部重なり説明が省けるものが多数ありますので、先にすべてのコードを載せます。
def make_dechart(peak):
RDdata = pd.read_csv("include csv path", low_memory=False)#csvを読み込む
comp = len(peak)#peak配列の要素数を調べる
data_x = []#x軸データ
data_y = []#y軸データ
Figure = []#オブジェクトにするための変数配列
ax = []#オブジェクトにしたFigure変数にグラフを描画する領域を追加する変数
for j in range(comp):#要素数分繰り返すfor文
Figure.append(1)
ax.append(1)
Figure[j], ax[j] = plt.subplots()
data_x.append(1)
data_x[j] = RDdata[RDdata.columns[1]][peak[j]-100:peak[j]+900]#x軸データ取得
data_y.append(1)
data_y[j] = RDdata[RDdata.columns[0]][peak[j]-100:peak[j]+900]#y軸データ取得
ax[j].set_xlabel(RDdata.columns[1])
ax[j].set_ylabel(RDdata.columns[0])
#ax[j].get_xaxis().get_major_formatter().set_scientific(False)
#ax[j].get_xaxis().set_major_locator(ticker.MaxNLocator(integer=True))
ax[j].plot(data_x[j],data_y[j])
Figure[j].savefig("image output path"+RDdata.columns[0]+str(j)+".png")
では、コードの変数について説明します。
- 関数の引数である
peak変数は3章の戻り値のpeak配列変数に対応しています。つまり、csvファイルのピークの場所(行数)を保持しています。 -
RDdata変数はcsvファイルの中身をデータフレーム化したものです(3章と同様)。2 -
comp変数はpeakの要素数を格納します。 -
data_xとdata_yはそれぞれx、y軸データを格納するものです。ピーク数毎に軸データは必要となりますので配列としています。 -
Figure変数はグラフオブジェクトにしたものを格納します。こちらも軸情報同様にピーク数毎に必要なため配列です。 -
ax変数はオブジェクト化したFigureの中にグラフを描画する領域をオブジェクト化したものを格納します。こちらも上記2つの変数と同様にピーク数毎に必要なため配列です。
次にfor文について説明します。
まずFigure、axの要素を1つ追加し、それらの変数をオブジェクト化してグラフを描画できるようにします。その後、グラフのx、y軸のデータを格納するdata_x、data_yの要素を追加します。
続いてdata_x、data_yにデータを代入する操作です(スライス操作)3。data_xでは元データのコラム1要素、つまりcsvファイルの2列目のデータをx軸のデータとして抽出・代入しています。列を表すものがRDdata.columns[1]で、抽出したい行(ピーク付近の行)の範囲を表すものがpeak[j]-100:peak[j]+900です。この-100と+900は環境に合わせて変化する必要があります。例ではピークを観測した時点から-100、+900までの範囲でデータを取得しています。data_y変数も同様に、元データからx軸と同じ領域(行範囲)で2列目を切り取り格納します。
data_x[j] = RDdata[RDdata.columns[1]][peak[j]-100:peak[j]+900]
data_y[j] = RDdata[RDdata.columns[0]][peak[j]-100:peak[j]+900]
上記操作は注意しておくべき点があります。情報の流れはデータフレーム型から配列型であり、配列data_xとdata_yは2次元配列となる点です。この配列の1次元目は何番目のピークであるか、2次元目はグラフにする領域の元データ要素の情報を持っています。この点については参考文献にて詳しい情報が掲載されていますので、そちらをご覧ください。本記事では本題からずれてしまうので説明は省きます。
ax[j].set_xlabelとax[j].set_ylabelについてはそれぞれx、y軸ラベルを作成しています。引数にある変数RDdata.columns[n]で列名から軸ラベルを作成しています(nは何列目かを表しています)。
続いてコメントアウトにしているax[j].get_xaxis().get_major_formatter().set_scientific(False)ではグラフ軸の数値フォーマットを設定するもので、デフォルトでは環境にもよりますが一定値を超えると指数表示になってしまいます。今回は一桁目の数値が徐々に増えるデータですので、デフォルトでは科学的表記のle~となります4。これを回避するための操作です。続く、ax[j].get_xaxis().set_major_locator(ticker.MaxNLocator(integer=True))では表示数値を整数とするものです。上記二つはいずれもx軸のみに適用されるもので、y軸にも適用したい場合はax[j].get_yaxis().と2つ目の部分(1つ目のドット後ろ)を変えたものをそれぞれ加えてください。
ax[j].plot(data_x[j],data_y[j])ではplot(x軸データ,y軸データ)の関係でグラフを描画する領域ax[j]にグラフを描画しています。
最後に保存動作のFigure[j].savefig("image output path"+RDdata.columns[0]+str(j)+".png")についてです。savefig関数の引数で画像保存先、及び保存拡張子を指定しています。引数には、保存先ディレクトリ、1列目の列名、ループ回数、最後に保存拡張子を入れています。この引数については特に指定もありませんので、読者様がご自由に決めて良いのですが注意点があります。それは異なるループにおいて保存先、保存名が重複しないようにすることです。もし重複してしまうと画像データが上書きされます。作者はその重複を回避するためにforループ回数を保存画像名に入れています。今回の例では1列目の列名をrpmとしているので、出力される画像データはrpm0.png、rpm1.png、rpm2.png、、、となっていきます。
4.3 扱うデータが小数点の場合
前節でコードの説明は終わりですが、元データに少数が含まれる場合についてはプラスで考える事項があります。それは型です、matplotlibライブラリではグラフ化するデータ型に制約があります。
整数であればエラーは発生しませんが、少数が1つでも含まれているとグラフ化する際に以下のように型エラーが発生してしまいます。
TypeError: 'value' must be an instance of str or bytes, not a float matplotlib
その為、型変換を行う必要があります。型変換を行うには以下のコードをdata_xまたはdata_y取得後からax[j].plot(data_x[j],data_y[j])までの間に入れてください。また、型変換には追加でnumpyライブラリが必要です。importを忘れずに行いましょう。
import numpy as np
`中略`
#x軸を型変換したい場合
data_x[j] = data_x[j].astype(np.float_)
#y軸を型変換したい場合
data_y[j] = data_y[j].astype(np.float_)
ほかの型でも同様にエラーが起きますので、型に合わせて適宜float_の部分を変更してください。
5 プログラム全文
では、ここまでのコード及びライブラリなどの情報を入れ込んだすべてのコードを記載します。後は、読者様の元データcsvパスと画像出力先、閾値、ピーク判定停止間隔(詳細3.4節)を環境に合わせて書き変えてください。コード全文には実際のプログラム動作を行うmain関数内に説明した関数と変数に加え、観測されたピーク数とその場所を示す出力を書いています。また、4.3節で説明した型変換についてもコメントアウトをしていますが載せています。
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import matplotlib.ticker as ticker
import pandas as pd
import numpy as np
def main():
a,peak = check_peak()
print("観測されたピークは以下の通りです")
print(a)
print("また、観測された要素数は以下の通りです")
print(peak)
make_dechart(peak)
def check_peak():
RDdata = pd.read_csv("include csv path", low_memory=False)#元データのcsvパスを指定してください
detect = 0 #ピーク存在有無状態識別子
pre_detect = 0 #ピーク状態遷移判別識別子
list_c = 0 #配列の要素数
pre_c = 0 #ピーク識別時のforループ回数判別子
peak = []
for i,value in RDdata.iterrows():
if value[0] > 65:
detect = 1
else:
detect = 0
if detect != pre_detect and pre_detect == 0 and (i-pre_c) > 500:
peak.append(1)
peak[list_c] = i
list_c += 1
pre_c = i
else:
pass
pre_detect = detect
return list_c, peak
def make_dechart(peak):
RDdata = pd.read_csv("include csv path", low_memory=False)#元データのcsvパスを指定してください
comp = len(peak)#peak配列の要素数を調べる
data_x = []#x軸データ
data_y = []#y軸データ
Figure = []#オブジェクトにするための変数配列
ax = []#オブジェクトにしたFigure変数にグラフを描画する領域を追加する変数
for j in range(comp):#要素数分繰り返すfor文
Figure.append(1)
ax.append(1)
Figure[j], ax[j] = plt.subplots()
data_x.append(1)
data_x[j] = RDdata[RDdata.columns[1]][peak[j]-100:peak[j]+900]#x軸データ取得
data_y.append(1)
data_y[j] = RDdata[RDdata.columns[0]][peak[j]-100:peak[j]+900]#y軸データ取得
##型変換操作##
#x軸を型変換したい場合
#data_x[j] = data_x[j].astype(np.float_)
#y軸を型変換したい場合
#data_y[j] = data_y[j].astype(np.float_)
ax[j].set_xlabel(RDdata.columns[1])
ax[j].set_ylabel(RDdata.columns[0])
ax[j].plot(data_x[j],data_y[j])
##x軸のメモリ表示整数化操作##
#ax[j].get_xaxis().get_major_formatter().set_scientific(False)
#ax[j].get_xaxis().set_major_locator(ticker.MaxNLocator(integer=True))
ax[j].plot(data_x[j],data_y[j])
Figure[j].savefig("image output path"+RDdata.columns[0]+str(j)+".png")#output先のcsvパス、画像化する際の拡張子を指定してください
if __name__ == "__main__":
main()
実行結果(参考)

6 理論的なお話
最後に本題よりずれて理論的なことを少しお話したいと思います、重要な項目ですのでお時間ある方はぜひ一読していただければと思います。今後のプログラミング人生にも大きく関わると思います...
pythonのmatplotlibライブラリに関することをインターネットで調べると、以下のようなコードが多く見つかると思います。
import matplotlib.pyplot as plt
`中略`
plt.plot(x,y)
plt.show()
`or`
plt.savefig(img.png)
上記のようなグラフ設定、描画、保存などをplt.**で操作を行うもので、一般的にMATLABスタイルと言われています。この方法は初心者向けの簡易操作に向いており、オブジェクトを明示的に宣言、操作することが必要ありません。しかし、今回のように細かい軸設定や一度の動作で複数のグラフを作成する際には多く問題が出ます。
現に作者も初期はこの方式で書いていました。その際、ピーク毎のグラフを探画しようとした時、複数のピークが一遍に表示されうまく描画することはできませんでした。
そこで今回のコードではオブジェクト指向スタイルを使用しました。
import matplotlib.pyplot as plt
`中略`
Figure, ax = plt.subplots()
ax.plot(x,y)
オブジェクト指向スタイルではその名の通り、グラフをオブジェクト化するFigureオブジェクトと、そのグラフ内に描画する領域をオブジェクト化するAxesオブジェクトを作成してそれらを変数のように操作する手法です。今回の例ではax[j]という領域でピーク付近をグラフ化して、領域が含まれるグラフオブジェクトFigure[j]を画像化しました。MATLABスタイルよりも細かに明示的に操作を行えます。
これらの手法について以下の記事では、
matplotlib の2つの流儀( MATLAB・オブジェクト指向スタイル)
matplotlib でグラフを作成することが難しく感じるのは、流儀の存在を知らないままプログラムを書いていて、2つのスタイルが混在して可読性が著しく低下するからだと思っています。
実際に、この両者の違いを正しく理解していないまま、無責任に紹介している書籍や記事、動画があまりにも多いです…。
と言及されています。
作者自身も初期の頃はこれらのスタイルの認識が曖昧で、さらには検索して出てきたサイト自体が2つのスタイルを混合させて書かれている事が多々あり、中々うまくグラフを描画できずにいました。そこで本記事を読んでいただいている読者様にはこれらの区別をしっかりと把握して頂きたいと思っています。上記コードは全てオブジェクト指向スタイルで書かれているので理解しやすい箇所が多いかと思います。
7 まとめ
以上で説明は終わりです。ここまで読んで頂きありがとうございました。実は作成当初ここまで長くするつもりは無く、もっと備忘録的な感じで単発記事としてコードと少しの解説、実行結果だけにしようと思っていました。ですが、書いてみると奥が深くてこんなにも盛沢山な内容となってしまいました。読者様には少し負担になってしまったかと思いますが、偏った知識ではなくしっかりとした知識を入れて今後のプログラミング人生をより良いものにできたらと思います。
また、上記コードを改変してさらに良いものにしてください。例えばグラフタイトルや凡例を付ける、第2軸を設定して複数のデータを描画するなどたくさん改良できる箇所があると思います。ぜひ、自分だけのプログラムを書いてみてください!!
この記事は今のところ連載は予定していませんが、要望とView数が多ければ応用編を出したいと思います。
※ご質問、修正要望等ございましたらお気軽にコメント欄にお書きください。
では、よいプログラミングライフを!!
参考文献
matplotlibに関する内容
配列に関する内容
データフレームに関する内容(pandasライブラリも含む)
型変換に関する内容
応用に関する内容(派生内容)
-
なぜ1点だけなのかについて補足します。今回はピークが立っている付近の領域をグラフ化するので、ピークがある領域が大まかに分かれば良いためです。その場所の正確性はここでは問題としていません。また、ピークに関する情報を多く保持しておくとコードの乱雑化、動作の低速化を招く恐れがあるため、扱う情報をできるだけ少なくする目的もあります。 ↩
-
3章でも同様に読み込んだのでそのデータを使えばよいと思われるかもしれませんが、説明する際に分かりやすく伝わると考えたため読むこむ動作を再度行いました。理解できる方は3章で読み込んだデータを引数に割り当てて、使ってみてください、こちらの方が高速化できます。 ↩
-
スライスについては参考文献「pythonのスライス」を参照してください。 ↩
-
これに対し数値が大きく、等倍に変化する状態では
+le~または-le~とオフセット表記になる場合があります。その際には**.set_scientific(False)を**.set_useOffset(False)に変更してください。詳しくは参考文献のドキュメントをご覧ください。 ↩