概要
【内容】
・Pythonの開発環境を導入する
・指定したWebサイトの情報を取得するプログラムを作成する
【想定読者】
・Python、ないしはスクレイピングに興味があるが、手が出せないでいる方
【使用データ】
弊社Webサイト:https://www.anestec.co.jp/
1.Pythonの開発環境を(手軽に)導入する
1-1 .Pythonのバージョン、どちらを選ぶか?
Pythonには2.x版と3.x版があり、文法や出力結果が異なっている。また、一部の機能において互換性を持っていない。
現在、2.x版のサポートは2020年ごろに終了しており、3.x版に対応したライブラリも数多く提供されているため、新規に導入するのであれば3.x版が強く推奨されている。
1-2.Pythonの開発環境
Pythonには用途に応じた豊富なライブラリが存在している。
ライブラリが標準搭載されているプラットフォームを利用することで、効率よく開発を進めることが出来る。
Anaconda
データサイエンスに特化したプラットフォームで、データサイエンスに適したライブラリを数多く含んでいる。Anacondaの中には、Pythonの他、Rなどのデータサイエンスに良く利用される言語のライブラリも含まれている。
Anacondaをインストールした場合、Spyderと呼ばれるPython用のIDE(Python版のEclipseのようなもの)も同時に利用可能になるため、そのままPython開発に取り掛かることが出来るようになる。
参考:Anacondaのインストール手順
2.スクレイピングを行う
2-1.そもそも、スクレイピングとは?
Webサイトに存在する文章や画像を取得する(+編集してファイルなどに出力する)技術のこと。
上記の作業自体は人力でも実施は可能である。
ただし、例えば「ある通販サイト内にある1000件の商品ページの値段を1時間ごとに出力せよ」といった作業があった場合、人間の手では高いコストがかかってしまうのは目に見えている。
スクレイピングはそういった単純作業の繰り返しに対して強い力を発揮する。
2-2.前準備
スクレイピングを使ってWeb情報を抜き出すにあたって、「対象サイトのどの部分を抜き出すのか」という内容を明白にしておく必要がある。
今回は弊社Webサイトの中の「新着情報」の情報を抜き出すプログラムとする。
Google Chromeを利用したWeb情報の調査方法
①対象のWebサイトにアクセスし、右クリック⇒検証を選択
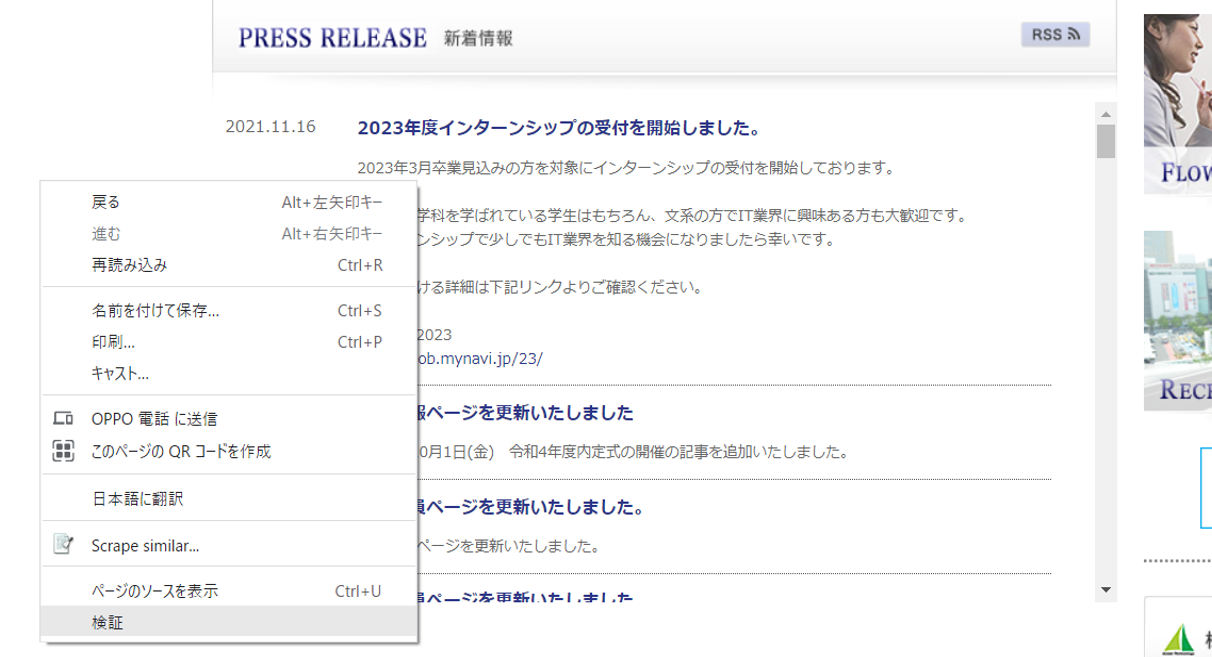
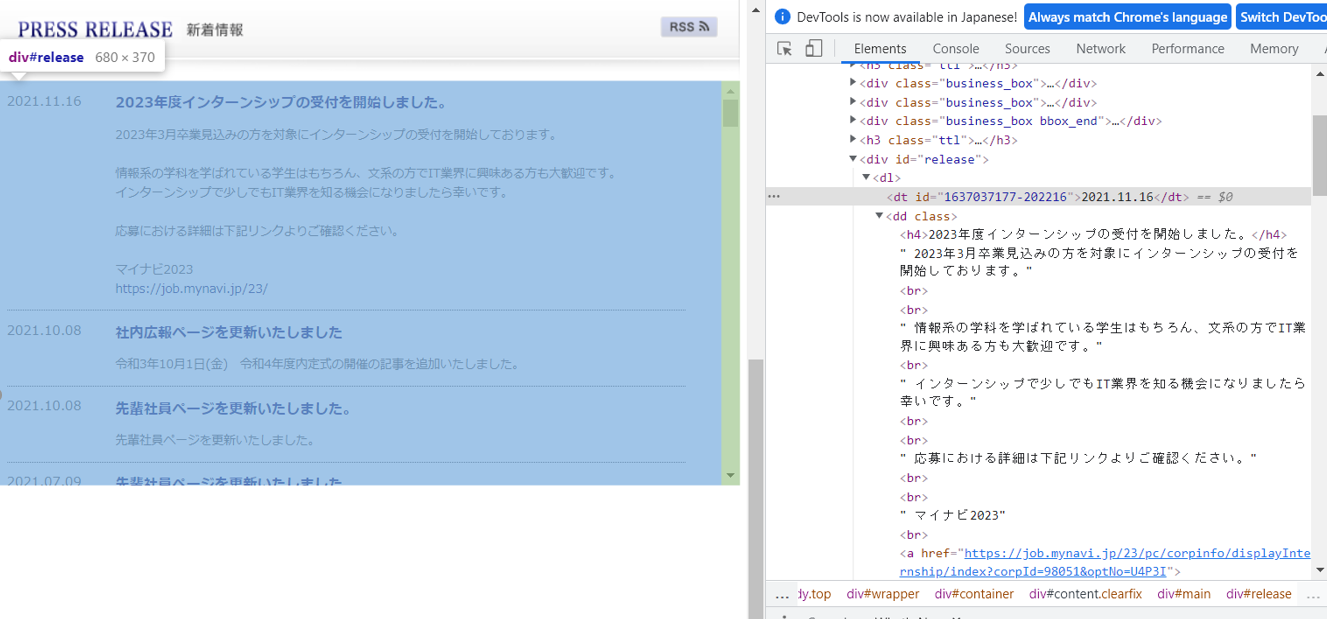
②弊社Webサイトを解析した結果。
新着情報は「div id="release"」内に存在していることが分かる。
また、内部に格納されている情報から、dtタグの中に日付の情報、ddタグの中に本文が含まれていることが分かる。
2-3.実装
先述した通り、Pythonの強みとして「用途に応じた豊富なライブラリが存在している」点が挙げられ、スクレイピングについても有益なライブラリが存在している。
今回はBeautifulSoupと呼ばれるライブラリを利用する。
Anacondaをインストールした際、BeautifulSoupも同時に設定されるので、別途取得する必要はない。
(スクレイピングの用途としてはScrapyも有名であるが、今回については割愛とする)
参考:BeautifulSoupの利用方法をまとめているサイト
ソース本体
# 特定のURLの特定エリアの情報を抜き取り、結果をCSVファイルに出力する
# HTTP通信用のPythonのライブラリ
import requests
# BeautifulSoupをインポート
from bs4 import BeautifulSoup
# csvファイルライブラリ
import csv
# スクレイピング対象のURL(Anestec)
url = "https://www.anestec.co.jp/"
# HTTP通信の結果情報
response = requests.get(url)
# BeautifulSoupを用いて整形した内容を、変数soupに格納する
soup = BeautifulSoup(response.content,"html.parser")
# findメソッドを用いてID名「release」属性の情報を取得する
release = soup.find("div",attrs = {"id":"release"})
# 一連番号を振って、行単位でリスト化する
# 想定結果が複数件ある場合、find_allメソッドを用いて全件取得する(リスト形式で返却)
index = 1
anestec_list = []
# すべて分割してlistに格納する
# 日付部分(dtタグ内の情報)を抽出
dates = release.find_all("dt")
# タイトル部分(h4タグ内の情報)の抽出
titles = release.find_all("h4")
# 本体部分(ddタグ内の情報)を抽出
entries = release.find_all("dd")
for i, entry in enumerate(entries):
# 一連番号、日付部分、タイトル部分、本体部分の順でリストに追加
# 本体部分(ddタグ)の中にタイトル部分(h4タグ)の内容が含まれている為、タイトル部分を空文字に置換してから設定
# get_textメソッドを用いると、テキスト部分のみを取得することが出来る
anestec_list.append([i+1, dates[i].get_text(), titles[i].get_text(), entry.get_text().replace(titles[i].get_text(), "", 1)])
#csvに出力する。文字コード変換でNGのものは本来であればエラーとなるが、ignoreオプションで無視している
with open("新着情報.csv", "w", encoding ="Shift-JIS",errors="ignore") as file:
writer = csv.writer(file, lineterminator ="\n")
writer.writerows(anestec_list)
2-4.スクレイピングを実行
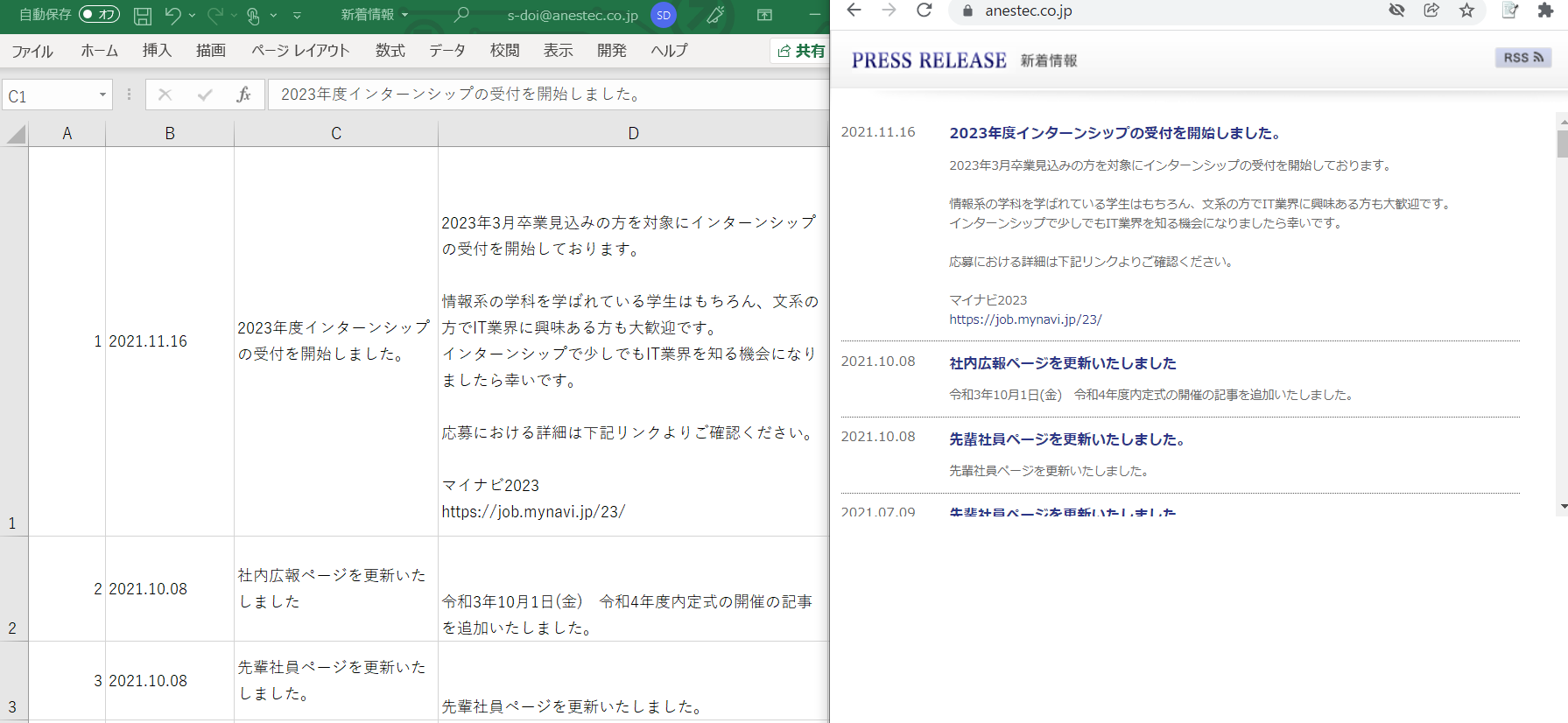
実行した「新着情報.csv」を確認。
結果は以下の通り。(左がCSVファイル、右がWebページの取得した情報)