概要
【内容】
・複数のページをスクレイピングし、情報をCSVファイルに出力する
・出力したCSVファイルをgmailに添付して送信する
・【参考】Spyderの画面について特筆すべき箇所
【想定読者】
・前回のページ内容を把握している方
【使用データ】
「現代用語の基礎知識」選 ユーキャン新語・流行大賞
https://www.jiyu.co.jp/singo/index.php
1.スクレイピングを行う
1-1.前準備
前回と同じくスクレイピングを実施する為に、対象サイトの構成を把握する必要がある。
今回はユーキャン新語・流行語大賞について、1994年(第11回)~2021年(第38回)までの情報を取得するプログラムを考える。
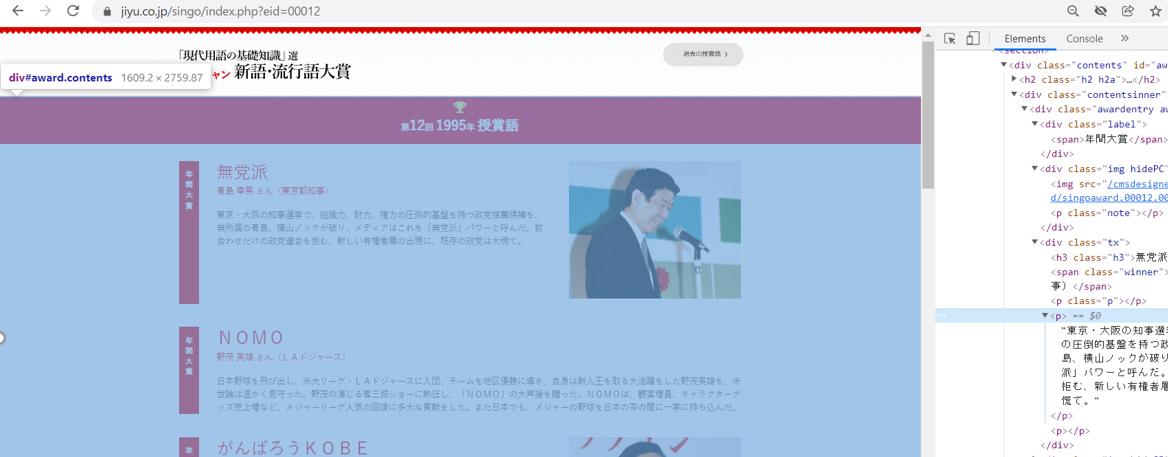
対象サイトの構成
第11回のページと、第12回のページでURL部分の差異が末尾のみであることが分かる。
また、ページ構成は両者ともに以下のフォーマットが用いられている。
本体部分は"contents"タグ内に定義されている。
・ラベル部分は"label"タグ
・流行語部分は"h3"タグ
・受賞者名部分は"winner"タグ
・解説文は"p"タグ

この情報を基に実装を行う。
1-2.実装
処理の内容についてはソース内のコメント文に記載。
◆ソース全文(長い為、折り畳み)
# 流行語大賞のページ情報を取得したものをCSVファイルへ出力し、gmail送信する
import requests
import csv
# スリープさせるメソッドSleepが含まれているライブラリ
import time
# 乱数生成を行う
import random
# メール配信に関連するライブラリ
import smtplib
from email.mime.text import MIMEText
# ファイル添付に必要になるライブラリ
import os
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
from bs4 import BeautifulSoup
# 一連番号を振って、行単位でリスト化する
enum = 0
award_list = []
# pythonには定数を定義する方法がない為、関連的に大文字とすることで表現する
START_YEAR = 1994
TERM = 28
# 完了フラグ。Trueで初期化
finish_flg = bool(1)
try:
# 1994年度から2021年度までの28年分のデータを取得
for page in range(TERM):
url = "https://www.jiyu.co.jp/singo/index.php?eid=000"+ str(page+11)
print(url)
# 最大5秒のランダム時間で待機
time.sleep(random.random()*5)
response = requests.get(url)
soup = BeautifulSoup(response.content,"html.parser")
# divタグ内のID名「contents」属性のテキストを取得する。
content_body = soup.find("div",attrs = {"class":"contents"})
# すべて分割してlistに格納する
# 賞名(ラベル)
award_names = content_body.find_all("div",attrs = {"class":"label"})
# 流行語
buzz_words = content_body.find_all("h3",attrs = {"class":"h3"})
# 受賞者名
winners = content_body.find_all("span",attrs = {"class":"winner"})
# 説明
explanations = content_body.find_all("p",attrs = {"class":"p"})
for i,award_name in enumerate(award_names):
# 一連番号、年度、賞名、流行語、受賞者名、説明の順でCSVファイルに格納
award_list.append([enum+1, str(START_YEAR+page)+"年度",award_names[i].get_text(),
buzz_words[i].get_text(), winners[i].get_text(), explanations[i].get_text()])
enum = enum + 1
# 例外発生時はスタックトレースを出力する
except Exception as e:
print(e)
# 完了フラグをfalseにする
finish_flg = bool(0)
finally:
#csvに出力する。文字コード変換でNGのものは無視している
#例外が発生したとしても、その時点の情報でcsvファイルを作る
with open("流行語大賞.csv", "w", encoding ="Shift-JIS",errors="ignore") as file:
writer = csv.writer(file, lineterminator ="\n")
writer.writerows(award_list)
# 完了フラグがfalseの場合(例外発生時)、この先に進まない
if(finish_flg):
# メール配信を実行する
# 送信元アドレス
from_address = "FromAddress@gmail.com"
# 送信先アドレス
to_address = "ToAddress@gmail.com"
# メール件名
subject = "流行語大賞について"
# 本文
text = "添付させていただきます。"
# Cドライブから添付ファイルまでのパス
filepath = "/Users/流行語大賞.csv"
filename = os.path.basename(filepath)
# メール内容を作成する(メール件名、送信元、送信先)
message = MIMEMultipart()
message["Subject"] = subject
message["From"] = from_address
message["To"] = to_address
# メール内容を作成する(メール本文)
message.attach(MIMEText(text, "html"))
# メール本文を作成する(添付ファイル)
# 添付ファイルを読み込む
with open(filepath, "rb") as file:
attach_file = MIMEApplication(file.read())
# ヘッダ部を追加する
attach_file.add_header("Content-Disposition", "attachment", filename=filename)
message.attach(attach_file)
# ログインに利用するアカウント
login_name = from_address
# gmailより発行されるアプリパスワード(16桁)
app_pass = "abcdefghabcdefgh"
# SMTPサーバ
smtp_server = "smtp.gmail.com"
# アプリパスワードを利用してログインし、メール送信を行う
sender = smtplib.SMTP_SSL(smtp_server)
sender.login(login_name,app_pass)
sender.sendmail(from_address,to_address,message.as_string())
# SMTPセッションを終了し、接続を閉じる
sender.quit()
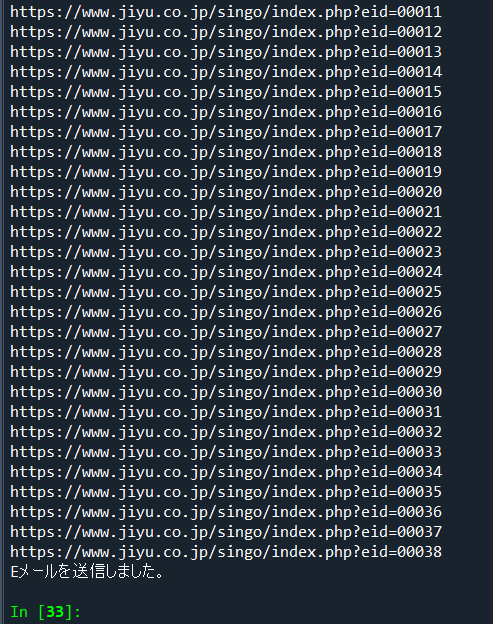
print("Eメールを送信しました。")
ポイント①:複数のページをスクレイピングし、情報をCSVファイルに出力する
ページが各回ごとに連番形式になっている為、URL内の末尾をカウントアップする仕組みを作り、繰り返し文を実装することで複数回の参照が可能になっている。
連番形式になっていない場合は、参照するURL情報をファイルに記載しておき、一行ずつ読み込ませるといった処理が必要になる。
ポイント②:出力したCSVファイルをgmailに添付して送信する
メール情報(メール件名、送信元、送信先、本文、添付ファイル)を作成した後、
アプリパスワードを利用してログインし、送信を実行する。
参考:アプリパスワードの入手方法
注意点:スクレイピングの制限について
スクレイピングは便利な技術である反面、短期間に膨大な回数アクセスを行うことで参照サイトに負荷をかける、個人的な情報を抜き取る、著作物の内容を無断で複製するといった危険もはらんでおり、白黒の線引きが不明瞭な箇所も多い。
上記のリスクを把握した上で、慎重に運用することが強く求められている。
※当ソースではアクセス毎に最大5秒程度の待機処理をかけることで、速度を抑制している。
# 最大5秒のランダム時間で待機
time.sleep(random.random()*5)
1-3.スクレイピング、メール連携を実行
①Spyderのコンソールによる出力結果。print句で指定された内容が出力されている。
②Gmailに以下の通りメールが送信される。

③実行した「流行語大賞.csv」を確認。
・結果は以下の通り。(左がCSVファイル、右がWebページの取得した情報)

・年を跨いても正しく取得されることを確認。

2.【参考】Spyderの画面について特筆すべき箇所
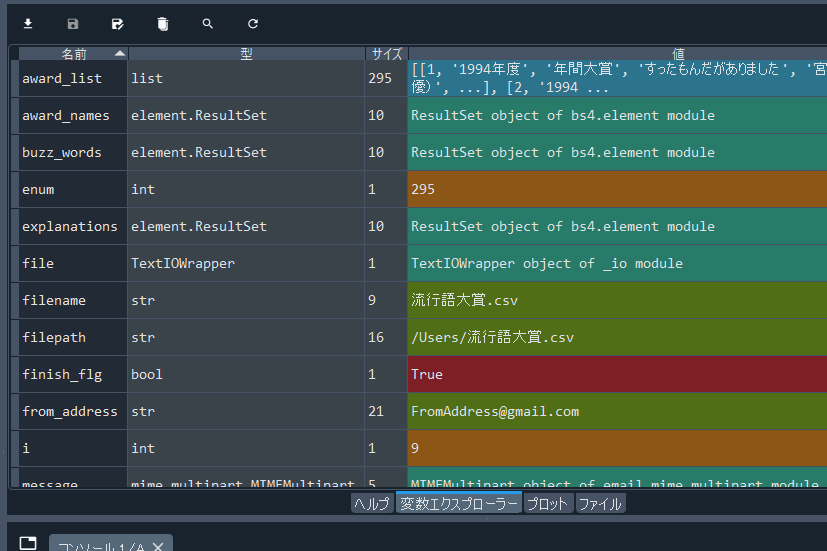
2-1.変数エクスプローラー
処理が停止(正常・異常問わず終了、またはデバッグポイントに到達)した場合について
各変数の情報を出力してくれる。
2-2.Spyderの日本語化
Anacondaをセットアップした際(デフォルト)は英語で表記となっている。
言語設定は以下手順により日本語に直すことが可能。
(ただし、後続のヘルプ画面表示など、完全に日本語には変換されない模様)
「Tools」>「Preference」>「Application」>「Advanced settings」
Languageを「日本語」にして「OK」を押す。
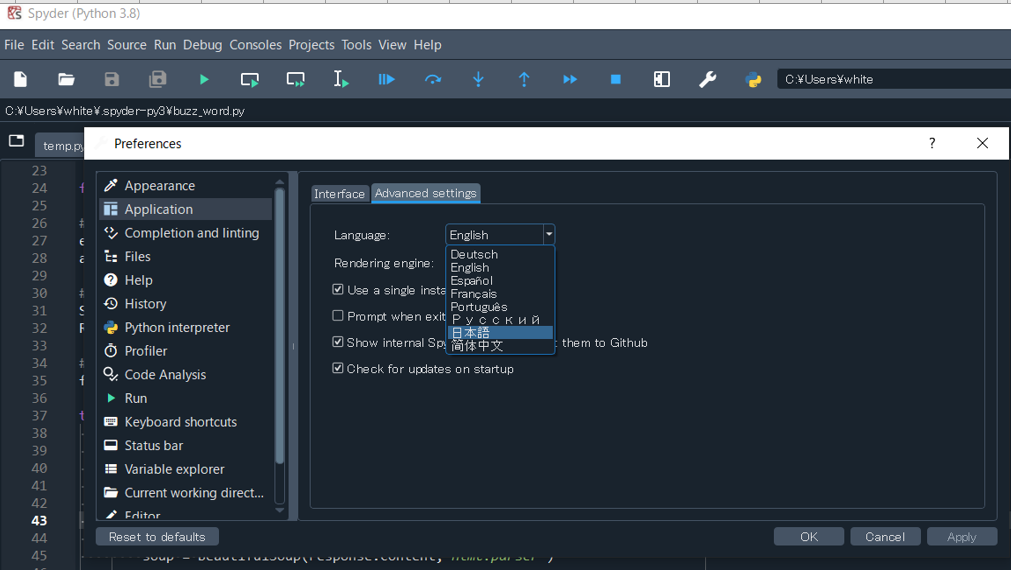
再起動後、言語が日本語になっていることを確認。

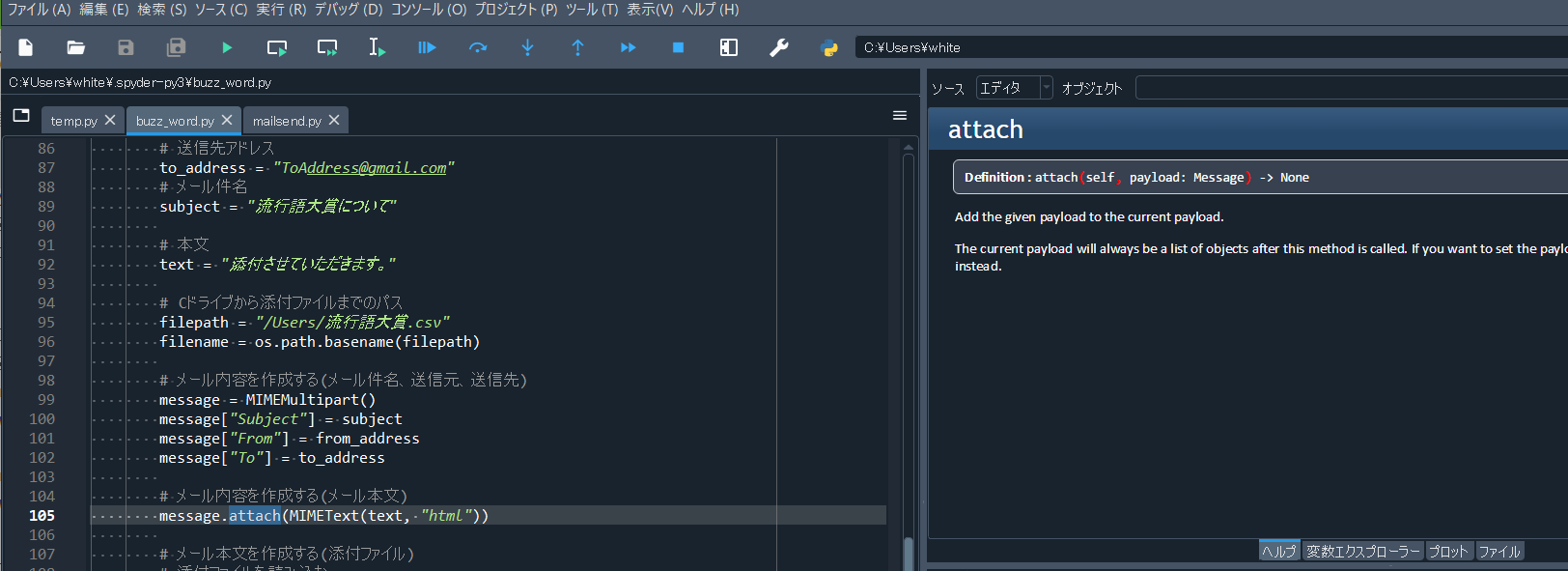
2-3.ヘルプ画面
メソッド名などクリックして選択すると、引数や戻り値、処理内容といった概要が出力される。
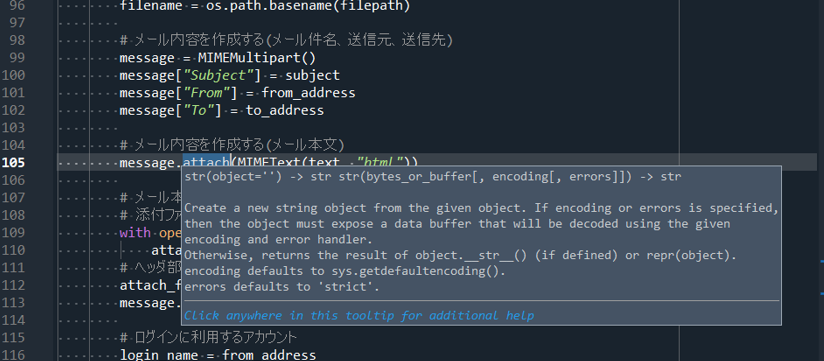
また、概要をクリックすることで右側のヘルプ画面に表示させることが出来る。