Source
Introduction
In recent years, deep learning has been used to synthesize images, attempting to bridge the appearance gap between synthetic and real images. One frequent approach is to use generative models that are trained on real life images, and hoping they would learn the characteristics and yield similarly styled outputs when given a manufactured pictures. While this method can somewhat achieve the goal, the quality of the images can be varied, especially when the input image is dissimilar to reference image.
Other approaches include the simulation of all the physical processes involved in image formation or image rendering based on real imagery of a scene, but these are either computational or time costly.
The proposed method introduced in this paper is capable of providing consistent photorealism to graphics sampled from modern games (GTA V) and can be run at interactive rates.
Algorithm
Overview
The algorithm overview can be seen in Fig. 3.
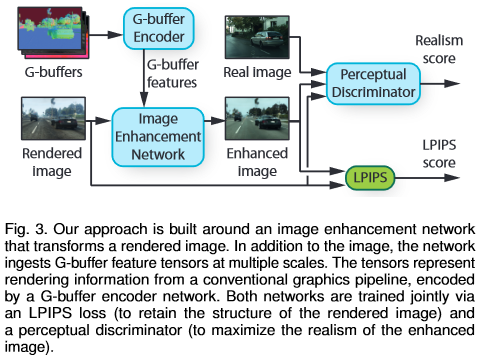
The rendering buffers (G-buffers) is produced by the game engine. They contain geometric information such as surface normals or distance to camera, material information and scene lighting.
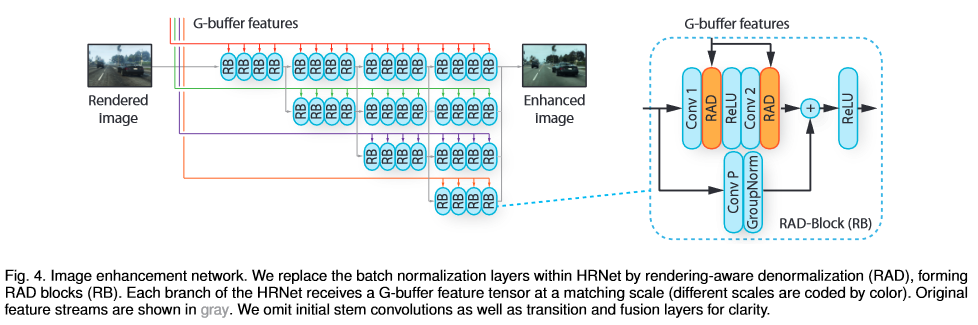
The image enhancement network (Fig. 4) uses a modified version of HRNetV2. One of the feature streams in the original HRNetV2 now operates with full resolution tensor instead of being sub-sampled to preserve finer detail. Secondly, the residual blocks are replaced by rendering-aware denormalization (RAD) modules.
The image enhancement network is trained with two objectives. First, an LPIPS loss is employed to penalizes large structural differences between the input and output images. Second, a perceptual discriminator evaluates the realism of output images by distinguishing images enhanced by the network and real photographs.
G-buffers
As mentioned earlier, the G-buffers contain scene information such as geo-metric structure (surface normals, depth), materials (shaderIDs, albedo, specular intensity, glossiness, transparency), and lighting (approximate irradiance and emission, sky, bloom).

Since different types of data exist in the G-buffer, a G-buffer encoder (Fig. 6) is used to process them.
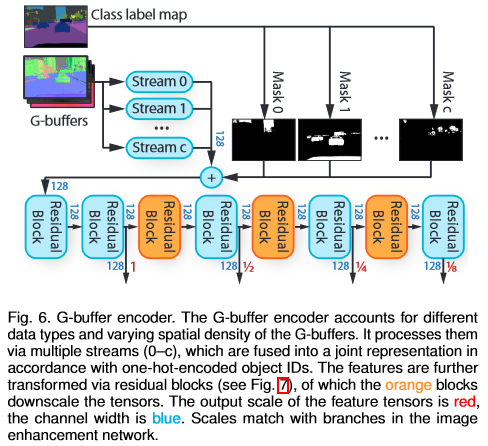
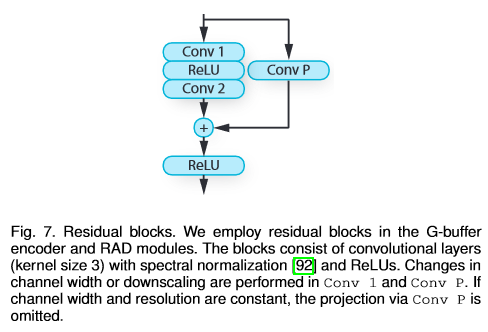
In the figure above, each stream process the same set of G-buffers, but are targeted at different object class $c$. With $f_c$ being the feature tensor from a stream for class $c$, and $m_c$ being a mask for objects of that class, then tensors are fused via $\Sigma_cm_cf_c$. Note that each stream is processed by two residual blocks (Fig. 7) before being fused.
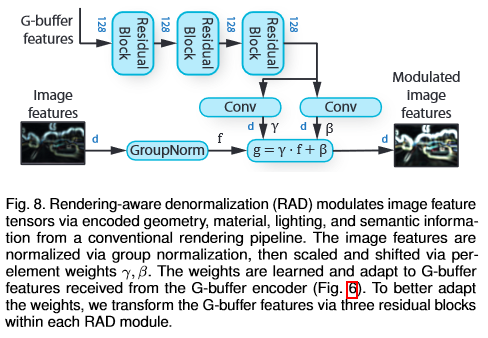
Rendering-Aware Denormalization (RAD)
The RAD modules ingests the processed G-buffer feature tensor and learns the elementwise scale and shift weights $\gamma$ and $\beta$. The weights represent the parameters of an affine transformation of normalized image features.
Perceptual discriminator
During training, realism is determined by the perceptual discriminator shown in Fig 9 below.
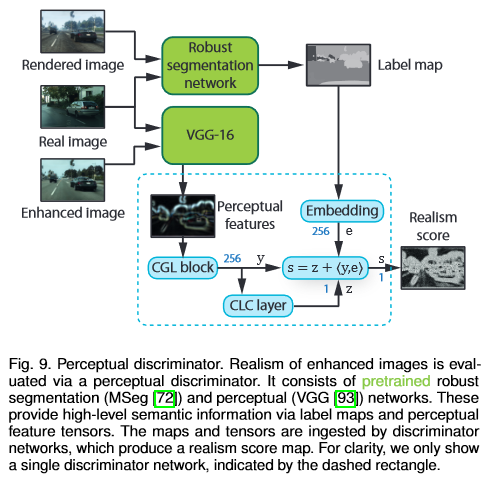
MSeg is used as the segmentation network to provide label map, and VGG-16 is utilized to for feature extraction. Both networks are pretrained and their parameters are fixed.
The discriminator networks each consist of a stack of five Convolution-GroupNorm-LeakyReLU (CGL) layers, which produces a 256-dimensional feature tensor $y$, and a Convolution-LeakyReLU-Convolution (CLC) layer, which projects the feature tensor down to a single-channel map $z$. The feature tensor $y$ is further fused with an embedding tensor $e$ via an inner product.
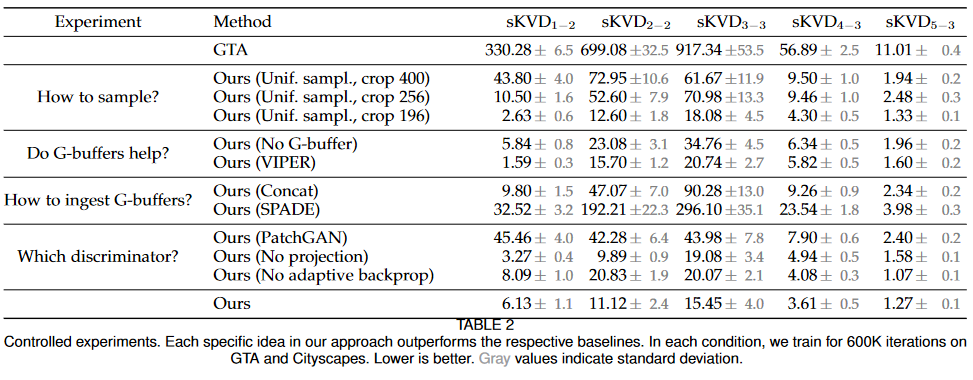
Patch reduction and sampling
Since the class distribution for the real and fake data are different, changes need to be made in order to prevent artifacts from being generated. For example, since it is much more likely to find trees at the top of an image in Cityscapes than in GTA, the generator will be tempted to place trees in sky in order to deceive the discriminator.
One modification is the reduction of crop size of an area, and the other is to match sampled patches across datasets to balance the distribution of objects presented to the discriminator. The patch similarity is calculated by:
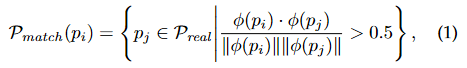
where $\phi(p_i)$ denote the feature vector computed from a VGG processed patch $p_i$.
Result
Evaluation Metrics
As Kernel Inception Distance (KID) measures distance between semantic structure, but not necessarily a difference in perceived realism, a modified version of KID is utilized for evaluation. Specifically, features from the inception network are replaced with features extracted at different layers of VGG. In addition, in order to obtain a set of semantically corresponding patches from the real and synthetic datasets, feature vector patches from both datasets are retained based on the following nearest neighbor equation:
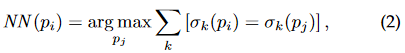
where $\sigma$ denote the vector encoding of a patch, [·]the Iverson bracket and $p_i$ is the nearest neighbor patch.
The newly proposed metric is named semantically aligned Kernel VGG Distance (sKVD), with a subscript indicating the corresponding VGG relu layer. Squared maximum mean discrepancy (MMD) is computed between the synthesized and real patches as the realism score.
Comparison to prior work

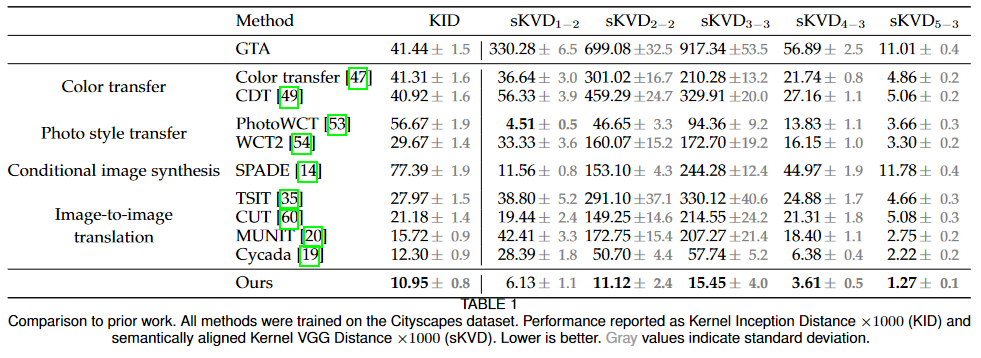
Or just look at the YouTube video.
[
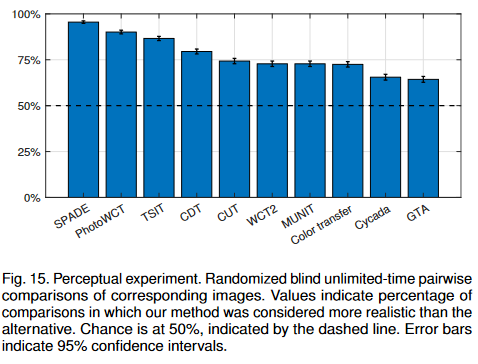
Human evaluation for realism
Images generated with the algorithm are consistently considered more realistic than all baseline methods.
Conclusion
The proposed algorithm is a huge leap in synthesizing real images, especially with its ability to reduce artifacts and maintain stability. However, inferencing using the current implementation takes half a second on a Geforce RTX 3090 GPU indicates that it is usable as a real-time filter. The requirement of G-buffers also means the result may not be so appealing for datasets that do not provide such comprehensive information.