Source
- DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
- Towards a Virtual Stuntman
Introduction
The authors present a reinforcement learning method to enables simulated characters to learn highly dynamic and acrobatic skills from reference motion clips (either motion captured or self-generated). Compared to previous research, the movement of the actor is much more fluid and natural.
Furthermore, they can also provide goal-oriented objectives, such as walking in a target direction or hitting a target while performing the trained action. On top of this, they have explored methods to develop multi-skilled agents capable of performing a rich repertoire of diverse skills.
Implementation
The task is structured as a standard reinforcement learning problem that attempts to learn the optimal policy parameter θ* by using policy gradient method. The policy gradient is estimated as:
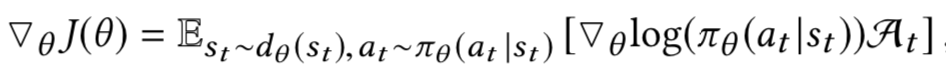
Where dθ(st) is the state distribution under the policy πθ. At is the advantage of taking an action at at a given state st

 is the total return received starting from state st at time t, while V(st) is the value function starting in st.
is the total return received starting from state st at time t, while V(st) is the value function starting in st.
The policy itself is trained using PPO (Proximal Policy Optimization), an extension of vanilla policy gradient methods (e.g. REINFORCE). It introduces the clipped surrogate objective, which restricts the amount of policy update per step (except when the action is highly probable while the reward is negative).
States
- Relative positions of each link with respect to the root, their rotations expressed in quaternions, and their linear and angular velocities.
- A phase variable φ∈[0,1]. φ=0 denotes the start of a motion, and φ=1 denotes the end.
- Goal g
for policies trained to achieve additional task objectives, such as walking in a particular direction or hitting a target.
Actions
Target orientations for PD controllers at each joint.
Network
The policy network is illustrated as:
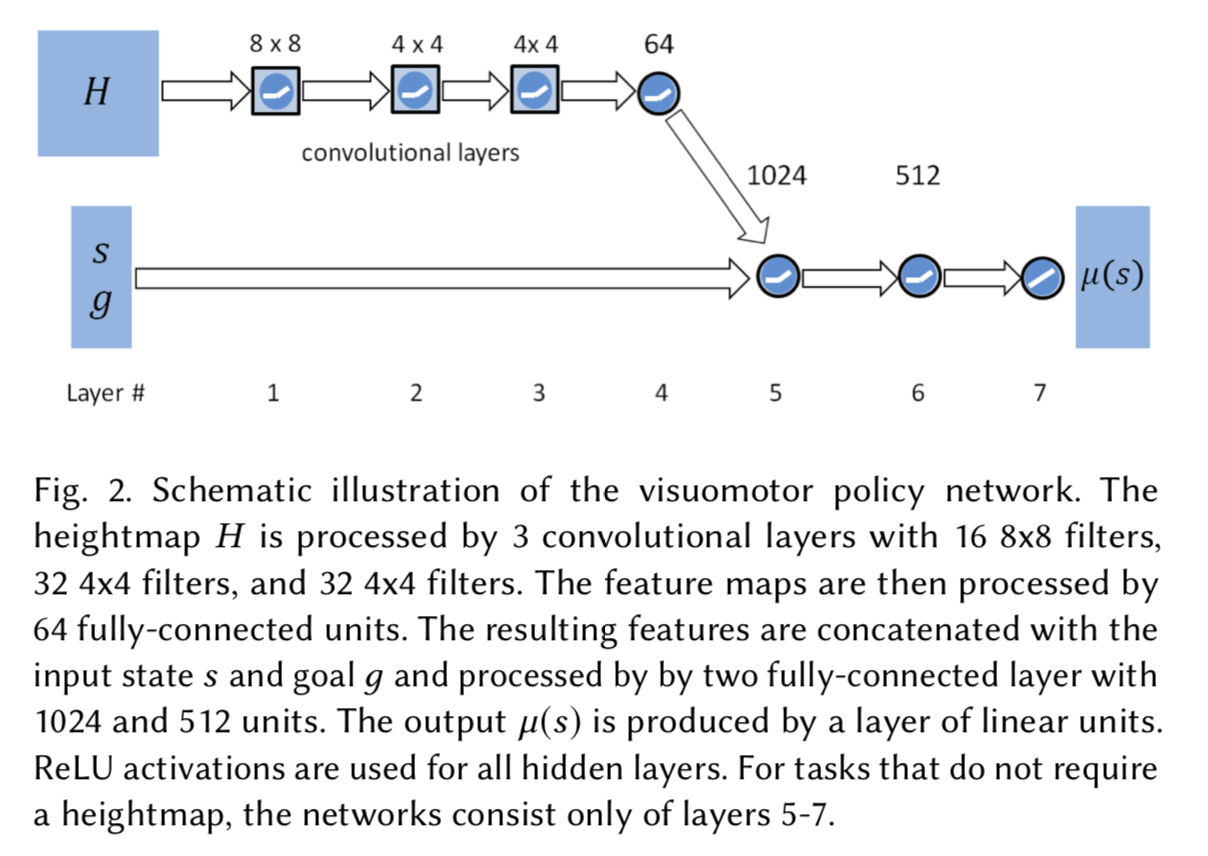
The heightmap H is sampled on a uniform grid around the character, and it is defined as a grayscale image, with black indicating minimum height and white representing maximum height.
The value function is modeled by a similar network, except the output layer consists of a single linear unit.
Reward
Reward rt at each step t is calculated by:

Where rIt is the imitation objective (how well it follows the reference motion) and rGt is the task objective (how well it completes the given task). ωI and ωG are scalar weight values.
The imitation objective rIt is further decomposed into:
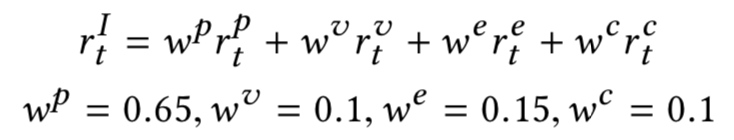
The pose reward rpt indicates how well the joint orientations are matched with the reference motion.
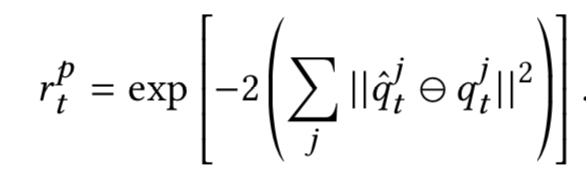
The velocity reward is computed from the difference between character and reference motion joint velocities.

The end-effector reward ret tells how good the positions of the character's hands and feet are with respect to the reference motion.

Finally, rct outputs the deviation in the the character's center-of-mass from that of the reference motion.
Training
There are two networks, one for the policy while another for the value function. The policy network is updated using PPO, while the value function is updated using TD(λ). There are two key points introduced in the paper which greatly impact the effectiveness of the training procedure; Reference State Initialization (RSI) and Early Termination (ET).
Reference State Initialization (RSI)
The initial state when learning from an episode is generally set to the state at the first step. However, for the case of mimicking a motion, the policy must learn the early phases of the motion before progressing towards later phases. This can be problematic for actions such as backflips, where learning the landing is a prerequisite for the character to receive a high return from the initial jump. If the policy cannot land successfully, jumping will result in worse returns.
(This is slightly suspicious as the reward should reflect which action is yielding a better performance as the reward is calculated at each time step?).
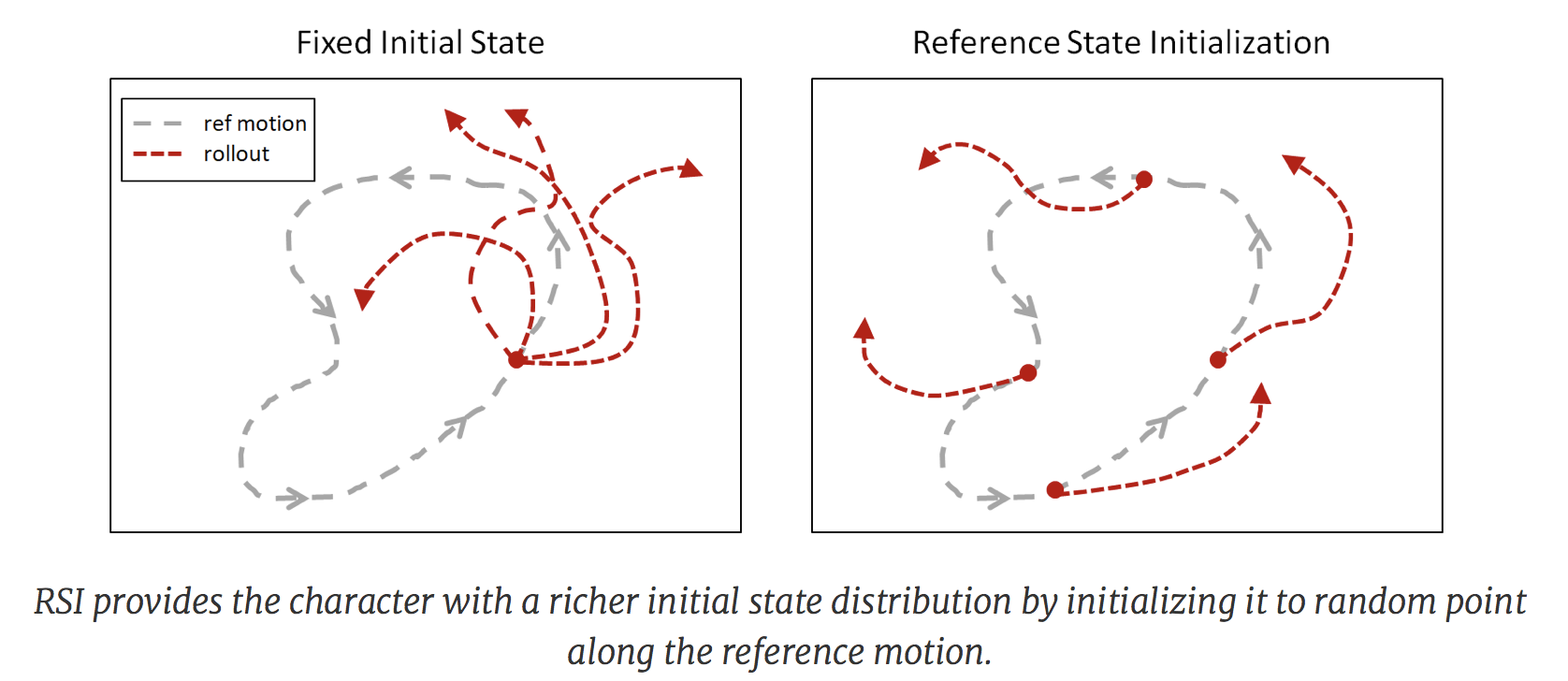
Another disadvantage of a fixed initial state is the resulting exploration challenge. As the policy receives reward retrospectively, it is unable to learn that a state is favorable until it has actually visited the state and received a high reward. For motions such as a backflip, which is very sensitive to the initial conditions at takeoff and landing, it is unlikely to execute a successful trajectory through random exploration if they always start from the ground.
The reference state initialization is therefore implemented by sampling a state in the episode length and use it as the initial state of the agent.
Early Termination (ET)
An early termination is activated when certain links, such as the torso or head, makes contact with the ground. Once this happens, the episode will be terminated immediately to prevent further training. For example, if the character has fallen to the ground while trying to learn to walk, it is almost impossible for them to get back up, and they should not learn from movements they induce while laying on the ground.

Comparison of policies trained without RSI or ET. RSI and ET can be crucial for learning more dynamics motions. Left: RSI+ET. Middle: No RSI. Right: No ET.
Result
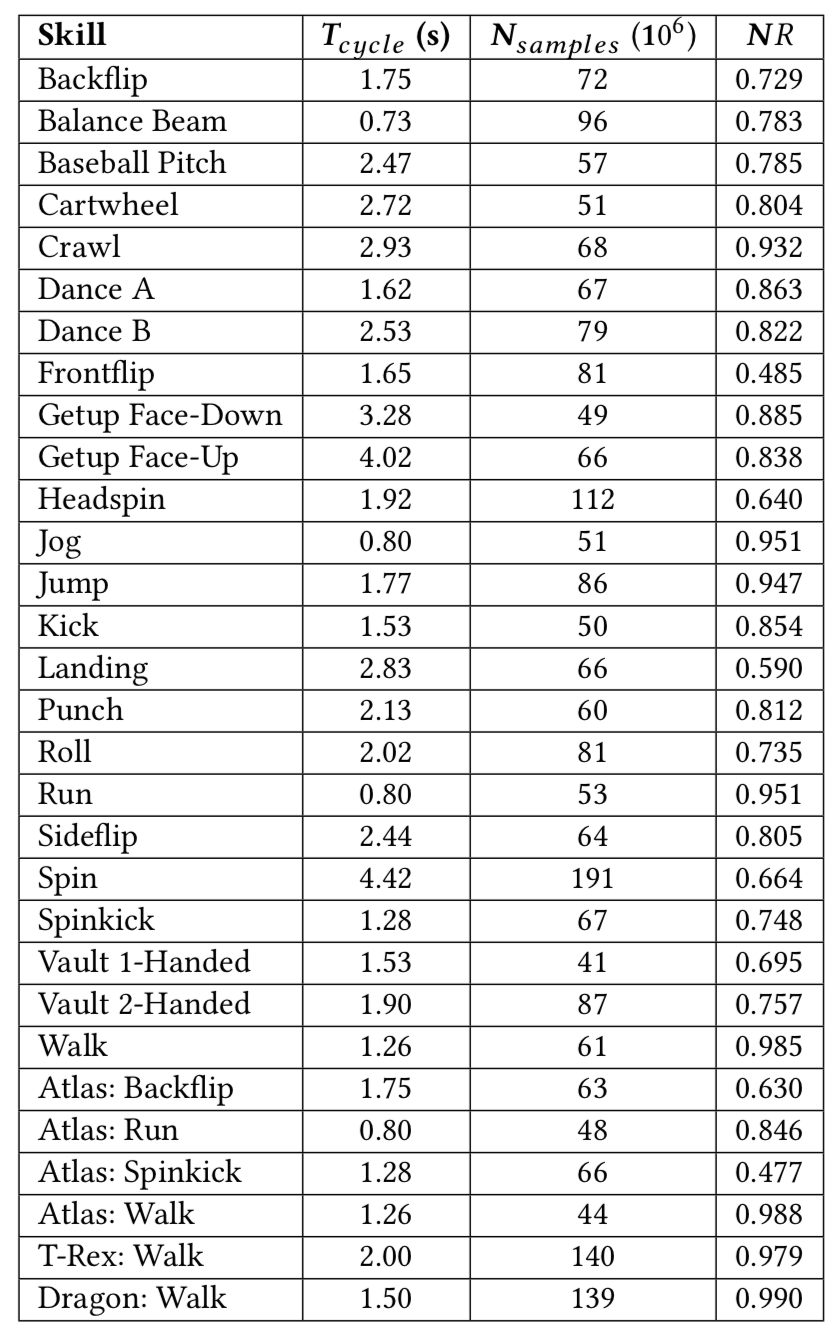

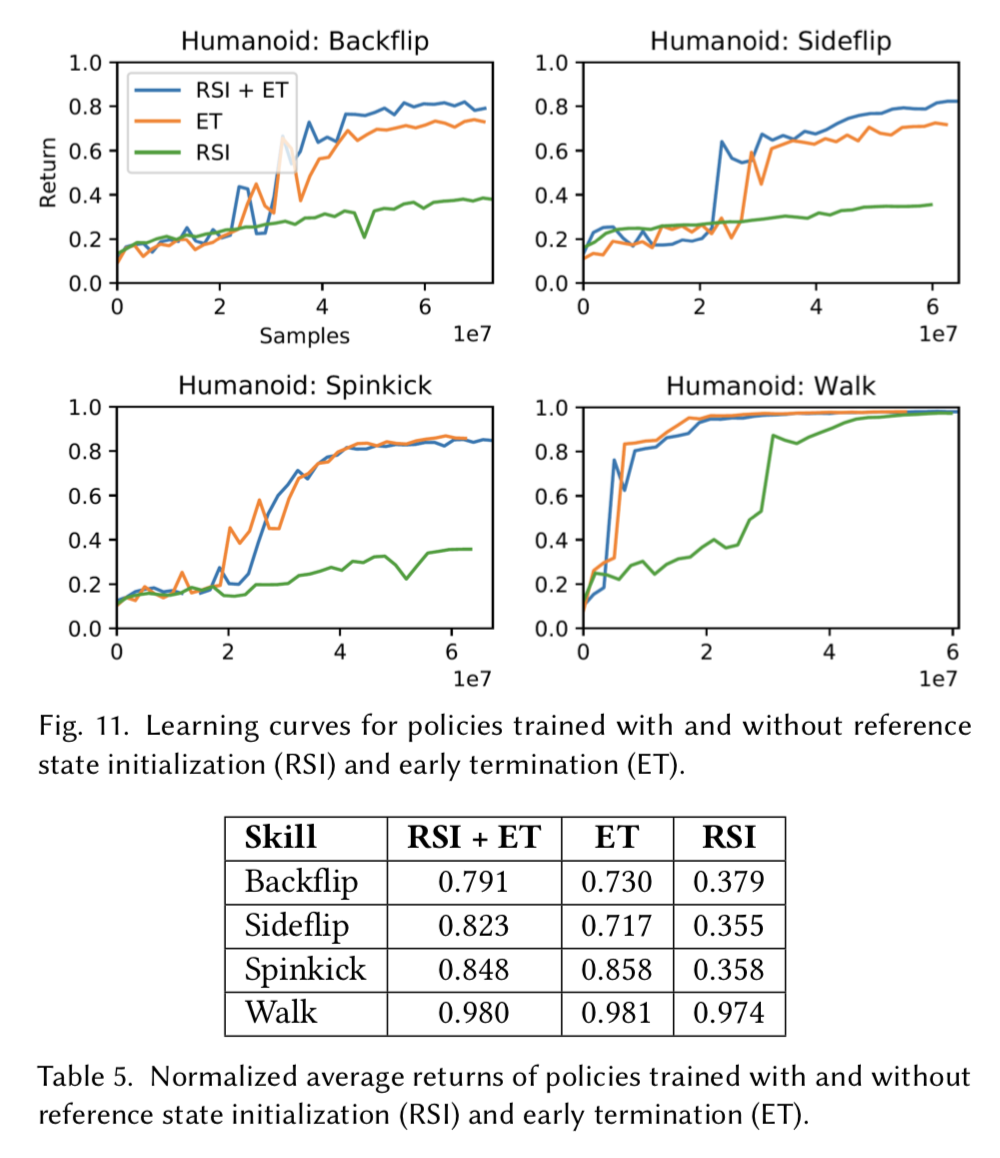
Additional Functions
Multi-Skill Integration
There are three different methods to enable the performance of multiple skills sequentially.
- Multi-Clip Reward
The policy is introduced to different reference motion clips. While the action to perform will be constant, the imitation objective will become diverse (as they are logged separately). The actual reward used to update the network is calculated as:
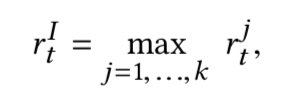 where rjt is the imitation objective with respect to the *j* th clip, and *k* is the number of motion clips.
where rjt is the imitation objective with respect to the *j* th clip, and *k* is the number of motion clips.
-
Skill Selector Policy
The policy is supplied with an one-hot vector (in additional to the original inputs), where each entry corresponds to the motion that should be executed. Note that there is no additional task objective rGt. -
Composite Policy
Divise separate policies for different skills, then integrate them together into a composite policy. The agent determines which is the best skill to perform by examining the value function of each policies under the given state. Given a set of policies and their value functions , a composite policy Π(a|s) is constructed as
, a composite policy Π(a|s) is constructed as 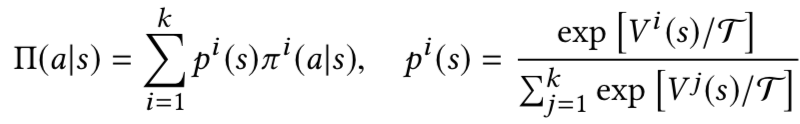
where Τ is the temperature parameter.
Varying Characters
Policy trained on one particular type of humanoid can also be used to perform motions on another humanoid models with vastly different mass distribution and actuators. It is also possible to train policy for quadrupedal models such as dinosaur and cheetah.

Task Goals
The policies can be trained to perform tasks while preserving the style prescribed by the reference motions. The tasks demonstrated include following a target direction, striking a target, throwing a ball at a target and and terrain traversal. These exercises are implemented by providing additional input goal gt and modifying the task objective rGt accordingly.
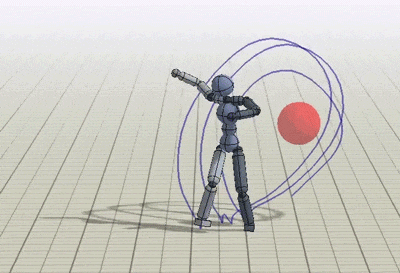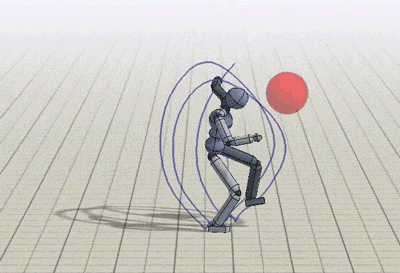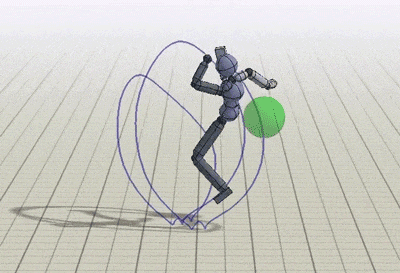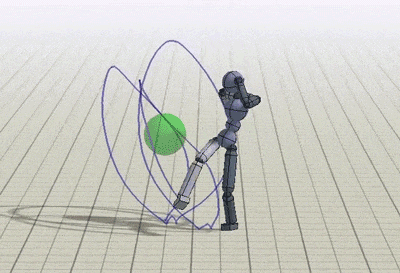

Conclusion
- RSI is probably applicable for a wide range of tasks. It is especially useful for problems that only merit one final reward at the end of the episode.
- ET has been employed prevalently already, the paper merely solidifies the assumption of their effectiveness with evaluated results.
- It is uncertain how many motions can be learnt by a single policy.
- The imitation reward has parameters that are shared amongst different motions. Perhaps there are particular values that will be more effective for certain actions? There could even be correlations between the parameter values and the genre of the motion.