皆さん、グラフデータベースは利用していますか?
この記事ではグラフデータベースを触ったことがない人向けにグラフデータベースの基本的な使い方を説明していきます。
この記事はDiverse Advent Calendar 2019の11日目です。
Diverseではマッチングアプリのレコメンドにグラフデータベースを利用しています。
グラフデータベースとは?
グラフデータベースは名前の通りグラフを扱うデータベースです。よく使われているリレーショナルデータベースは表構造を扱うデータベースと言えます。
リレーショナルデータベースは、複数の表構造の関係を扱えますが、実際に関係を扱うのは難しいことが多いです。関係を表すために適切なスキーマ設計が必要になり、クエリは難しくなりがちです。また、表を結合するにはコストがかかります。
グラフデータベースは、ホワイトボードに図を書く感覚でデータを扱えることが利点です。繋がりのあるデータを直感的に操作できます。逆に繋がりのないデータを扱うことには向いていません。
グラフのデータモデル
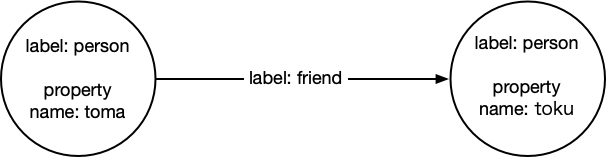
一般的によく使われているのはプロパティグラフで、プロパティグラフは以下の特徴があります。
- グラフにはノード(頂点)とエッジ(辺)があります
- ノードにはラベルとプロパティ(キーと値のペア)があります
- エッジにはラベルと方向があり開始ノードと終了ノードがあります。
- エッジにももちろんプロパティを含めることができます。
実際にグラフデータベースを使ってみよう
グラフデータベースを理解するには実際に使ってみるのが早いです。
Dockerを利用するため、事前にDockerのインストールが必要です。
グラフデータベースを使うための準備
サンプルデータをクローンする
実際にグラフからデータを引いてみるのが分かりやすいため、サンプルデータをクローンします。
こちらは、PRACTICAL GREMLIN: An Apache TinkerPop Tutorialで利用されている航空路のデータです。
git clone https://github.com/krlawrence/graph.git
グラフストアを起動し、サンプルデータをロードする
Dockerでグラフデータベースを起動し、サンプルデータをロードします。
Dockerイメージは、tinkerpop/gremlin-consoleを利用します。
Gremlin Consoleには、TinkerGraphと呼ばれるオンメモリのグラフストアが付属しています。
cd graph/sample-data
docker run -it --rm -v `pwd`:/mydata tinkerpop/gremlin-console
:load /mydata/load-air-routes-graph.groovy
グラフを探索する
Gremlin
リレーショナルデータベースで使われるSQLの様に、グラフデータベースのためのクエリ言語はいくつかあります。
この記事では、Gremlinを利用します。Gremlinでは、メソッドチェーンのような記述でグラフを辿ります。
グラフを辿る
Gremlinでは、クエリは基本的にgから開始します。これはグラフにアクセスするためのトラバーサルオブジェクトと呼ばれるものです。
このトラバーサルオブジェクトは自分で好きな変数に割り当てることができますが、gという変数にバインドすることが多いです。サンプルデータをロードした時点で既にgにバインドされています。
はじめてのクエリ
ノードの取得
サンプルデータの航空路のデータを辿っていきましょう。
まずはじめにグラフの全てのノード(頂点)を取得してみます
gremlin> g.V()
==>v[0]
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
==>v[7]
==>v[8]
==>v[9]
...
当然ながら大量のノードが返されます。絞り込んで取得してみましょう。
何件あるんでしょうか?
gremlin> g.V().count()
==>3619
ノードはラベルで絞らないと、空港以外のノードも返ってくるので空港(airport)のノードだけの件数を数えてみます。
hasLabelでラベルで絞り込むことができます。
gremlin> g.V().hasLabel('airport').count()
==>3374
羽田空港の空港コード(HND)を持つを空港を探してみます。
hasでプロパティのキーと値を渡すことで絞り込むことができます。
gremlin> g.V().hasLabel('airport').has('code','HND')
==>v[105]
1つだけのノードが取得できました!
羽田空港のノードがどのようなプロパティを持っているか見てみましょう。
gremlin> g.V().hasLabel('airport').has('code','HND').valueMap()
==>[country:[JP],code:[HND],longest:[9840],city:[Tokyo],elev:[35],icao:[RJTT],lon:[139.779998779297],type:[airport],region:[JP-13],runways:[4],lat:[35.5522994995117],desc:[Tokyo Haneda International Airport]]
ノードを辿る
outを利用して、出ていく方向の頂点やエッジを調べられます。
空港と空港はrouteというラベルのエッジで結ばれているので、羽田空港から出ていくルートの数を数えてみます。
gremlin> g.V().hasLabel('airport').has('code','HND').out('route').count()
==>82
82のルートがあることがわかります。
実際にどの空港へ行くのか見てみましょう。プロパティの値を取得するには、valuesを利用します。キー名を渡すことで特定のプロパティの値を取得できます。
gremlin> g.V().hasLabel('airport').has('code','HND').out('route').values('code')
==>KMQ
==>YGJ
==>MYJ
==>TAK
==>OKA
==>TSA
...
羽田空港から乗り換えを1回使うことを許容すると、どれだけの数の空港に行けるでしょうか?
gremlin> g.V().hasLabel('airport').has('code','HND').out('route').out('route').count()
==>4924
登録されている空港の数より多い数が返ってきました。
これは重複が除去されていないためです。
重複を除去するにはdedupを使います。
gremlin> g.V().hasLabel('airport').has('code','HND').out('route').out('route').dedup().count()
==>1247
さらに乗り換えを1回使うが、直行で行けるルートを除去してみます。
aggregateで一時的にコレクションを保存して、whereで除去します。
gremlin> g.V().hasLabel('airport').has('code','HND').out('route').aggregate('nonstop').
......1> out('route').where(without('nonstop')).dedup().count()
==>1178
羽田空港(HND)から出て成田空港(NRT)に戻ってくるルートはどのようなルートがあるでしょうか?
gremlin> g.V().hasLabel('airport').has('code','HND').out('route').out('route').has('code', 'NRT').path().by('code')
==>[HND,KMQ,NRT]
==>[HND,YGJ,NRT]
==>[HND,MYJ,NRT]
==>[HND,TAK,NRT]
==>[HND,OKA,NRT]
==>[HND,HKD,NRT]
==>[HND,JFK,NRT]
==>[HND,LAX,NRT]
==>[HND,ORD,NRT]
==>[HND,SEA,NRT]
...
小松空港(KMQ)などを経由するルートが一覧で返ってきました。
さらにノードを辿る
日本とアメリカを結ぶ空港のルートを取ってみます。
gremlin> g.V().hasLabel('airport').has('country','JP').out('route').has('country','US').path().by('code')
==>[NRT,PDX]
==>[NRT,KOA]
==>[NRT,ATL]
==>[NRT,BOS]
==>[NRT,DFW]
==>[NRT,IAD]
==>[NRT,IAH]
==>[NRT,JFK]
==>[NRT,LAX]
==>[NRT,ORD]
==>[NRT,SEA]
==>[NRT,SFO]
==>[NRT,SJC]
==>[NRT,SAN]
==>[NRT,DEN]
==>[NRT,EWR]
==>[NRT,HNL]
==>[NRT,DTW]
==>[HND,JFK]
==>[HND,LAX]
==>[HND,MSP]
==>[HND,ORD]
==>[HND,SEA]
==>[HND,SFO]
==>[HND,HNL]
==>[FUK,HNL]
==>[KIX,JFK]
==>[KIX,LAX]
==>[KIX,SFO]
==>[KIX,HNL]
==>[CTS,HNL]
==>[NGO,HNL]
==>[NGO,DTW]
ほとんどが羽田発と成田発です。
分かりやすいようにカウントしてみましょう。
どこでグルーピングするか分かるように途中でasで名前を付けて参照する必要があります。
gremlin> g.V().hasLabel('airport').has('country','JP').as('jp').
......1> out('route').has('country','US').select('jp').groupCount().by('code')
==>[NRT:18,CTS:1,NGO:2,KIX:4,FUK:1,HND:7]
アメリカへ行くルートは成田空港発が18つ、羽田空港発が7つあることが分かりました。
日本とアメリカの最長ルートはどこでしょうか?
各エッジには距離があるためそれを参照して調べてみましょう
エッジに注目したいので、outではなくoutEとinVを使い、orderで並び替えてみます。
gremlin> g.V().hasLabel('airport').has('country','JP').outE('route').
......1> order().by('dist',decr).inV().has('country','US').
......2> path().by('code').by('dist')
==>[KIX,6926,JFK]
==>[NRT,6832,ATL]
==>[HND,6753,JFK]
==>[NRT,6734,IAD]
==>[NRT,6725,JFK]
==>[NRT,6712,EWR]
...
関西国際空港(KIX)とジョン・F・ケネディ国際空港(JFK)を結ぶ6926マイルが最長であることがわかります。
グラフデータベースの得意なこと、苦手なこと
実際にグラフデータベースを触ってみると、繋がりのあるデータを容易に引くことが出来ると分かります。
しかしながら、グラフデータベースだからといって何でも引くことが出来るわけではありません。グラフデータベースでも参照するノードやエッジ数が増えればレスポンスは悪化します。
例えば、数百万フォロワーいる有名人が存在するソーシャルグラフの場合、その有名人をフォローしているという条件から始めてトラバーサルしていくと、数百万エッジを参照することになるので即時に結果を返すことは難しくなります。
効率的なクエリを書くことはもちろん重要ですが、システムとして利用する予定の一般的なクエリを効率的に捌けるようにグラフを配置する必要があります。
また、グラフに全てのデータを保存する必要はなく、他のデータベースシステムと組み合わせて適材適所で利用することが重要です。
データとして関係性を扱っているけど、MySQLでJOINするのが辛くなってきた方はぜひ一度グラフデータベースを利用してみてください。
参考文献と参考文献のおすすめ文
-
PRACTICAL GREMLIN: An Apache TinkerPop Tutorial
- もっとGremlinで色々試してみたい方にオススメのTutorialです
-
O'Reilly Japan - グラフデータベース
- 利用しているクエリ言語は違いますが、グラフデータベースについて完結に説明していきます
-
TinkerPop Documentation
- 網羅的なドキュメントです