初めてKaggleのコンペに参加したは良いものの、何をすればいいか全くわからないまま終わってしまったので、(今更ながら)復習がてら簡単にまとめてみました。
タスク
https://www.kaggle.com/competitions/kaggle-llm-science-exam/overview
GPT3.5によって生成された科学に関する多肢選択問題を解くタスク。具体的には、問題文テキストpromptと選択肢テキストA,B,C,D,Eが与えられ、この中で最も答えである可能性が高い順に3つの選択肢を出力する。Kaggle環境で実行するため、GPUや計算時間の制限がある点に注意。
スターターノートブックを見る
まず、二つのノートブックがピン止めされているので、簡単に調べてみる。
https://www.kaggle.com/code/wlifferth/starter-notebook-ranked-predictions-with-bert
https://www.kaggle.com/code/inversion/science-exam-simple-approach-w-model-hub
前者は、各選択肢の先頭に問題文を連結させmultiple choice head付きのBERTモデルに入れることで、各選択肢の正解である確率を出力させるように学習・推論するという形式をとっている。
prompt + A
prompt + B
prompt + C -> model -> prob A,B,C,D,E
prompt + D
prompt + E
一方で後者は、"問題文に対して正しいと考えられる順に選択肢を並べてください"という文章の後に問題文とすべての選択肢を連結させFLAN-T5-baseテキスト生成モデルに入れて、解答テキストを出力させるという形式をとっている(学習は行わない)。ただしLLMは必ずしも正しくテキスト出力しないので、簡単な後処理を追加している。
preamble + prompt + A,B,C,D,E -> model -> answer text
どちらもスコアは0.5程度となっている。前者に関しては訓練データの拡張やモデルをDeBERTav3という新しいものに変更したノートブックがあるがそれでもスコアは0.7程(以下のリンク参照)。筆者はこのコードから、モデルやハイパラを変えてみたりアンサンブルをとってみたり訓練データ数を増やしたりしたものの、あまり大きな精度向上にはつながらなかった。
https://www.kaggle.com/code/radek1/new-dataset-deberta-v3-large-training
一位の解説を読んでみる
https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446422
(一位の方による解説)

https://blog.gopenai.com/enrich-llms-with-retrieval-augmented-generation-rag-17b82a96b6f0
RAG(retrieval augmented generation)と呼ばれる、外部の知識ベース(wikipedia等)から関連文章を抽出してコンテキストとしてLLMに渡す手法が強力。具体的には、質問文と選択肢に類似した記事の内容を抽出し、質問文・選択肢に付け加える形でLLMに入れる。一位のチームは、MTEBと呼ばれるテキスト埋め込みベンチマークのリーダーボードで複数の上位のモデルを試している。
https://huggingface.co/spaces/mteb/leaderboard

バックボーンには微調整された7B,13BサイズのLLM(llama等)をアンサンブルしたものを用いており、以下のようなフローで学習・推論が行われている。
- コンテキストと質問をバックボーンに通してpast_key_values(内部ステート)を保存する。
- past_key_valuesと5つの選択肢それぞれをバックボーンに通す。
- 次トークン予測として全語彙に対するロジットが出力されるので、簡単な分類ヘッドを取り付けてこの答えが正しいかを示す確信度を予測するよう学習する。
最終的には0.93以上のスコアをたたき出していた。
他のノートブックでは70BサイズのLLMを用いていたケースもあったらしい
https://www.kaggle.com/code/simjeg/platypus2-70b-with-wikipedia-rag
近年のLLMに関するリンク集
LLMに関する論文等の情報がまとまってるレポジトリ
https://github.com/Hannibal046/Awesome-LLM
2023年時点におけるLLMの歴史
DeBertaやFlan-T5,Llamaがどの系列なのかがわかりやすく可視化
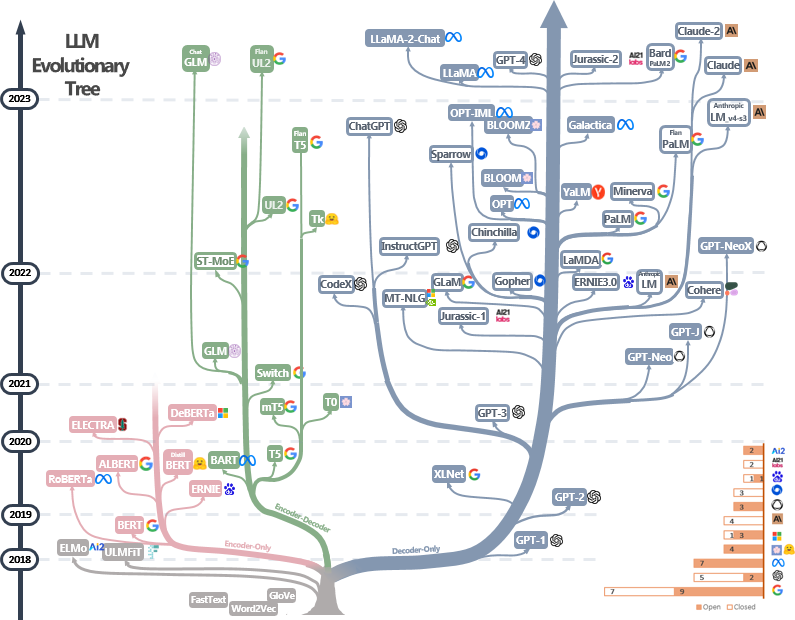
https://github.com/Mooler0410/LLMsPracticalGuide/blob/main/imgs/tree.png
(LLMの名前の由来)
https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/445521
感想
自分はNLP初心者なのもありほぼ公開コードのコピペ+α程度のことしかできなかったので、Kaggler凄いの気持ちになった。あと、NLPのコーディングとLLMのお気持ちが少しわかった気がします...
参考文献